JAVA8学习——深入Comparator&Collector(学习过程)
dawa大娃bigbaby 人气:1深入Comparator&Collector
从源码深入Comparator
Comparator从Java1.2就出来了,但是在1.8的时候,又添加了大量的默认方法.
compare()
equals()
reversed() //倒序
thenComparing(Comparator<? super T> other) //然后,再去比较.
thenComparing( Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator) //先通过第一个比较器,再执行第二个比较器...串联
thenComparing()
thenComparingInt()
thenComparingLong()
thenComparingDouble()
reverseOrder()
naturalOrder()
nullsFirst()
nullsLast()
comparing () //静态方法
comparing()
comparingInt()
comparingLong()
comparingDouble()### 从Demo代码看Comparator
package com.dawa.jdk8.stream2;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
//关于比较器comparator,案例详解.
public class MyComparator {
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome", "nihao");
//按照字母排序
Collections.sort(list);
System.out.println(list);
//按照字符串的长度.
Collections.sort(list, (item1, item2) -> item1.length() - item2.length());
System.out.println(list);
//按照字符串的长度降序排序.
Collections.sort(list, (item1, item2) -> item2.length() - item1.length());
//使用方法引用
//长度排序
Collections.sort(list, Comparator.comparingInt(String::length));
System.out.println(list);
//长度倒叙排序
Collections.sort(list, Comparator.comparingInt(String::length).reversed());
System.out.println(list);
//使用lambda表达式实现上述两个方法
// Collections.sort(list,Comparator.comparingInt(item->item.length()).reversed());
//这里,reversed()方法,参数要的是Object类型.
//参数的类型推断.
Collections.sort(list,Comparator.comparingInt((String item)->item.length()).reversed());
//这样写就行了.
//问题:之前为什么会成功? 因为是从Stream<T> 类型开始推断的,可以获取到原属性的元素.
//问题:为什么上述的类型推断失败了/? 看sort方法的 Comparator类的泛型<T>,T是传入参数的泛型- <? super T>.
// String上的类型.你没指定,编译器也没办法帮你指定.
// public static <T> void sort(List<T> list, Comparator<? super T> c) {
// list.sort(c);
// }
//如: Collections.sort(list,Comparator.comparingInt((Boolean item)->1).reversed());
//这样不会被兼容.因为Boolean 不是 String的上类型.
//如: Collections.sort(list,Comparator.comparingInt((Object item)->1).reversed());
//这样就是可以的.
//如: Collections.sort(list,Comparator.comparingInt(item->item.length());
//这样也是可以的.
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public static <T> void sort(List<T> list, Comparator<? super T> c) {
list.sort(c);
}关于: <? super T> 泛型的使用.需要注意.
语义更宽泛,但是从实际结果类型,实际就是T类型本身.这个需要仔细思考一下.
Comparator比较器的串联使用
//通过两层比较,1:排序(升序) ,2:字母顺序排序. 使用thenComparing()
Collections.sort(list,Comparator.comparingInt(String::length).thenComparing(String.CASE_INSENSITIVE_ORDER));
thenComparing()方法源码如下
/**
* Returns a lexicographic-order comparator with another comparator.
* If this {@code Comparator} considers two elements equal, i.e.
* {@code compare(a, b) == 0}, {@code other} is used to determine the order.
*
* <p>The returned comparator is serializable if the specified comparator
* is also serializable.
*
* @apiNote
* For example, to sort a collection of {@code String} based on the length
* and then case-insensitive natural ordering, the comparator can be
* composed using following code,
*
不区分大小写,的实现. 技术上述案例.
* <pre>{@code
* Comparator<String> cmp = Comparator.comparingInt(String::length)
* .thenComparing(String.CASE_INSENSITIVE_ORDER);
* }</pre>
*
* @param other the other comparator to be used when this comparator
* compares two objects that are equal.
* @return a lexicographic-order comparator composed of this and then the
* other comparator
* @throws NullPointerException if the argument is null.
* @since 1.8
*/
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}前面比较器的结果等于0,这个thenComparing()才会被调用. 就如三个长度相同的那三个数,才会被二次排序.
也就是说如果第一个比较器,能够排序,就用第一个,第一个排序不成再用第二个.
另一种实现
Collections.
sort(list,Comparator.comparingInt(String::length).
thenComparing((item1,item2)->item1.toLowerCase().compareTo(item2)));另一种实现
Collections.sort(list,Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toUpperCase)));另一种实现
Collections.sort(list,Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toLowerCase,Comparator.reverseOrder())));上述几个案例,主要就是对于 thenComparing()方法的不同使用实现.
那么,下面这个方法的输出结果是什么?
