SQL Server内存遭遇操作系统进程压榨案例分析
人气:0最近一台DB服务器偶尔出现CPU报警,我的邮件报警阈(请读yù)值设置的是15%,开始时没当回事,以为是有什么统计类的查询,后来越来越频繁。
探索:我决定来查一下,究竟是什么在作怪,我排查的顺序如下:
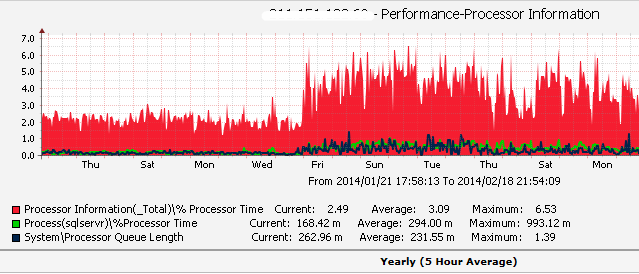
1、首先打开Cacti监控,发现最近CPU均值在某天之后骤然上升,并且可以看到System\Processor Queue Length 和 sqlservr\%ProcessorTime 也在显著的变化。
2、从最容易入手的低效SQL开始,考虑是不是最近业务做了什么修改?连接到该SQL实例,打开活动监视器,展开“最近耗费大量资源的查询”,并CPU时间倒序,在这里并未发现有即时的耗费资源的查询。据个人经验,这里的值如果是4位数,分钟内执行次数3位数,一般的服务器CPU大概就10%以上,如果cpu时间那里是5位数,且分钟内执行次数也很高,几百次以上,那CPU一般就会不淡定了。图片仅为演示
3、没有耗资源的SQL,这是DBA最不愿意看到的结果,因为也许,SQL Server受到了来自内部或者外部的压力,使得自己花费了过多的时间去处理与操作系统的沟通去了。SQL Server常见的非查询低效类的性能问题,绝大多数都来自于内存或者硬盘,而这两者有的时候需要同时研究对比基线,才能确定谁是因,谁是果。在这里,我们首先查看SQL Server内存使用情况,当打开性能计数器时,我和我的小伙伴们都惊呆了……安装了64G内存的数据库,SQL Server的TargetMemory仅有500多兆!这其中StolenPage还占用了200多兆,数据库DataPage仅有200多兆的内存可供使用,Oh,Shit!虽然我很不想用“去哪了”这三个字,但是“我的内存去哪了“?同时我们也注意到PageLifeExpectancy值只有26(一个内存充足的服务器,这个值至少应该是上W的),而很早之前我们津津乐道的"Cache Hit Ration"却仍然保持一个比较高的水准98! 这个案例告诉我们,缓存命中率这个性能计数器很多时候说明不了什么问题。

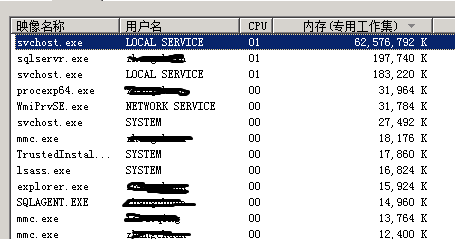
4、OK,既然这样,是谁占用了本该属于我亲爱的SQL Server的内存呢?我们继续,打开Wiindows任务管理,选定进程选项卡,点击显示所有用户进程,发现svchost.exe占用了绝大多数的60G内存!
5、那svchost.exe又是个什么东西呢?我们下面就用到ProcessMonitor这个工具了,打开后自动加载所有Wiindows进程,按内存排序后,鼠标移至svchost.exe进程上,显示为Remote Registry服务。

6、查到这里,事情已经有了一定的眉目,这个多半是windows内存泄露Bug,遂google关键词: windows server 2008 r2 remote registry memory leak
找到如下链接:http://support.microsoft.com/kb/2699780/en-us
果然:Assume that you query performance counters on a remote computer by using an application on a computer that is running Windows 7 or Windows Server 2008 R2. In this situation, the memory usage of the Remote Registry service on the local computer increases until the available memory is exhausted.
解决方法:1、重启服务器,安装hotfix
2、因为重启服务器会影响到业务,所以我在想重启RemoteRegistry服务,应该也能暂时解决问题,这个bug应该是在某种固定情景下发生的。
随后,在合适的时间,我重启了这个服务,SQL Server的TargetMemory重新恢复到60多G,CPU也正常了,目前为止该问题未再发生。
后续跟进:DBA的工作,说难也难,说容易也容易,发现问题,解决问题还不够,我们还要意识到自己的欠缺,在本案例中,我之前并没有建立起SQL Server内存的监控,所以没有在第一时间就发现病情的严重性,好在该服务器并未承担重要业务,否则后果不堪设想,说不定早就崩溃过了,后怕之处在于,如果崩溃了,自然要重启服务器,到那个时候,我们连第一现场都没有,当leader问起来,我又该使劲挠头了。
该事件之后,我建立起了SQL Server内存的监控,1天后,我从新的监控数据中,又发现了一台服务器出现相同的问题!我很庆幸,不是庆幸服务器没宕机,而是庆幸我做对了。
附一张内存监控图,可以看到服务重启之后,SQL Server的Total Pages一直在上升,并逐渐稳定,Page life expectancy也在变得越来越大,CPU也能指示病症已消除,我很欣慰。


总结:
服务器在出现性能问题前,大部分是提前有一些征兆的,尤其是内存泄露,因为内存是一点点被压榨掉的,最后到达一个极限时,SQL Server就会突然Crash掉,然后只留给你一个dump,微软就笑了。有经验的大夫应该从日常的腰酸背痛中看出一些端倪,然后进一步分析,提前预知重大疾病的发生,这就是DBA的价值。这个案例,告诉我,重视服务器异常的细节变化,才能做到防患于未然。
加载全部内容