网易云音乐是如何推荐歌单给不同用户的?
图灵的猫 人气:0因为考虑到非技术从业者,这篇文章我会写的非常通俗,不出现任何难懂的名词和概念,更不会有任何涉及到线代、算法底层的东西。
先声明一点,下面不会出现任何具体算法实现细节,这是公司机密,但推荐算法其实是可以通过APP的表现来反推的,不会100%准确,但应该也八九不离十。
推荐依据
推荐算法不是无根之水,它必须借助用户的数据才可以进行推荐。即使是冷启动,也需要获得你的微博、微信(你的登录方式)或其他已注册用户的热门喜好。具体的数据包括
-
浏览记录
-
页面停留时间
-
歌曲播放次数
-
点击歌曲但未播放记录
-
点击歌曲且播放完成记录
-
歌曲、歌单、歌手的收藏记录
-
歌单播放次数和歌曲所属标签
-
个人属性(性别,年龄,地理位置等)
……
这样的数据在算法模型里叫做特征,也就是通过这些历史行为数据中的特征,推荐算法可以进行非常精准的个性化推荐。在几年前,网易云音乐其实还没有那么“神”,很多推荐莫名其妙,但是现在的算法相对来说已经非常精准了。
推荐算法
在说歌单的同时,也会给大家看看网易云音乐这个APP里一共有哪些地方用到了推荐算法:
场景一:打开APP时的弹出广告(很烦人对吧,我都懒得点跳过)

算法:有时候打开的广告会不一样,有时候会重复。全屏广告费用很高,假如不是独占类型的,那这块用到的可能有一些简单的人群匹配或者用户画像。如果是单次广告独占,则有可能是按照广告商的要求投放。18年之前没有这个广告功能,但是网易要恰饭的,能理解。
场景二:私人FM
私人FM和电音位于个人主页的头部位置,用户点击率非常高。因为二者本质上很相似,这里只谈FM的算法。

私人FM和单曲、歌单推荐的最大区别是,歌单推荐是一次性生成一个歌曲/歌单列表,但FM只推荐下一首,没有“上一首”功能,这意味着推荐算法会更关注你的瞬时兴趣。因为FM只有喜欢、听完、切歌三种反馈,相对来说比歌单推荐要简单很多,但相对的,信息也少了很多。
可以推算,FM用到的具体方式是由“播放、喜欢、切歌”来判断用户对推荐结果的喜好程度。使用的算法应该是相似性召回和基于用户、基于内容的协同过滤三合一,这一点和单曲推荐很相似,甚至两个功能都使用了一套推荐算法。
FM有个额外的要求是实时推荐,可以将私人FM理解为一个由动态变化的推荐歌曲组成的歌曲序列,这里面应该使用了深度学习算法中的“下一项推荐”模型来生成,用到的可能有Transformer或GRU/RNN模型。
实时推荐的意思是,上一首是“lemon”,如果你听完了,那么下一首可能会给你推荐米津玄师的另一首歌,或者相似的日文歌。如果我在听小英雄的OP,但没听完就切歌了,那么序列中的下一首本来是冰海战纪的ED,此刻可能就会变为一首英文流行歌。
场景三:主页推荐(这块包含的比较多,最主要的是“推荐歌单”功能)

算法反推:页面可以拆开来看

-
每日推荐:这里用到的是单曲推荐,具体算法不难想到,从我的每日推荐歌曲来看,基本是
-
我听过的歌手的其他单曲
-
我听过的歌曲所属分类的其他热门歌曲
-
我听过、收藏过、评论过的歌曲
-
听过我听过歌曲的人,听过的其他热门歌曲
每个部分都分配有不同权重,权重高的,推荐的位置(排序机制)就会靠前,权重低的则会靠后。比如我的列表里,蓝莲花排名第一,但是我最近并没有听过蓝莲花,也没听过许巍的歌。但是我听过民谣/摇滚标签类的歌曲,并且很容易猜到,听过这个标签的人,基本都会听蓝莲花(热门)。那么我的列表里,第1项和第4项的权重应该是更高的。

