推荐中的多任务学习-YouTube视频推荐
饥饿的小鱼 人气:1本文将介绍Google发表在RecSys’19 的论文《Recommending What Video to Watch Next: A Multitask Ranking System》。主要解决大规模视频推荐中的排序阶段的多任务学习和用户选偏置问题。
- 背景
给定当前用户正在观看的视频,推荐给用户下一个可能观看或者喜欢的视频。在实际推荐场景中的两个主要问题:
1)多目标:我们不仅希望推荐的视频用户会点击,而且希望用户会给好评并分享给朋友观看
2)选择偏置:用户点击视频可能因为该视频在页面的顶部,并不是用户真的喜欢。如果不考虑这种偏置,推荐系统会误以为用户喜欢这种类型视频,导致恶性循环。
为了解决这些问题,文章提出使用Multi-gate Mixture-of-Experts (MMoE)进行多任务学习,并对Wide&deep做出了扩展,引入一个浅层台模型消除选择偏置。MMoE是多任务学习的一种架构,核心思想是对每个学习任务将底部共享层替换为MoE层并加上门控网络,也是由google提出的,可以参考下原论文[2]。
- 模型架构
总体架构如图
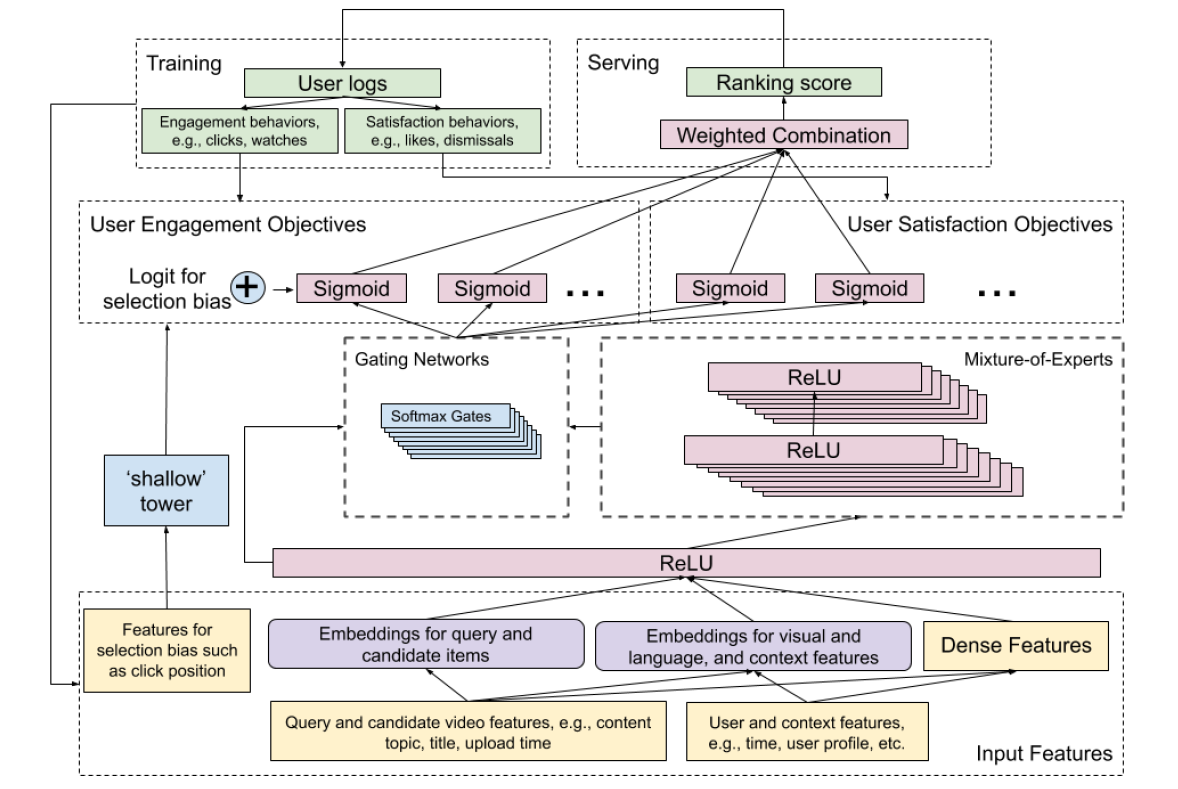
MMoE部分主要用于解决多目标学习,具体来说,文章将多目标分成两组:1)参与度目标,例如点击、观看时长等;2)满意度目标,用户评分等。每个expert关注输入的不同部分,利用多门控机制可以控制expert的权重。
shallow tower部分用于减少选择偏置的影响,将和偏置有关的特征作为输入。该部分类似于wide&deep的wide部分,输出作为主模型的偏置。
1.建模任务间联系和冲突
当任务间的关联比较低时,使用硬参数的底层共享模型很多进行多目标学习,为了解决这个问题,文章使用基于软参数的MMoE进行学习,让多个任务共享这些“专家”,也可以用门控网络来协调不同“专家“所起的作用。下图是提出的多任务模型
