SQLServer地址搜索性能优化
Andy Wei 人气:0这是一个很久以前的例子,现在在整理资料时无意发现,就拿出来再改写分享。
1.需求
1.1 基本需求: 根据输入的地址关键字,搜索出完整的地址路径,耗时要控制在几十毫秒内。
1.2 数据库地址表结构和数据:
表TBAddress
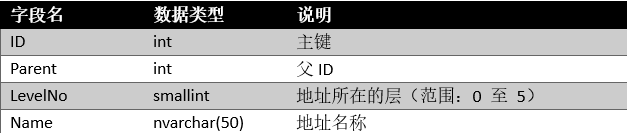
表数据
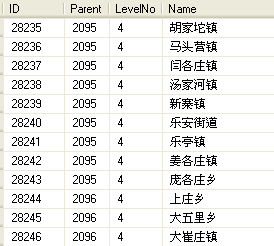
1.3 例子:
e.g. 给出一个字符串如“广 大”,找出地址全路径中包含有“广” 和“大”的所有地址,結果如下:

下面将通过4个方法来实现,再分析其中的性能优劣,然后选择一个比较优的方法。
2.创建表和插入数据
2.1 创建数据表TBAddress
use test;
go
/* create table */
if object_id('TBAddress') is not null
drop table TBAddress;
go
create table TBAddress
(
ID int ,
Parent int not null ,
LevelNo smallint not null ,
Name nvarchar(50) not null ,
constraint PK_TBAddress primary key ( ID )
);
go
create nonclustered index ix_TBAddress_Parent on TBAddress(Parent,LevelNo) include(Name) with(fillfactor=80,pad_index=on);
create nonclustered index ix_TBAddress_Name on TBAddress(Name)include(LevelNo)with(fillfactor=80,pad_index=on);
go
create table
2.2 插入数据
use test
go
/*insert data*/
set nocount on
Begin Try
Begin Tran
Insert Into TBAddress ([ID],[Parent],[LevelNo],[Name])
Select 1,0,0,N'中国' Union All
Select 2,1,1,N'直辖市' Union All
Select 3,1,1,N'辽宁省' Union All
Select 4,1,1,N'广东省' Union All
... ...
Select 44740,930,4,N'奥依塔克镇' Union All
Select 44741,932,4,N'巴音库鲁提乡' Union All
Select 44742,932,4,N'吉根乡' Union All
Select 44743,932,4,N'托云乡'
Commit Tran
End Try
Begin Catch
throw 50001,N'插入數據過程中發生錯誤.' ,1
Rollback Tran
End Catch
go
附件: insert Data
Note: 数据有44700条,insert代码比较长,所以采用附件形式。
3.测试,方法1
3.1 分析:
a. 先搜索出包字段Name中含有“广”、“大”的所有地址记录存入临时表#tmp。
b. 再找出#tmp中各个地址到Level 1的全路径。
c. 根据步骤2所得的结果,筛选出包含有“广”和“大”的地址路径。
d. 根据步骤3筛选的结果,查询所有到Level n(n为没有子地址的层编号)的地址全路径。
3.2 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV0]') is not null
Drop Procedure [up_SearchAddressByNameV0]
Go
create proc up_SearchAddressByNameV0
(
@Name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max)
declare @tmp Table (Name nvarchar(50))
set @Name=@Name+' '
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql ='select ''' +replace(@Name,' ',''' union all select ''')+''''
insert into @tmp(Name) exec(@sql)
if object_id('tempdb..#tmp') is not null drop table #tmp
if object_id('tempdb..#') is not null drop table #
create table #tmp(ID int )
while @Name>''
begin
insert into #tmp(ID)
select a.ID from TBAddress a where a.Name like '%'+substring(@Name,1,patindex('% %',@Name)-1)+'%'
set @Name=Stuff(@Name,1,patindex('% %',@Name),'')
end
;with cte_SearchParent as
(
select a.ID,a.Parent,a.LevelNo,convert(nvarchar(500),a.Name) as AddressPath from TBAddress a where exists(select 1 from #tmp x where a.ID=x.ID)
union all
select a.ID,b.Parent,b.LevelNo,convert(nvarchar(500),b.Name+'/'+a.AddressPath) as AddressPath
from cte_SearchParent a
inner join TBAddress b on b.ID=a.Parent
--and b.LevelNo=a.LevelNo -1
and b.LevelNo>=1
)
select a.ID,a.AddressPath
into #
from cte_SearchParent a
where a.LevelNo=1 and exists(select 1 from @tmp x where a.AddressPath like '%'+x.Name+'%' having count(1)=(select count(1) from @tmp))
;with cte_result as
(
select a.ID,a.LevelNo,b.AddressPath
from TBAddress a
inner join # b on b.ID=a.ID
union all
select b.ID,b.LevelNo,convert(nvarchar(500),a.AddressPath+'/'+b.Name) As AddressPath
from cte_result a
inner join TBAddress b on b.Parent=a.ID
--and b.LevelNo=a.LevelNo+1
)
select distinct a.ID,a.AddressPath
from cte_result a
where not exists(select 1 from TBAddress x where x.Parent=a.ID)
order by a.AddressPath
Go
procedure:up_SearchAddressByNameV0
3.3 执行查询:
exec up_SearchAddressByNameV0 '广 大'