Collections.sort(list,Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toLowerCase,Comparator.reverseOrder())));再次重复一下:前面比较器的结果等于0,这个thenComparing()才会被调用. 就如三个长度相同的那三个数,才会被二次排序.也就是说如果第一个比较器,能够排序,就用第一个,第一个排序不成再用第二个.
多级排序
Collections.sort(list,Comparator.comparingInt(String::length).reversed()
.thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder()))
.thenComparing(Comparator.reverseOrder()));JDK1.8之前,Collections里面提供的方法是很少的,从JDK1.8之后,新增了大量的实现方法和具体的特化的实现.
避免了装箱和拆箱操作.这也可能会影响性能.
自定义Collector实现类
实现Collector接口
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A, R> finisher,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(finisher);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = Collectors.CH_NOID;
if (characteristics.length > 0) {
cs = EnumSet.noneOf(Characteristics.class);
Collections.addAll(cs, characteristics);
cs = Collections.unmodifiableSet(cs);
}
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);
}
Characteristics {
CONCURRENT,
UNORDERED,
IDENTITY_FINISH
}
}
自定义的收集器
package com.dawa.jdk8.stream2;
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
import static java.util.stream.Collector.Characteristics.IDENTITY_FINISH;
public class MySetCollector<T> implements Collector<T,Set<T>,Set<T>> {
@Override
public Supplier<Set<T>> supplier() {
System.out.println("supplier invoked");
return HashSet<T>::new;// 返回一个HasHSet容器.
}
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumalator invoked");//累加器
return Set<T>::add;
// return HashSet<T>::add; //不行,没有静态方法支持. 应该是 Supplier返回值的父类接口. 不能使用具体类型的set.
}
@Override
public BinaryOperator<Set<T>> combiner() {
System.out.println("combiner invoked");//并行流的时候,合并中间结果
return (set1,set2)->{
set1.addAll(set2);return set1;
};
}
@Override
public Function<Set<T>, Set<T>> finisher() {//合并结果类型.结果容器
System.out.println("finisher invoked");
// return ts -> ts;
return Function.identity(); //底层是一样的. 同一性.
}
@Override
public Set<Characteristics> characteristics() {
System.out.println("charcteristics invoked ");
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH));
}
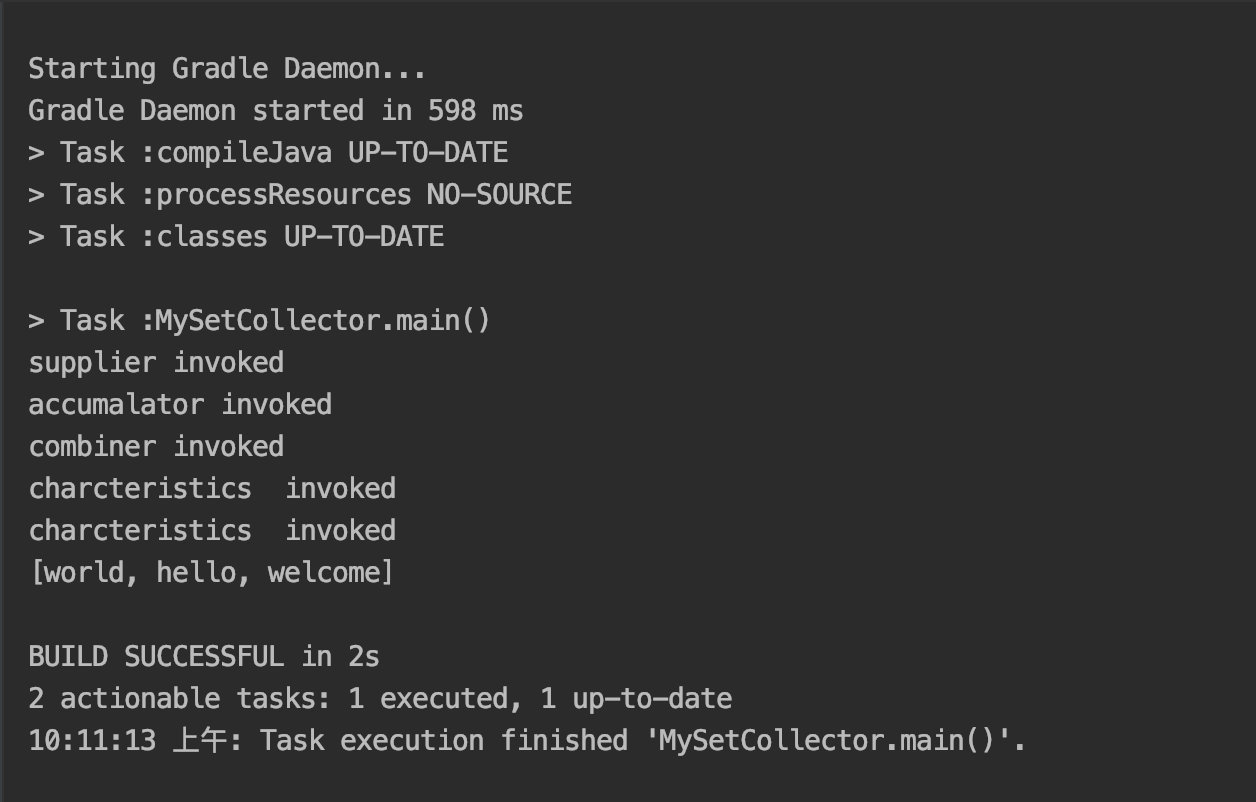
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome");
Set<String> collect = list.stream().collect(new MySetCollector<>());
System.out.println(collect);
}
}
从源码深入Collector
第一步:代码中调用collect()
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome");
Set<String> collect = list.stream().collect(new MySetCollector<>());
System.out.println(collect);
}第二步:collect()方法的实现类
@Override
@SuppressWarnings("unchecked")
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}IDENTITY_FINISH的字段特别重要,在这里使用