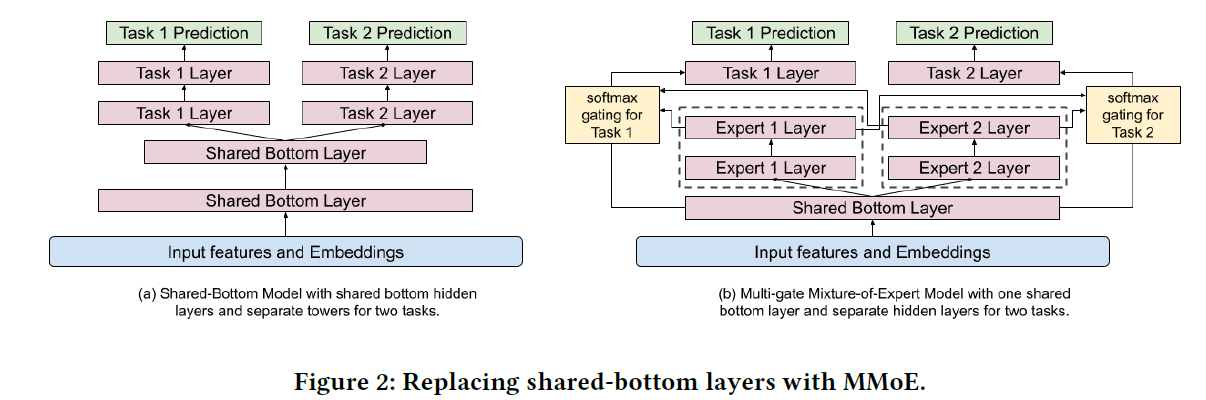
一般来说,在输入层或者隐含层之上增加”专家“层,最终可以更好地对多模态的特征空间进行建模。但是直接加在输入层之上,会增加模型训练代价(因为输入层维度相比隐含层包含更多的参数),因此文章采用”专家“层加在隐含层之上的方法。
对给定的任务\(k\),
\[
\begin{aligned}y_{k} &=h^{k}\left(f^{k}(x)\right) \\\text { where } f^{k}(x) &=\sum_{i=1}^{n} g_{(i)}^{k}(x) f_{i}(x)\end{aligned}
\]
对应的门控
\[
g^{k}(x)=\operatorname{softmax}\left(W_{g^{k}} x\right)
\]
2.偏置消除
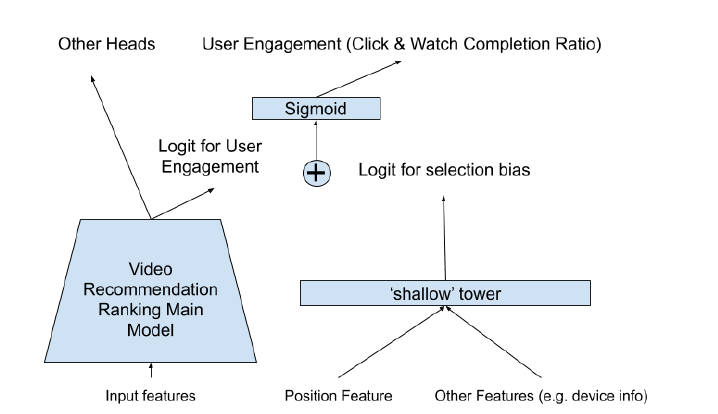
关于选择偏置问题,本文开头已经介绍了,通常用户倾向于点击显示在页面前面的视频。模型的输入被分为两部分,主塔部分输入为主要的特征信息,浅层塔输入为和偏置有关的信息。
训练过程,浏览时的位置作为输入特征的一部分,设置drop-out,避免过度依赖位置特征。serving时,位置特征设为missing。将设备信息会被加入到shallow tower的输入中,是因为不同设备上不同位置的bias是不同的。
- discussion
具体的实验部分可以看原论文,另外论文也提出了一些在实践中需要考虑的问题。如
1.多模态特征空间
2.可扩展性
3.效果与效率的折衷
4.模型压缩等
references:
[1] Recommending What Video to Watch Next- A Multitask Ranking System
[2] Modeling task relationships in multi-task learning with multi-gate mixture-of- experts
加载全部内容