共返回195行记录。
3.4 客户端统计信息:
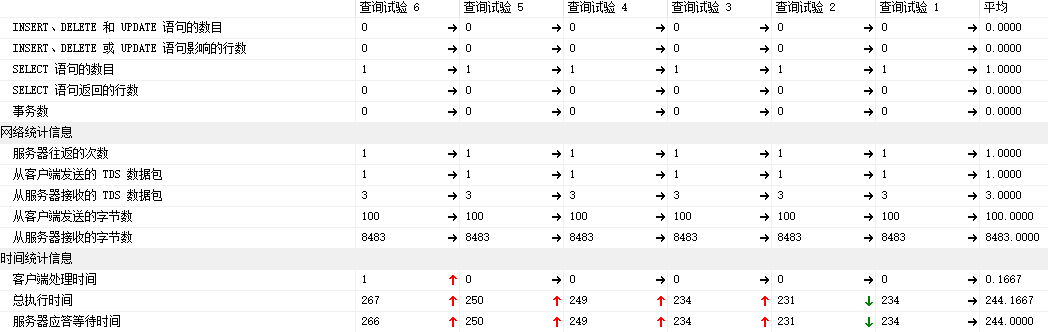
平均的执行耗时: 244毫秒
4.测试,方法2
方法2是参照方法1,并借助全文索引来优化方法1中的步骤1。也就是在name列上建立全文索引,在步骤1中,通过全文索引搜索出包字段Name中含有“广”、“大”的所有地址记录存入临时表#tmp,其他步骤保持不变。
4.1 创建全文索引
use test go /*create fulltext index*/ if not exists(select 1 from sys.fulltext_catalogs a where a.name='ftCatalog') begin create fulltext catalog ftCatalog As default; end go --select * From sys.fulltext_languages create fulltext index on TBAddress(Name language 2052 ) key index PK_TBAddress go alter fulltext index on dbo.TBAddress add(Fullpath language 2052) go
Note: 在Name列上创建全文索引使用的语言是简体中文(Simplified Chinese)

4.2 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV1]') is not null
Drop Procedure [up_SearchAddressByNameV1]
Go
create proc up_SearchAddressByNameV1
(
@Name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max),@contains nvarchar(500)
declare @tmp Table (Name nvarchar(50))
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql ='select ''' +replace(@Name,' ',''' union all select ''')+''''
set @contains='"'+replace(@Name,' ','*" Or "')+'*"'
insert into @tmp(Name) exec(@sql)
if object_id('tempdb..#') is not null drop table #
;with cte_SearchParent as
(
select a.ID,a.Parent,a.LevelNo,convert(nvarchar(2000),a.Name) as AddressPath from TBAddress a where exists(select 1 from TBAddress x where contains(x.Name,@contains) And x.ID=a.ID)
union all
select a.ID,b.Parent,b.LevelNo,convert(nvarchar(2000),b.Name+'/'+a.AddressPath) as AddressPath
from cte_SearchParent a
inner join TBAddress b on b.ID=a.Parent
--and b.LevelNo=a.LevelNo -1
and b.LevelNo>=1
)
select a.ID,a.AddressPath
into #
from cte_SearchParent a
where a.LevelNo=1 and exists(select 1 from @tmp x where a.AddressPath like '%'+x.Name+'%' having count(1)=(select count(1) from @tmp))
;with cte_result as
(
select a.ID,a.LevelNo,b.AddressPath
from TBAddress a
inner join # b on b.ID=a.ID
union all
select b.ID,b.LevelNo,convert(nvarchar(2000),a.AddressPath+'/'+b.Name) As AddressPath
from cte_result a
inner join TBAddress b on b.Parent=a.ID
--and b.LevelNo=a.LevelNo+1
)
select distinct a.ID,a.AddressPath
from cte_result a
where not exists(select 1 from TBAddress x where x.Parent=a.ID)
order by a.AddressPath
Go
procedure:up_SearchAddressByNameV1
4.3测试存储过程:
exec up_SearchAddressByNameV1 '广 大'