第三步: makeRef(), 逐步调用者三个函数式接口对象
public static <T, I> TerminalOp<T, I>
makeRef(Collector<? super T, I, ?> collector) {
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
BiConsumer<I, ? super T> accumulator = collector.accumulator();
BinaryOperator<I> combiner = collector.combiner();
class ReducingSink extends Box<I>
implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
state = supplier.get();
}
@Override
public void accept(T t) {
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED)
? StreamOpFlag.NOT_ORDERED
: 0;
}
};
}Collector的一些"坑"
使用这个案例去理解运作过程.
把一个set集合进行收集,我们对结果做一个增强.(原来是直接放在set当中了.)我们现在放在Map当中.
声明一个Collector类,要求.
- 输入:Set
- 输出:Map<String,String>
示例输入:["hello","world","hello world"]
示例输出:[{hello,hello},{world,world},{hello world,hello world}
泛型:<T,T,T>
彻底理解Characteristics.IDENTITY_FINISH属性
package com.dawa.jdk8.stream2;
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class MySetCollector2<T> implements Collector<T, Set<T>, Map<T,T>> {
@Override
public Supplier<Set<T>> supplier() {
System.out.println("supplier invoked");
return HashSet<T>::new;
}
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumulator invoked");
return Set::add;
}
@Override
public BinaryOperator<Set<T>> combiner() {
System.out.println("combiner invoked");
return (set1, set2) -> {
set1.addAll(set2);
return set1;
};
}
@Override
public Function<Set<T>, Map<T, T>> finisher() { //这里一定会被调用.因为结果类型和最终类型不同
//示例输入:["hello","world","hello world"]
//示例输出:[{hello,hello},{world,world},{hello world,hello world}
System.out.println("finisher invoked");
return set ->{
Map<T, T> map = new HashMap<>();
set.stream().forEach(item -> map.put(item, item));
return map;
};
}
@Override
public Set<Characteristics> characteristics() {
System.out.println("characteristics invoked");
return Collections.unmodifiableSet(EnumSet.of(Characteristics.UNORDERED));
}
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "hello", "welocome", "a", "b", "c", "d", "e");
HashSet<String> set = new HashSet<>(list);
System.out.println("set:"+list);
Map<String, String> collect = set.stream().collect(new MySetCollector2<>());
System.out.println(collect);
}
}如果多一个参数:
return Collections.unmodifiableSet(EnumSet.of(Characteristics.UNORDERED,Characteristics.IDENTITY_FINISH));则会出现类型转换异常.
/**
* Indicates that the finisher function is the identity function and
* can be elided. If set, it must be the case that an unchecked cast
* from A to R will succeed.
*/
IDENTITY_FINISH如果定义这个属性,则代表 indentity和 finish 是同一个类型的,要执行强制类型转换.所以会出现上述异常.
收集器是什么特性的,都是由这个Characteristics类来由你定义的.
所以你必须要理解你写的程序的类型.才能正确的使用这个枚举定义类.