现在的算法几乎都是千人千面,所以每个用户都有自己的个性化匹配机制,也就是张三的权重和李四的权重是不同的,这也反映出一种个人喜好。而相对于FM,这里的推荐更关注用户的长期兴趣。由用户最近一个月、一个周的行为数据构成。
上面这4种只是主要推荐方式,在具体应用时,算法团队会有更多机制来筛选这些歌曲并在列表内排序,提高对新用户、不活跃用户的推荐精度,而这里用到的算法有协同过滤,基于内容召回以及相似性召回等。对算法具体原理感兴趣的可以自行搜索,这里不展开讲。
2. 歌单推荐:
点进“歌单”按钮,会跳到一个歌单广场,但是我平时不怎么用,这里和主页推荐歌单放在一起讲,因为两个模块的算法应该是一样的。
推荐歌单是网易云音乐的主要流量通道,95%以上的用户每天打开APP会首先看这些推荐歌单。推荐歌单算法,网易云在全球范围内都属于做的很不错,因为歌单这个东西和歌曲不一样,里面有很多首歌组成,并且每首歌的调性有可能相似,也有可能不同,比传统推荐要更难。B站、Youtube都有类似算法,比如通过用户的收藏夹推荐相似的收藏夹。

歌单有个特点就是UGC(用户生成内容),UGC歌单是实时的,即用户有收听歌曲行为后可实时带来推荐变化,比如刷新一下,会推送不一样的歌单给你。
具体的推荐过程大概如下图,大家只需要知道“召回”和“排序”就行。
-
召回,是从数以百万计的曲库进行初步筛选,选出几百个相对符合用户口味的候选歌曲
-
排序,是把这几百个候选歌曲通过深度学习、因子分解机等算法进行精准的个性化排序
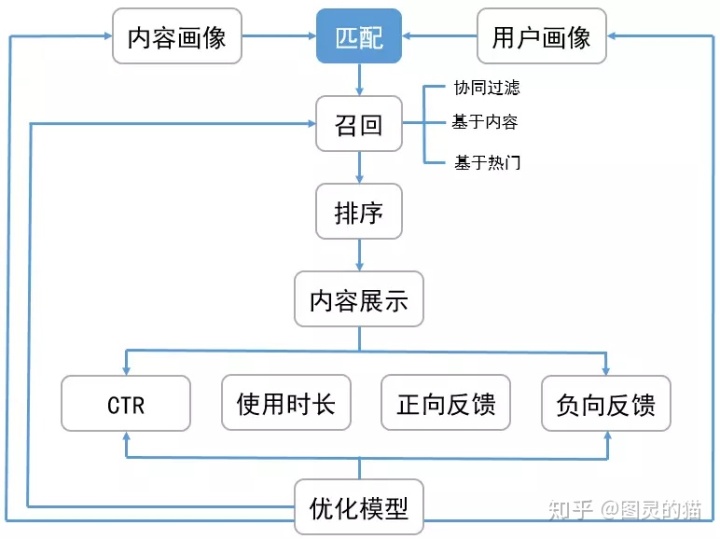
召回的三种主要方式我大概解释一下
-
协同过滤,基于用户的行为数据,如听过的歌曲或者个人标签找到相似用户或者相似内容
-
基于内容,内容标签化,构建完整的用户画像,然后根据内容相似度进行匹配
-
基于热门 ,和你相似品味的用户聚合成一个圈,圈里的人喜欢什么,就推给你什么
这一块涉及技术太多,感兴趣的同学也可以自行搜索。
3. 电台推荐
电台推荐就是以前的FM频道,现在整合了很多栏目。基本的流程和推荐算法其实和上面的歌单推荐一样,只不过歌单变成了电台,推荐的依据也从歌单里的歌曲、评论、收藏、用户,变成了电台的听众、主播、标签等

