一步步教你建立SQL数据库的表分区
人气:0直接上步骤:
1)新建一个数据库


2)添加几个文件组

3)回到“常规”选项卡,添加数据库文件
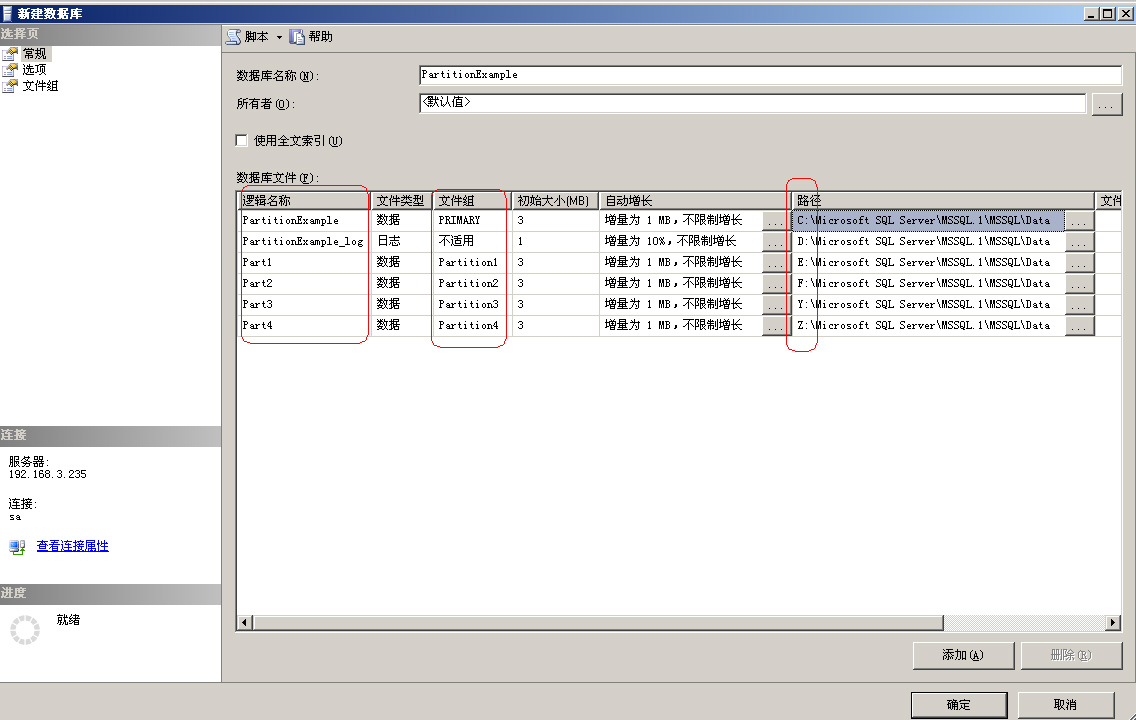
看到用红色框框起来的地方没?上一步中建立的文件组在这里就用上了。再看后面的路径,我把每一个文件都单独放在不同的磁盘上,而且最好都是单独的放在不同的物理盘上,这样会大大提高数据的性能。 点击“确定”数据库就算创建完成了。
4)接下来要做的是建立一个分区行数,SQL语句如下:大家学习的时候最好不要直接COPY,动手把它抄一遍也好。
create partition function PartFuncForExample(Datetime)
as Range Right for Value('20000101','20010101','20020101','20030101')
这里我准备用表中的某个时间字段作为分区的条件,当然你也可以用其他的,比如INT之类,只要好分段的都可以。
这里注意 Right 关键字,意思就是当记录的时间(在下面会被指到表的某个字段)大于等于20000101的时候,数据会被分到下一个区间,比如2000年1月1号之前的数据会被分到一区,包含2000年1月1号和之后的数据会被分到二区,以此类推。Right 也可以使用Left替代,意思同上类似。另外,上面我定义了四个分割点,这四个分割点是根据我们刚刚创建的文件组来决定的。四个分割点就能产生5个区间段,我们把每个区间段的数据存入一个文件组。
正确执行上述语句后你可以在数据里找到以“PartFuncForExample”命名的分区函数,如下图
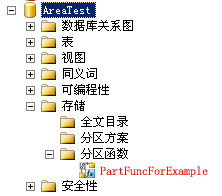
5)把分区函数建立好以后,我们再来建立分区方案。目的是为了把分区函数产生的分区映射到文件数据组里。分区函数是告诉数据库如何分区数据,而分区方案是告诉数据库如何把已分区的数据存到哪个文件组里。
下面我来创建分区方案。
Create Partition Scheme PartSchForExample //创建一个分区方案+分区方案名称 As Partition PartFuncForExample//目的为了 分区函数PartFuncForExample To ( PRIMARY, //文件组名 Partition1, //文件组名 Partition2, //文件组名 Partition3, //文件组名 Partition4 //文件组名 )
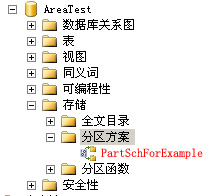
正确执行后能在分区方案中看到,如下图
6)马上就快要大公告成了,下面我们来建立要分区存储的表,该表的数据理论上应该是非常非常多的,百万级别的记录以上而且基本上是不更新的。要不然建立分区存储就没多大意义了。
Create Table PartitionTable( [ID] [int] Identity(1,1) not null, [Name] [nvarchar](50) not null, [LoginDate] [DateTime] not null //用来进行分区 ) On PartSchForExample([LoginDate]) //上面提到的指定分区字段就是这里指定的了。
执行这段SQL,没报错的话就大功告成了,呵呵.
总结:
分区存储提高了数据库的性能,被分区存储的数据物理上是多个文件,但逻辑上任然是一个表,对表的任何操作都跟没分区之前一样。插入、删除、查询、更新等操作的时候,数据库会自动为你找到对应的分区,然后执行操作。另外的话 把多个数据文件、日志文件都分别部署在不同的高性能物理盘上,也能大大提高性能.
当然,分区存储的好处还有很多我不知道的,欢迎大家一起探讨!
加载全部内容