详解MySQL8.0 字典表增强
MySQL轻松学 人气:0MySQL中数据字典是数据库重要的组成部分之一,INFORMATION_SCHEMA首次引入于MySQL 5.0,作为一种从正在运行的MySQL服务器检索元数据的标准兼容方式。用于存储数据元数据、统计信息、以及有关MySQL server的访问信息(例如:数据库名或表名,字段的数据类型和访问权限等)。
8.0之前:
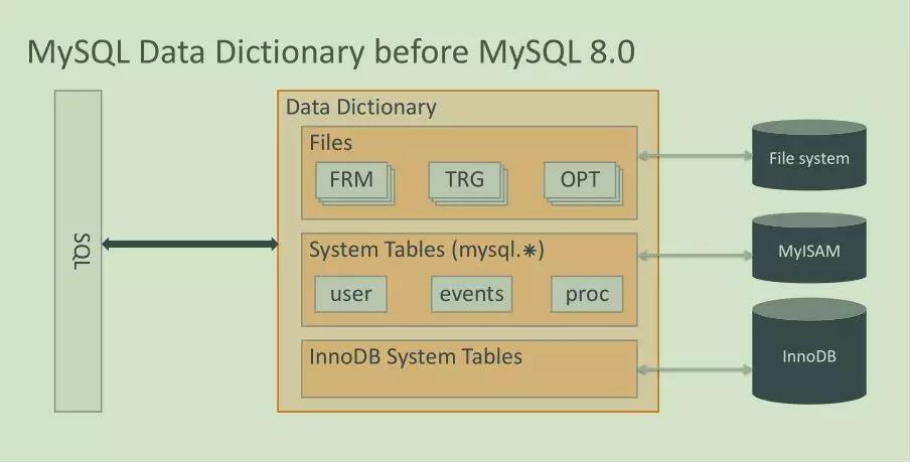
1、元数据来自文件
2、采用MEMORY表引擎
3、frm文件 存放表结构信息
4、opt文件,记录了每个库的一些基本信息,包括库的字符集等信息
5、.TRN,.TRG文件用于存放触发器的信息内容
5.6> SELECT TABLE_SCHEMA ,ENGINE ,COUNT(*) from information_schema.tables where table_schema in ('information_schema' ,'mysql','performance_schema', 'sys') group by TABLE_SCHEMA ,ENGINE;
+--------------------+--------------------+----------+
| TABLE_SCHEMA | ENGINE | COUNT(*) |
+--------------------+--------------------+----------+
| information_schema | MEMORY | 49 |
| information_schema | MyISAM | 10 |
| mysql | CSV | 2 |
| mysql | InnoDB | 6 |
| mysql | MyISAM | 21 |
| performance_schema | PERFORMANCE_SCHEMA | 52 |
+--------------------+--------------------+----------+
5.7> SELECT TABLE_SCHEMA ,ENGINE ,COUNT(*) from information_schema.tables where table_schema in ('information_schema' ,'mysql','performance_schema', 'sys') group by TABLE_SCHEMA ,ENGINE;
+--------------------+--------------------+----------+
| TABLE_SCHEMA | ENGINE | COUNT(*) |
+--------------------+--------------------+----------+
| information_schema | InnoDB | 10 |
| information_schema | MEMORY | 51 |
| mysql | CSV | 2 |
| mysql | InnoDB | 19 |
| mysql | MyISAM | 10 |
| performance_schema | PERFORMANCE_SCHEMA | 87 |
| sys | NULL | 100 |
| sys | InnoDB | 1 |
+--------------------+--------------------+----------+
8.0之后:
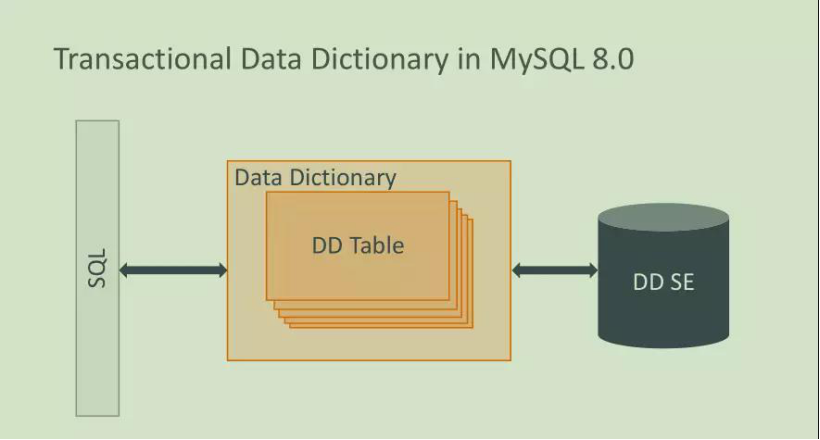
1、元数据存在表中
2、全部迁到mysql库下,改为innodb表引擎,且被隐藏
3、information_schema下只能通过view查看
4、NULL的全部为view
5、存储在单独的表空间mysql.ibd
8.0> select TABLE_SCHEMA,ENGINE,count(*) from tables where TABLE_SCHEMA in ('information_schema','mysql','performance_schema','sys') group by TABLE_SCHEMA,ENGINE;
+--------------------+--------------------+----------+
| TABLE_SCHEMA | ENGINE | count(*) |
+--------------------+--------------------+----------+
| information_schema | NULL | 65 |
| mysql | InnoDB | 31 |
| mysql | CSV | 2 |
| performance_schema | PERFORMANCE_SCHEMA | 102 |
| sys | NULL | 100 |
| sys | InnoDB | 1 |
+--------------------+--------------------+----------+
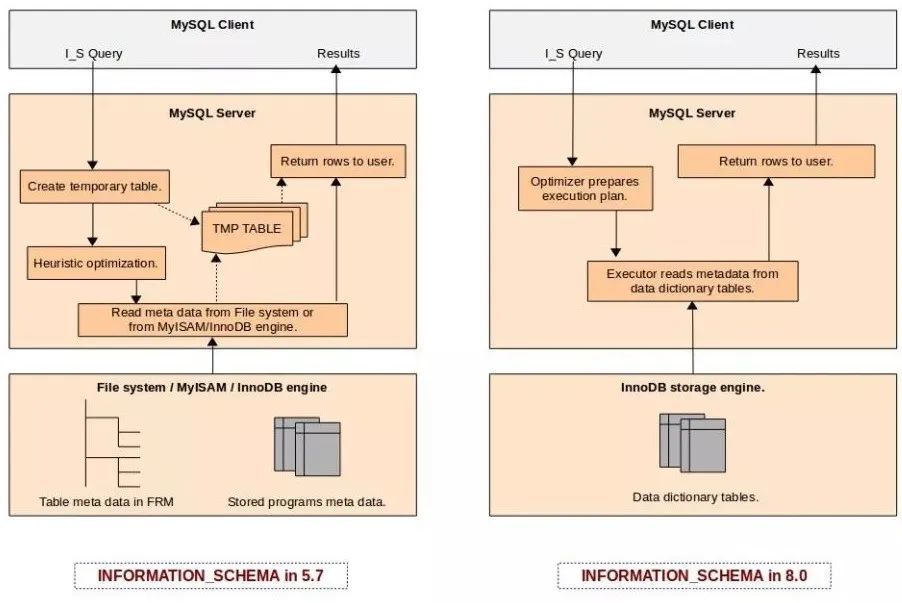
尽管5.7有了一些改进,但INFORMATION_SCHEMA的性能仍然是我们许多用户的主要痛点。在当前INFORMATION_SCHEMA实现方式下产生的性能问题背后的关键原因是,INFORMATION_SCHEMA表的查询实现方式是在查询执行期间创建临时表。
如下,当我们查询表碎片时:
5.7> explain select round(DATA_FREE/1024/1024) as DATA_FREE from information_schema.TABLES where DATA_FREE/1024/1024 > 1024 and TABLE_SCHEMA not in ('information_schema', 'mysql', 'performance_schema', 'sys');