彻底理解Characteristics.CONCURRENT属性
分支合并框架ForkJoinPoll(并行流)
对程序进行一定的改造,打印出相应的线程名称
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumulator invoked");
return (set,item)->{
System.out.println("accumulator:"+ Thread.currentThread().getName());
set.add(item);
};
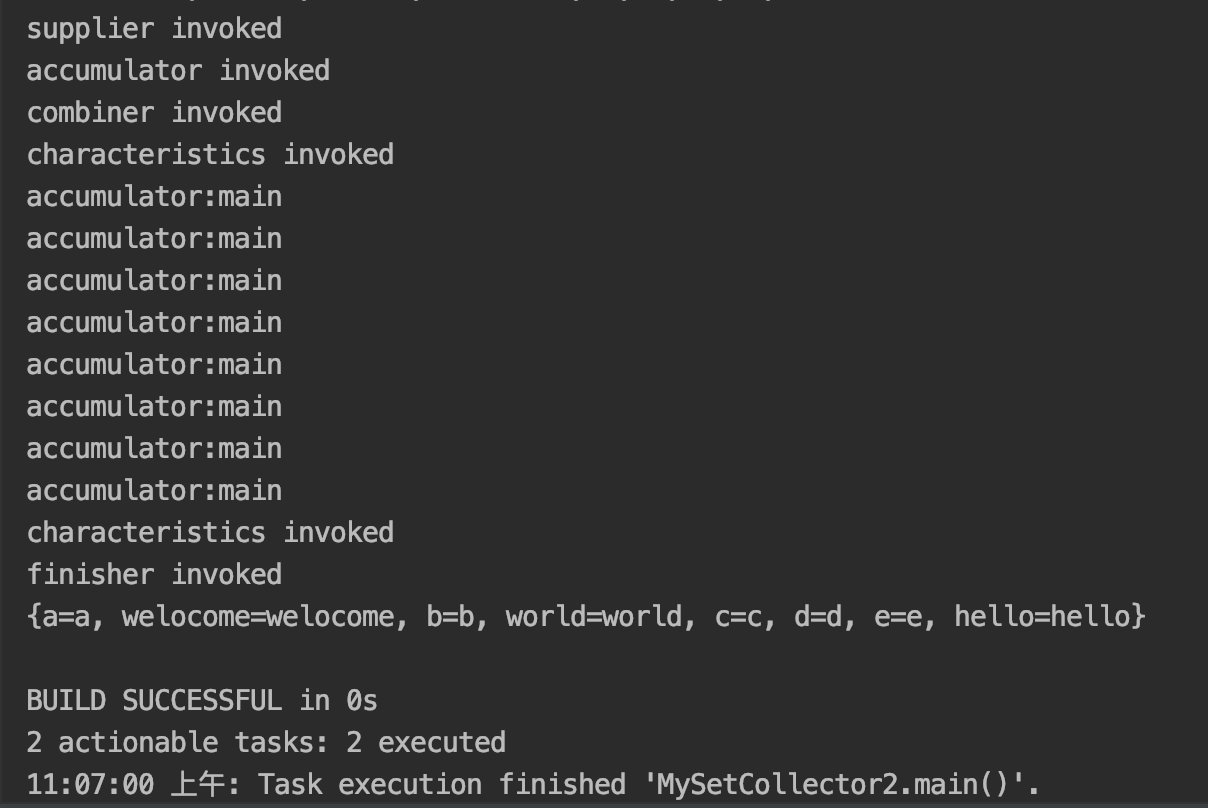
}- 串行情况下:
Map<String, String> collect = set.Stream().collect(new MySetCollector2<>());运行结果如下:
- 并行情况下
Map<String, String> collect = set.parallelStream().collect(new MySetCollector2<>());运行结果如下.

如果加上 Characteristics.CONCURRENT.
@Override
public Set<Characteristics> characteristics() {
System.out.println("characteristics invoked");
return Collections.unmodifiableSet(EnumSet.of(Characteristics.UNORDERED,Characteristics.CONCURRENT));
}则可能会出来一个异常
Caused by: java.util.ConcurrentModificationException如果不加 ,则不会出现异常
多执行几次,会有一定的发现.
查看属性的源码.
/**
* Indicates that this collector is <em>concurrent</em>, meaning that
* the result container can support the accumulator function being
* called concurrently with the same result container from multiple
* threads.
*
* <p>If a {@code CONCURRENT} collector is not also {@code UNORDERED},
* then it should only be evaluated concurrently if applied to an
* unordered data source.
*/
CONCURRENT,出现问题的原因:是在打印了set集合.
/**
* This exception may be thrown by methods that have detected concurrent
* modification of an object when such modification is not permissible.
* <p>
* For example, it is not generally permissible for one thread to modify a Collection
* while another thread is iterating over it. In general, the results of the
* iteration are undefined under these circumstances. Some Iterator
* implementations (including those of all the general purpose collection implementations
* provided by the JRE) may choose to throw this exception if this behavior is
* detected. Iterators that do this are known as <i>fail-fast</i> iterators,
* as they fail quickly and cleanly, rather that risking arbitrary,
* non-deterministic behavior at an undetermined time in the future.
* <p>
* Note that this exception does not always indicate that an object has
* been concurrently modified by a <i>different</i> thread. If a single
* thread issues a sequence of method invocations that violates the
* contract of an object, the object may throw this exception. For
* example, if a thread modifies a collection directly while it is
* iterating over the collection with a fail-fast iterator, the iterator
* will throw this exception.