共返回195行记录。
4.4 客户端统计信息:
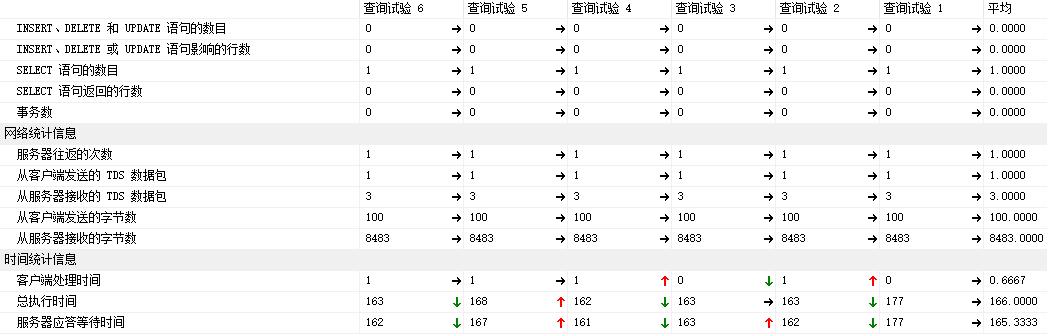
平均的执行耗时: 166毫秒
5.测试,方法3
在方法2中,我们在Name列上创建全文索引提高了查询性能,但我们不仅仅局限于一两个方法,下面我们介绍第3个方法。
第3个方法,通过修改表的结构和创建全文索引。在表TBAddress增加多一个字段FullPath存储各个地址到Level 1的全路径,再在FullPath列上创建全文索引,然后直接通过全文索引来搜索FullPath列中包含“广”和“大”的记录。
5.1 新增加字段FullPath,并更新列FullPath数据:
use test;
go
/*alter table */
if not exists ( select 1
from sys.columns a
where a.object_id = object_id('TBAddress')
and a.name = 'Fullpath' )
begin
alter table TBAddress add Fullpath nvarchar(200);
end;
go
create nonclustered index IX_TBAddress_FullPath on dbo.TBAddress(Fullpath) with(fillfactor=80,pad_index=on);
go
/*update TBAddress */
with cte_fullPath
as ( select ID, Parent, LevelNo, convert(nvarchar(500), isnull(Name, '')) as FPath, Fullpath
from dbo.TBAddress
where LevelNo = 1
union all
select A.ID, A.Parent, A.LevelNo, convert(nvarchar(500), B.FPath + '/' + isnull(A.Name, '')) as FPath, A.Fullpath
from TBAddress as A
inner join cte_fullPath as B on A.Parent = B.ID
)
update a
set a.Fullpath = isnull(b.FPath, a.Name)
from dbo.TBAddress a
left join cte_fullPath b on b.ID = a.ID;
go
5.2 在列FullPath添加全文索引:
alter fulltext index on dbo.TBAddress add(Fullpath language 2052)
5.3 存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV2]') is not null
Drop Procedure [up_SearchAddressByNameV2]
Go
create proc up_SearchAddressByNameV2
(
@name nvarchar(200)
)
As
declare @contains nvarchar(500)
set nocount on
set @contains='"'+replace(@Name,' ','*" And "')+'*"'
select id,FullPath As AddressPath from TBAddress a where contains(a.FullPath,@contains) and not exists(select 1 from TBAddress x where x.Parent=a.ID) order by AddressPath
Go
procedure:up_SearchAddressByNameV2
5.4 测试存储过程:
exec up_SearchAddressByNameV2 '广 大'

