基于决策树的简单验证码识别
qwertyuiop1822 人气:4原理
核心思想:相似的输入必会产生相似的输出。
原理:首先从训练样本矩阵中选择第一个特征进行划分,使每个子表中该特征的值全部相同(比如第一个特征是男女,则可以划分出两个子表,男表和女表),然后再在每个子表中选择下一个特征按照同样的规则继续划分更小的子表(比如第二个特征是年龄,我可以划分成三个子表(当然根据情况的不同而不同),小于18,大于18小于60,大于60,则在男女表中分别又有三个子表,每个子表下的特征值都相同),不断重复直到所有的特征全部使用完为止,此时便得到叶级子表,其中所有样本的特征值全部相同。
解释:决策树是一种分类方法,用于对样本的特征分类。而分类完成之后,得到的结果是同一类(或者称为表)的所有特征基本相同,然后根据某一类的所有样本通过平均(回归)或者投票(分类)得到一个输出。那么,当有新的待预测样本需要预测输出时,我只需知道样本属于哪个类(表)。
工程优化(剪枝):不必用尽所有的特征,叶级子表中允许混杂不同的特征值,以此降低决策树的层数,在精度牺牲可接受的前提下,提高模型的性能。通常情况下,可以优先选择使信息熵减少量最大的特征作为划分子表的依据。(通俗的讲就是有些特征值并不区分,比如第一个特征是男女,我并不分成两个表,而是放在一个表里,这种情况一般是男女这个特征对输出的影响不大),如何区分有用特征和无用特征或者说影响不大的特征呢?通过信息熵或基尼指数来区分。也可以用PCA和ICA等方法对特征先进行降维操作。
sklearn api
class sklearn.tree.DecisionTreeClassifier()
参数
- criterion:选值{“gini”, “entropy”},即基尼指数和信息熵,默认'gini'
- splitter: 选值{'best', 'random'}, 默认'best',random是为了防止过拟合
- max_depth: 树的最大深度,如果不给定则会用进所有特征构建树,或者满足参数min_samples_split时停止
- min_samples_split:节点拆分的最小样本数,可以是int和float,float表示 ceil(min_samples_split * n_samples), 即该小数为总样本的占比
- min_samples_leaf:每个节点的最小样本数,可以是int和float
- min_weight_fraction_leaf:float,默认值= 0.0,在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等
- max_features :考虑的最大特征数,int,float或{“ auto”,“ sqrt”,“ log2”}
1. 如果为int,则max_features在每个分割处考虑特征。
2. 如果为float,max_features则为小数,并 在每次拆分时考虑要素。int(max_features * n_features)
3. 如果是"auto",则max_features=sqrt(n_features)。
4. 如果是"sqrt",则max_features=sqrt(n_features)。
5. 如果为"log2",则为max_features=log2(n_features)。
6. 如果是None,则max_features=n_features。 - random_state : 随机种子,int或RandomState。为了防止过拟合,原理不知道
- max_leaf_nodes:最大的叶子节点数,具体取值依情况调试
- min_impurity_decrease : 限制信息增益的大小,信息增益小于设定数值的分枝不会发生。
- min_impurity_split: 在0.19前使用,现由min_impurity_decrease代替
- class_weight :样本权重
- ccp_alpha:看不懂
属性 - classes_ :标签数组
- feature_importances_:特征重要性(基于基尼指数和信息熵)
- max_features_ :模型使用的最大特征数的推断值
- n_classes_ :样本数
- n_features_ : 特征数
- n_outputs_:
- tree_:tree对象
方法 - apply(X[, check_input]):返回X被预测的叶子索引
- cost_complexity_pruning_path(X, y[, …]):没看懂
- decision_path(X[, check_input]):返回树中的决策路径
- fit(X, y[, sample_weight, …]):训练
- get_depth():获取模型深度
- get_n_leaves():获取模型叶子数
- get_params([deep]):获取模型参数
- predict(X[, check_input]):预测
- predict_log_proba(X):预测X的对数概率
- predict_proba(X[, check_input]):预测X的概率
- score(X, y[, sample_weight]):返回预测y和输出y的正确率占比