*
* <p>Note that fail-fast behavior cannot be guaranteed as it is, generally
* speaking, impossible to make any hard guarantees in the presence of
* unsynchronized concurrent modification. Fail-fast operations
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>{@code ConcurrentModificationException}
* should be used only to detect bugs.</i>
*
* @author Josh Bloch
* @see Collection
* @see Iterator
* @see Spliterator
* @see ListIterator
* @see Vector
* @see LinkedList
* @see HashSet
* @see Hashtable
* @see TreeMap
* @see AbstractList
* @since 1.2
*/
public class ConcurrentModificationException extends RuntimeException {
}并发修改异常.
因为如果加上这个属性,那么这个就有一个结果集
并行的时候,会对set进行操作,但是你同时又在遍历打印, 两个赶到一起了.然后就会抛出这个异常.
这就是抛出这个异常的根本原因.
注意:如果是并行的话,千万要避免 打印遍历 你要操作的对象.
如果不加这个属性,那么combiner()方法的中间结果集就会被调用,所以就不会出现抢占资源的现象.
扩展: sequential() && parallerl()方法的调用.
Set<String> collect = list.stream().parallel().sequential().sequential().parallel().collect(new MySetCollector<>());只有最后一个会生效.
sequential()
/**
* Returns an equivalent stream that is sequential. May return
* itself, either because the stream was already sequential, or because
* the underlying stream state was modified to be sequential.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @return a sequential stream
*/
S sequential();parallerl()
/**
* Returns an equivalent stream that is parallel. May return
* itself, either because the stream was already parallel, or because
* the underlying stream state was modified to be parallel.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @return a parallel stream
*/
S parallel();关于Supplier()容器的定义.
修改代码.查看 串行 和并行的 区别.
@Override
public Supplier<Set<T>> supplier() {
System.out.println("supplier invoked");
// return HashSet<T>::new;// 返回一个HasHSet容器.
System.out.println("-----");
return HashSet::new;
}结论:串行的时候,会生成单个初始容器 / 并行的时候,会生成多个初始容器.
关于串行和并行的效率问题
并不是说串行的效率就一定比并行的效率低.这都是要看实际情况的.
最多会生成系统最大CPU核心
超线程技术
Collectors类方法详解
题外话:当你具备一些底层基础知识之后,你看一些东西会觉得是理所当然的.
如果你不具备这些知识的话,是看不懂的.云里雾里的.
关注一下JDK提供的方法是怎么实现的.对于Collectors静态工厂类来说,其实现一共分为两种方式.
- 通过CollectorImpl来实现
- 通过reducing来实现 (reducing本身又是通过CollectorImpl来实现)
所以,所有的方法都是通过CollectorImpl来实现的.
- 4个变量
static final Set<Collector.Characteristics> CH_CONCURRENT_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_CONCURRENT_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED));
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();- toCollection()方法
public static <T, C extends Collection<T>>
Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) {
return new CollectorImpl<>(collectionFactory, Collection<T>::add,
(r1, r2) -> { r1.addAll(r2); return r1; },
CH_ID);
}- toList()方法.是toCollection的一种特例.
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}- toSet()方法.是toCollection的一种特例.
public static <T>
Collector<T, ?, Set<T>> toSet() {
return new CollectorImpl<>((Supplier<Set<T>>) HashSet::new, Set::add,
(left, right) -> { left.addAll(right); return left; },
CH_UNORDERED_ID);
}- joining(): 融合成一个字符串. 此外,还有两个重载的.单参数的和多参数的.
public static Collector<CharSequence, ?, String> joining() {
return new CollectorImpl<CharSequence, StringBuilder, String>(
StringBuilder::new, StringBuilder::append,
(r1, r2) -> { r1.append(r2); return r1; },
StringBuilder::toString, CH_NOID);
}- mapping() 映射函数
public static <T, U, A, R>
Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper,
Collector<? super U, A, R> downstream) {
BiConsumer<A, ? super U> downstreamAccumulator = downstream.accumulator();
return new CollectorImpl<>(downstream.supplier(),
(r, t) -> downstreamAccumulator.accept(r, mapper.apply(t)),
downstream.combiner(), downstream.finisher(),
downstream.characteristics());
}collectingAndThen() 收集,并且做处理
原理:把IDENTITY_FINISH标识符给去掉.