共返回195行记录。
5.5 客户端统计信息:
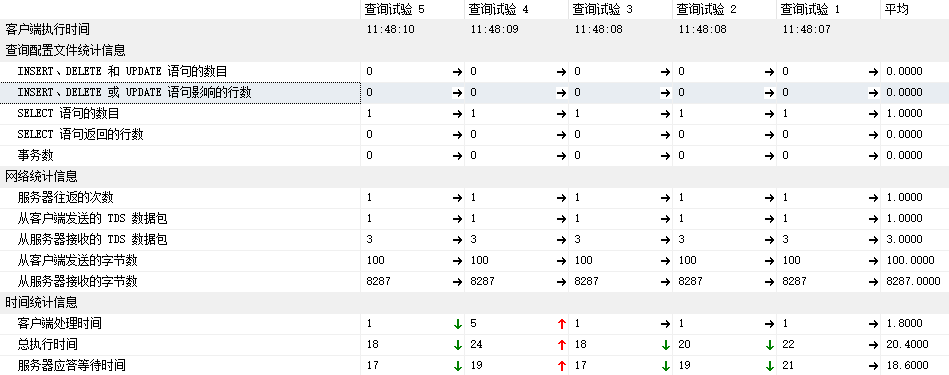
平均的执行耗时: 20.4毫秒
6.测试,方法4
直接使用Like对列FullPath进行查询。
6.1存储过程代码:
Use test
Go
if object_ID('[up_SearchAddressByNameV3]') is not null
Drop Procedure [up_SearchAddressByNameV3]
Go
create proc up_SearchAddressByNameV3
(
@name nvarchar(200)
)
As
set nocount on
declare @sql nvarchar(max)
declare @tmp Table (Name nvarchar(50))
set @Name=rtrim(rtrim(@Name))
while patindex('% %',@Name)>0
begin
set @Name=replace(@Name,' ',' ')
end
set @sql='select id,FullPath As AddressPath
from TBAddress a where not exists(select 1 from TBAddress x where x.Parent=a.ID)
'
set @sql +='And a.FullPath like ''%' +replace(@Name,' ','%'' And a.FullPath Like ''%')+'%'''
exec (@sql)
Go
procedure:up_SearchAddressByNameV3
6.2 测试存储过程:
exec up_SearchAddressByNameV3 '广 大'

共返回195行记录。
6.3 客户端统计信息
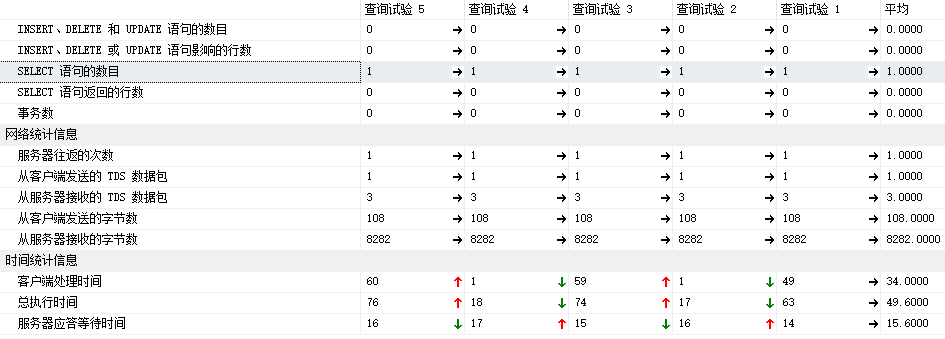
平均的执行耗时: 34毫秒
7.小结
这里通过一个简单的表格,对方法1至方法4作比较。

从平均耗时方面分析,一眼就知道方法3比较符合开始的需求(耗时要控制在几十毫秒内)。
当然还有其他的方法,如通过程序实现,把数据一次性加载至内存中,再通过程序写的算法进行搜索,或通过其他工具如Lucene来实现。不管哪一种方法,我们都是选择最优的方法。实际的工作经验告诉我们,在实际应用中,多选择和测试不同的方法来,选择其中一个满足我们环境的,而且是最优的方法。
加载全部内容