场景四:云村推荐
-
云村广场:网易云音乐以前总是被人说清高、不接地气、评论太文青。现在这个云村广场(为了回答这个问题,我第一次点进去看),就是云音乐开始接地气的证明。点进去,我以为自己打开了抖音+快手。

这里用到的短视频推荐算法应该和快手、抖音一样,使用短视频的属性、标签和用户的口味、标签做匹配,相似性高的或者比较热门的就进行推荐。具体流程也是先召回再排序,可使用的模型较多,这里不好猜。不过短视频时代,最吸引眼球的就是图里这种内容,比什么算法都好使。
2. 好友动态:这里的动态推荐算法和朋友圈一样,但是比朋友圈简单,就是按你的关注的人的动态,以时间倒序(最新的排在最前面)进行排序。
场景五:视频推荐
视频是云音乐后来推出的一大功能,应该也是按照短视频推荐的方法来进行精准推荐,不同点在于这些视频主题更加明确,比如第一个就是华晨宇的采访,直接推送给听过华晨宇歌曲、买过华晨宇专辑的用户即可。

问题分析
用云音乐这么久,有一些问题大家肯定也比较困惑,这里做个简单分析
问题1:马太效应
19年之前网易云的推荐算法存在一个明显的问题:什么热门推什么。比如下面这个歌单,在我的推荐歌单列表中出现过不下100次,我怀疑给每个听过英文歌的用户都推了这个歌单,在座的如果有人听过,麻烦评论区留个“1”,一起验证一下。

这样的问题在于,越是热门的歌单越容易得到曝光,曝光越多也就越热门,而新歌单就很难得到曝光。这个问题在很多APP上都存在,解决方法也比较成熟。可以看到,从2019年开始,云音乐的算法团队做了改进,把基于热门的召回降低了权重,所以现在这种现象在逐渐减少。(也不排除是我的听歌口味变了)
问题2:重复推荐
现在很多推荐算法存在一个致命问题,就是重复推荐。在云音乐里,当你听过一些歌曲,就使劲推送相似的歌曲,比如我有一次听了小鳄鱼,之后就使劲给我推儿歌,这很容易引起用户的反感。
这其实是推荐算法中著名的EE(Exploitation,Exploration)问题。EE问题中的Exploitation(开发)就是:对用户比较确定的兴趣,当然要尽可能迎合用户口味,而Exploration(探索)就是:光对着用户已知的兴趣使用,用户很快会腻,所以要不断探索用户新的兴趣才行。如何解决这个问题,我想云音乐一定使用了BANDIT一类的强化学习方法来优化,下面我举个例子帮助大家理解:
一个赌徒,要去摇Tigger机,走进赌场一看,一排Tigger机,外表一模一样,但是每个Tigger机吐钱的概率可不一样,他不知道每个Tigger机吐钱的概率分布是什么,那么每次该选择哪个Tigger机可以做到最大化收益呢? 最好的办法是去试一试,不是盲目地试,而是有策略地快速试一试,这些策略就是Bandit算法。假设我们已经通过一些数据,得到了当前每个Tigger机的吐钱的概率,如果想要获得最大的收益,我们会一直摇哪个吐钱概率最高的Tigger机,这就是Exploitation。 但是,当前获得的信息并不是Tigger机吐钱的真实概率,可能还有更好的Tigger机吐钱概率更高,因此还需要进一步探索,这就是Exploration。
最后,云音乐里很多模块的推荐算法其实都非常相似,但因为具体实施的算法团队不同,细节上肯定有所差异,效果也不会完全一样。对于EE问题的解决,以及如何提高用户粘性,想必算法团队也做了很多尝试,所以才有了这几年界面、体验的不断改善。
其实,有个问题不解决,推荐算法做的再好也没用——版权,网易云音乐的未来将何去何从,让我们保持关注吧。
加载全部内容