为什么要去掉:不去掉的话,表示不会执行 finisher()方法.
public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,
Function<R,RR> finisher) {
Set<Collector.Characteristics> characteristics = downstream.characteristics();
if (characteristics.contains(Collector.Characteristics.IDENTITY_FINISH)) {
if (characteristics.size() == 1)
characteristics = Collectors.CH_NOID;
else {
characteristics = EnumSet.copyOf(characteristics);
characteristics.remove(Collector.Characteristics.IDENTITY_FINISH);
characteristics = Collections.unmodifiableSet(characteristics);
}
}
return new CollectorImpl<>(downstream.supplier(),
downstream.accumulator(),
downstream.combiner(),
downstream.finisher().andThen(finisher),
characteristics);
}- counting() 计算.
public static <T> Collector<T, ?, Long>
counting() {
return reducing(0L, e -> 1L, Long::sum);
}- minBy()
public static <T> Collector<T, ?, Optional<T>>
minBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.minBy(comparator));
}- maxBy()
public static <T> Collector<T, ?, Optional<T>>
maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}summingInt(),Long(),Double
为什么要用一个 int[1]? 最后还要返回一个数组中的单个数组呢?直接用一个数组行不行.
因为:不行,因为直接用数字,数字是不能被传递的. 数组本身是一个引用.是可以改变的.数组本身就是一个容器.
public static <T> Collector<T, ?, Integer>
summingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new int[1],
(a, t) -> { a[0] += mapper.applyAsInt(t); },
(a, b) -> { a[0] += b[0]; return a; },
a -> a[0], CH_NOID);
}- averagingInt(),Long(),Double
public static <T> Collector<T, ?, Double>
averagingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new long[2],
(a, t) -> { a[0] += mapper.applyAsInt(t); a[1]++; },
(a, b) -> { a[0] += b[0]; a[1] += b[1]; return a; },
a -> (a[1] == 0) ? 0.0d : (double) a[0] / a[1], CH_NOID);
}- reducing() 重点函数.
public static <T> Collector<T, ?, T>
reducing(T identity, BinaryOperator<T> op) {
return new CollectorImpl<>(
boxSupplier(identity),
(a, t) -> { a[0] = op.apply(a[0], t); },
(a, b) -> { a[0] = op.apply(a[0], b[0]); return a; },
a -> a[0],
CH_NOID);
}- groupingBy()方法的实现.(不支持并发)
public static <T, K> Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier) {
return groupingBy(classifier, toList());//调用下面2个参数的重载和toList()方法
} public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingBy(classifier, HashMap::new, downstream);//调用下面的三个参数的重载
}downstream下游. (接受一个,返回一个. 返回的就叫下游)
T:分类器函数,输入参数的类型.
K:分类器函数,返回的结果的类型.
D:返回的值的结果的类型.
HashMap::new :就是返回给客户的Map/
好处:为了给用户更好的使用.直接返回HashMap
坏处:局限了只能返回HashMap类型.
//groupBy函数的最底层实现.
/**
* Returns a {@code Collector} implementing a cascaded "group by" operation
* on input elements of type {@code T}, grouping elements according to a
* classification function, and then performing a reduction operation on
* the values associated with a given key using the specified downstream
* {@code Collector}. The {@code Map} produced by the Collector is created
* with the supplied factory function.
*
* <p>The classification function maps elements to some key type {@code K}.
* The downstream collector operates on elements of type {@code T} and
* produces a result of type {@code D}. The resulting collector produces a
* {@code Map<K, D>}.
*
* <p>For example, to compute the set of last names of people in each city,
* where the city names are sorted:
* <pre>{@code
* Map<City, Set<String>> namesByCity
* = people.stream().collect(groupingBy(Person::getCity, TreeMap::new,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If
* preservation of the order in which elements are presented to the downstream
* collector is not required, using {@link #groupingByConcurrent(Function, Supplier, Collector)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param <M> the type of the resulting {@code Map}
* @param classifier a classifier function mapping input elements to keys
* @param downstream a {@code Collector} implementing the downstream reduction
* @param mapFactory a function which, when called, produces a new empty
* {@code Map} of the desired type
* @return a {@code Collector} implementing the cascaded group-by operation
*
* @see #groupingBy(Function, Collector)
* @see #groupingBy(Function)
* @see #groupingByConcurrent(Function, Supplier, Collector)
*/
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A container = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(container, t);
};
BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory;
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<Map<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);
}
}参数分析:
1.分类器: 输入T类型,返回K类型 返回的Map的键,是K类型.
2.容器:HashMap
3.下游收集器: D为下游收集器的返回的类型.
方法逻辑分析.
- groupingByConcurrent() :(支持并发) (前提是你需要对顺序没有要求.)
public static <T, K>
Collector<T, ?, ConcurrentMap<K, List<T>>>
groupingByConcurrent(Function<? super T, ? extends K> classifier) {
return groupingByConcurrent(classifier, ConcurrentHashMap::new, toList());
}
//ConcurrentHashMap 实现起来支持并发.public static <T, K, A, D, M extends ConcurrentMap<K, D>>
Collector<T, ?, M> groupingByConcurrent(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BinaryOperator<ConcurrentMap<K, A>> merger = Collectors.<K, A, ConcurrentMap<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<ConcurrentMap<K, A>> mangledFactory = (Supplier<ConcurrentMap<K, A>>) mapFactory;
BiConsumer<ConcurrentMap<K, A>, T> accumulator;
//支持并发的同步的源码:
if (downstream.characteristics().contains(Collector.Characteristics.CONCURRENT)) {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(resultContainer, t);
};
}
else {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
synchronized (resultContainer) {//同步锁.
downstreamAccumulator.accept(resultContainer, t);
}
};
}
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_CONCURRENT_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<ConcurrentMap<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_CONCURRENT_NOID);
}
}- partitioningBy() 分区方法.()
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());//调用完全的重载方法.