+----+-------------+--------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| 1 | SIMPLE | TABLES | ALL | NULL | NULL | NULL | NULL | NULL | Using where; Open_full_table; Scanned all databases |
+----+-------------+--------+------+---------------+------+---------+------+------+-----------------------------------------------------+
Extra信息会有Open_full_table; Scanned all databases 。
Skip_open_table,Open_frm_only,Open_full_table这些值表示适用于INFORMATION_SCHEMA表查询时对文件打开的优化;
- Skip_open_table:表文件不需要打开。信息已经通过扫描数据库目录在查询中实现可用。
- Open_frm_only:只需要打开表的.frm文件。
- Open_full_table:未优化的信息查找。必须打开.frm、.MYD和.MYI文件。
- Scanned N databases:指在处理information_schema查询时,有多少目录需要扫描。
如果一个MySQL实例有上百个库,每个库又有上百张表,INFORMATION_SCHEMA查询最终会从文件系统中读取每个单独的frm文件,造成很多I/O读取。并且最终还会消耗更多的CPU来打开表并准备相关的内存数据结构。它也确实会尝试使用MySQL server层的表缓存(系统变量table_definition_cache ),但是在大型实例中,很少有一个足够大的表缓存来容纳所有的表。所以内存使用量会急剧上升,甚至出现oom。

通常我们习惯通过以下手段解决此问题:
1、库表拆分,减少单实例打开文件数量
2、调整table_definition_cache和table_open_cache数量
3、添加物理内存
mysql 8.0 问世之后,又提供了一种选择,由于字典表采用innodb引擎,而且字典表可以使用索引。
下面的图解释了MySQL 5.7和8.0设计上的区别:
8.0> explain select table_name,table_rows,concat(round(DATA_LENGTH/1024/1024, 2), 'MB') as size,concat(round(INDEX_LENGTH/1024/1024, 2), 'MB') as index_size,DATA_FREE/1024/1024 AS data_free_MB from information_schema.TABLES where table_schema not in ('information_schema','performance_schema','test') order by data_free_MB desc limit 10;
+----+-------------+-------+------------+--------+--------------------+------------+---------+-------------------------------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+--------------------+------------+---------+-------------------------------+------+----------+----------------------------------------------+
| 1 | SIMPLE | cat | NULL | index | PRIMARY | name | 194 | NULL | 1 | 100.00 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | sch | NULL | ref | PRIMARY,catalog_id | catalog_id | 8 | mysql.cat.id | 6 | 50.00 | Using where; Using index |
| 1 | SIMPLE | tbl | NULL | ref | schema_id | schema_id | 8 | mysql.sch.id | 52 | 100.00 | Using where |
| 1 | SIMPLE | ts | NULL | eq_ref | PRIMARY | PRIMARY | 8 | mysql.tbl.tablespace_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | stat | NULL | eq_ref | PRIMARY | PRIMARY | 388 | mysql.sch.name,mysql.tbl.name | 1 | 100.00 | NULL |
| 1 | SIMPLE | col | NULL | eq_ref | PRIMARY | PRIMARY | 8 | mysql.tbl.collation_id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+--------+--------------------+------------+---------+-------------------------------+------+----------+----------------------------------------------+
加载全部内容