- set_params(params):设置模型参数
验证码识别
前面使用的验证码特征和类别对应过于明显,所以我们选择接口的另一种验证码,即70x25大小的,如下:
虽然同样很简单,但是加入了字符。
至于预处理和数字验证码一样,正常验证码->灰度图->二值化->切割->标注。不过经过测试发现,无论我如何调参,准确率都比较低。看了所有的字符才发现,图片的字符虽然没有倾斜变形但有粗体和细体的区别,而我在标注的时候并没有严格让粗体和细体的样本数一样。而且字符的位置不在图片的中间,字符大小也不一样,有的偏上,有的偏下,有的偏小,有的又偏大。即使重新标注的准确率还是难达到我要的标准。
对于这种分割线和字符边缘明显的验证码来说,我们可以将字符从切割后的图片中提取出来,也就是去掉边缘外的空白,然后都调整到一样的大小。这样就去掉了字符位置和大小对算法的干扰,至于粗体和细体,只要保证这两个的训练样本数量相同就可以了。代码如下:
def img_preprocess(file):
img1 = Image.open(file)
pix = np.array(img1)
pix = (pix > 180) * 255
width, height = pix.shape
for i in range(width):
if np.sum(pix[i]==0):
xstart = i
break
for i in range(width-1, 0, -1):
if np.sum(pix[i]==0):
xend = i + 1
break
for i in range(height):
if np.sum(pix[:,i]==0):
ystart = i
break
for i in range(height-1, 0, -1):
if np.sum(pix[:,i]==0):
yend = i + 1
break
new_pix = pix[xstart:xend, ystart:yend]
img = Image.fromarray(new_pix).convert('L')
if new_pix.size != (8, 10):
img = img.resize((8, 10), resample=Image.NEAREST)
img.save(file)接着我们使用决策树重新训练样本并调整参数,我们先看max_depth这个参数,代码如下:
from sklearn.tree import DecisionTreeClassifier
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as mp
def func(k):
x = []
y = []
for label in os.listdir('train'):
for file in os.listdir(f'train/{label}'):
im = Image.open(f'train/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(label)
train_x = np.array(x)
train_y = np.array(y)
model = DecisionTreeClassifier(max_depth=k)
model.fit(train_x, train_y)
x = []
y = []
for label in os.listdir('test'):
for file in os.listdir(f'test/{label}'):
im = Image.open(f'test/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(label)
test_x = np.array(x)
test_y = np.array(y)
score = model.score(test_x, test_y)
return score
if __name__ == "__main__":
os.chdir('G:\\knn\\字符验证码\\')
x = list(range(1, 15))
y = [func(i) for i in x]
mp.scatter(x, y)
mp.show()运行结果:
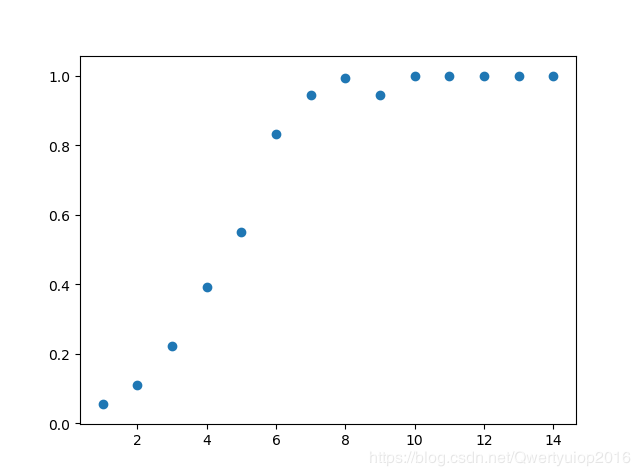
可以看到当max_depth=8的时候,准确率已经很接近1了,所以我们直接将max_depth取8就行了。既然识别的准确率已经接近1,其他的参数调不调整好像并不重要了,不过因为这是验证码的识别,不容易出现过拟合的情况,在其他情况下,如果准确率接近1就更要去调整随机参数(random_state和splitter)和剪枝参数(min_samples_leaf等)来防止过拟合。我后面也试着调整了一下其他参数,发现模型的准确率变化不大,默认即可。
训练测试数据集:https://www.lanzous.com/i8joo0f
最后,我正在学习一些机器学习的算法,对于一些我需要记录的内容我都会分享到博客和微信公众号(python成长路),欢迎关注。平时的话一般分享一些爬虫或者Python的内容。

加载全部内容