}public static <T, D, A>
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream) {
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Partition<A>, T> accumulator = (result, t) ->
downstreamAccumulator.accept(predicate.test(t) ? result.forTrue : result.forFalse, t);
BinaryOperator<A> op = downstream.combiner();
BinaryOperator<Partition<A>> merger = (left, right) ->
new Partition<>(op.apply(left.forTrue, right.forTrue),
op.apply(left.forFalse, right.forFalse));
Supplier<Partition<A>> supplier = () ->
new Partition<>(downstream.supplier().get(),
downstream.supplier().get());
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(supplier, accumulator, merger, CH_ID);
}
else {
Function<Partition<A>, Map<Boolean, D>> finisher = par ->
new Partition<>(downstream.finisher().apply(par.forTrue),
downstream.finisher().apply(par.forFalse));
return new CollectorImpl<>(supplier, accumulator, merger, finisher, CH_NOID);
}
}自己提供的内部静态类:
/**
* Implementation class used by partitioningBy.
*/
private static final class Partition<T>
extends AbstractMap<Boolean, T>
implements Map<Boolean, T> {
final T forTrue;
final T forFalse;
Partition(T forTrue, T forFalse) {
this.forTrue = forTrue;
this.forFalse = forFalse;
}
@Override
public Set<Map.Entry<Boolean, T>> entrySet() {
return new AbstractSet<Map.Entry<Boolean, T>>() {
@Override
public Iterator<Map.Entry<Boolean, T>> iterator() {
Map.Entry<Boolean, T> falseEntry = new SimpleImmutableEntry<>(false, forFalse);
Map.Entry<Boolean, T> trueEntry = new SimpleImmutableEntry<>(true, forTrue);
return Arrays.asList(falseEntry, trueEntry).iterator();
}
@Override
public int size() {
return 2;
}
};
}
}...
Stream类
public interface Stream<T> extends BaseStream<T, Stream<T>> {}BaseStream类
package java.util.stream;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Collection;
import java.util.Iterator;
import java.util.Spliterator;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.IntConsumer;
import java.util.function.Predicate;
/**
* Base interface for streams, which are sequences of elements supporting
* sequential and parallel aggregate operations. The following example
* illustrates an aggregate operation using the stream types {@link Stream}
* and {@link IntStream}, computing the sum of the weights of the red widgets:
*
* <pre>{@code
* int sum = widgets.stream()
* .filter(w -> w.getColor() == RED)
* .mapToInt(w -> w.getWeight())
* .sum();
* }</pre>
*
* See the class documentation for {@link Stream} and the package documentation
* for <a href="package-summary.html">java.util.stream</a> for additional
* specification of streams, stream operations, stream pipelines, and
* parallelism, which governs the behavior of all stream types.
*
* @param <T> the type of the stream elements
* @param <S> the type of the stream implementing {@code BaseStream}
* @since 1.8
* @see Stream
* @see IntStream
* @see LongStream
* @see DoubleStream
* @see <a href="package-summary.html">java.util.stream</a>
*/
public interface BaseStream<T, S extends BaseStream<T, S>>
extends AutoCloseable {
/**
* Returns an iterator for the elements of this stream.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal
* operation</a>.
*
* @return the element iterator for this stream
*/
Iterator<T> iterator();
/**
* Returns a spliterator for the elements of this stream.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal
* operation</a>.
*
* @return the element spliterator for this stream
*/
Spliterator<T> spliterator();
/**
* Returns whether this stream, if a terminal operation were to be executed,
* would execute in parallel. Calling this method after invoking an
* terminal stream operation method may yield unpredictable results.
*
* @return {@code true} if this stream would execute in parallel if executed
*/
boolean isParallel();
/**
* Returns an equivalent stream that is sequential. May return
* itself, either because the stream was already sequential, or because
* the underlying stream state was modified to be sequential.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @return a sequential stream
*/
S sequential();
/**
* Returns an equivalent stream that is parallel. May return
* itself, either because the stream was already parallel, or because
* the underlying stream state was modified to be parallel.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @return a parallel stream
*/
S parallel();
/**
* Returns an equivalent stream that is
* <a href="package-summary.html#Ordering">unordered</a>. May return
* itself, either because the stream was already unordered, or because
* the underlying stream state was modified to be unordered.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @return an unordered stream
*/
S unordered();
/**
* Returns an equivalent stream with an additional close handler. Close
* handlers are run when the {@link #close()} method
* is called on the stream, and are executed in the order they were
* added. All close handlers are run, even if earlier close handlers throw
* exceptions. If any close handler throws an exception, the first
* exception thrown will be relayed to the caller of {@code close()}, with
* any remaining exceptions added to that exception as suppressed exceptions
* (unless one of the remaining exceptions is the same exception as the
* first exception, since an exception cannot suppress itself.) May
* return itself.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @param closeHandler A task to execute when the stream is closed
* @return a stream with a handler that is run if the stream is closed
*/
S onClose(Runnable closeHandler);
/**
* Closes this stream, causing all close handlers for this stream pipeline
* to be called.
*
* @see AutoCloseable#close()
*/
@Override
void close();
}
扩展:AutoCloseable接口
package java.lang;
/**
* An object that may hold resources (such as file or socket handles)
* until it is closed. The {@link #close()} method of an {@code AutoCloseable}
* object is called automatically when exiting a {@code
* try}-with-resources block for which the object has been declared in
* the resource specification header. This construction ensures prompt
* release, avoiding resource exhaustion exceptions and errors that
* may otherwise occur.
一个对象在关闭之前,会持有一些资源. 句柄之类的.
在退出块的时候,会自动调用close()
避免资源被耗尽等异常.
*
* @apiNote
* <p>It is possible, and in fact common, for a base class to
* implement AutoCloseable even though not all of its subclasses or
* instances will hold releasable resources. For code that must operate
* in complete generality, or when it is known that the {@code AutoCloseable}
* instance requires resource release, it is recommended to use {@code
* try}-with-resources constructions. However, when using facilities such as
* {@link java.util.stream.Stream} that support both I/O-based and
* non-I/O-based forms, {@code try}-with-resources blocks are in
* general unnecessary when using non-I/O-based forms.
*
* @author Josh Bloch
* @since 1.7
*/
public interface AutoCloseable {
/**
* Closes this resource, relinquishing any underlying resources.
* This method is invoked automatically on objects managed by the
* {@code try}-with-resources statement.
*
* <p>While this interface method is declared to throw {@code
* Exception}, implementers are <em>strongly</em> encouraged to
* declare concrete implementations of the {@code close} method to
* throw more specific exceptions, or to throw no exception at all
* if the close operation cannot fail.
*
* <p> Cases where the close operation may fail require careful
* attention by implementers. It is strongly advised to relinquish
* the underlying resources and to internally <em>mark</em> the
* resource as closed, prior to throwing the exception. The {@code
* close} method is unlikely to be invoked more than once and so
* this ensures that the resources are released in a timely manner.
* Furthermore it reduces problems that could arise when the resource
* wraps, or is wrapped, by another resource.
*
* <p><em>Implementers of this interface are also strongly advised
* to not have the {@code close} method throw {@link
* InterruptedException}.</em>
*
* This exception interacts with a thread's interrupted status,
* and runtime misbehavior is likely to occur if an {@code
* InterruptedException} is {@linkplain Throwable#addSuppressed
* suppressed}.
*
* More generally, if it would cause problems for an
* exception to be suppressed, the {@code AutoCloseable.close}
* method should not throw it.
*
* <p>Note that unlike the {@link java.io.Closeable#close close}
* method of {@link java.io.Closeable}, this {@code close} method
* is <em>not</em> required to be idempotent. In other words,
* calling this {@code close} method more than once may have some
* visible side effect, unlike {@code Closeable.close} which is
* required to have no effect if called more than once.
*
* However, implementers of this interface are strongly encouraged
* to make their {@code close} methods idempotent.
*
* @throws Exception if this resource cannot be closed
*/
void close() throws Exception;
}
使用Example去理解这个接口
public class AutoCloseableTest implements AutoCloseable {
public static void main(String[] args) {
try(AutoCloseableTest autoCloseableTest = new AutoCloseableTest()) {
autoCloseableTest.doSomething();
} catch (Exception e) {
e.printStackTrace();
} //这种写法.try with source.
}
@Override
public void close() throws Exception {
System.out.println("close invoked");
}
public void doSomething(){
System.out.println("doSomething invoked");
}
}运行结果: (实现了这个接口的类,会自动执行 close()方法.)

总结:
- JDK内置的函数式接口在这里得以体现.
看底层的原因:
不是因为要让你开发过程中去
看了源码之后,你使用的时候的信心就非常足.
在遇到问题的时候,你能快速的将问题fix掉.
学习方法
1.看优秀的代码
2.去学习别人的东西
3.用的多了就会变成自己的东西.
附加一个小插曲
加载全部内容