MySQL去重该使用distinct还是group by?
泽阳君 人气:0前言
关于group by 与distinct 性能对比:网上结论如下,不走索引少量数据distinct性能更好,大数据量group by 性能好,走索引group by性能好。走索引时分组种类少distinct快。关于网上的结论做一次验证。
准备阶段屏蔽查询缓存
查看MySQL中是否设置了查询缓存。为了不影响测试结果,需要关闭查询缓存。
show variables like '%query_cache%';

查看是否开启查询缓存决定于query_cache_type和query_cache_size。
- 方法一:关闭查询缓存需要找到my.ini,修改
query_cache_type需要修改C:\ProgramData\MySQL\MySQL Server 5.7\my.ini配置文件,修改query_cache_type=0或2。 - 方法二:设置
query_cache_size为0,执行以下语句。
set global query_cache_size = 0;
方法三:如果你不想关闭查询缓存,也可以在使用RESET QUERY CACHE。
现在测试环境中query_cache_type=2代表按需进行查询缓存,默认的查询方式是不会进行缓存,如需缓存则需要在查询语句中加上sql_cache。
数据准备
t0表存放10W少量种类少的数据
drop table if exists t0; create table t0( id bigint primary key auto_increment, a varchar(255) not null ) engine=InnoDB default charset=utf8mb4 collate=utf8mb4_bin; 1 2 3 4 5 drop procedure insert_t0_simple_category_data_sp; delimiter // create procedure insert_t0_simple_category_data_sp(IN num int) begin set @i = 0; while @i < num do insert into t0(a) value(truncate(@i/1000, 0)); set @i = @i + 1; end while; end // call insert_t0_simple_category_data_sp(100000);
t1表存放1W少量种类多的数据
drop table if exists t1; create table t1 like t0; 1 2 drop procedure insert_t1_complex_category_data_sp; delimiter // create procedure insert_t1_complex_category_data_sp(IN num int) begin set @i = 0; while @i < num do insert into t1(a) value(truncate(@i/10, 0)); set @i = @i + 1; end while; end // call insert_t1_complex_category_data_sp(10000);
t2表存放500W大量种类多的数据
drop table if exists t2; create table t2 like t1; 1 2 drop procedure insert_t2_complex_category_data_sp; delimiter // create procedure insert_t2_complex_category_data_sp(IN num int) begin set @i = 0; while @i < num do insert into t1(a) value(truncate(@i/10, 0)); set @i = @i + 1; end while; end // call insert_t2_complex_category_data_sp(5000000);
测试阶段
验证少量种类少数据
未加索引
set profiling = 1; select distinct a from t0; show profiles; select a from t0 group by a; show profiles; alter table t0 add index `a_t0_index`(a);

由此可见:少量种类少数据下,未加索引,distinct和group by性能相差无几。
加索引
alter table t0 add index `a_t0_index`(a);
执行上述类似查询后
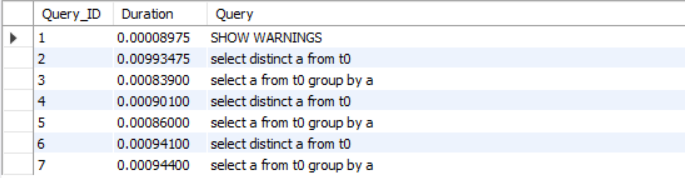
由此可见:少量种类少数据下,加索引,distinct和group by性能相差无几。
验证少量种类多数据未加索引
执行上述类似未加索引查询后

由此可见:少量种类多数据下,未加索引,distinct比group by性能略高,差距并不大。
加索引
alter table t1 add index `a_t1_index`(a);
执行类似未加索引查询后

由此可见:少量种类多数据下,加索引,distinct和group by性能相差无几。
验证大量种类多数据
未加索引
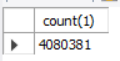
SELECT count(1) FROM t2;
执行上述类似未加索引查询后
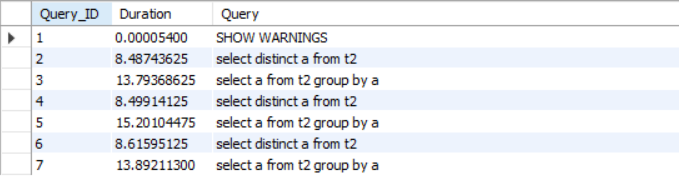
由此可见:大量种类多数据下,未加索引,distinct比group by性能高。
加索引
alter table t2 add index `a_t2_index`(a);
执行上述类似加索引查询后
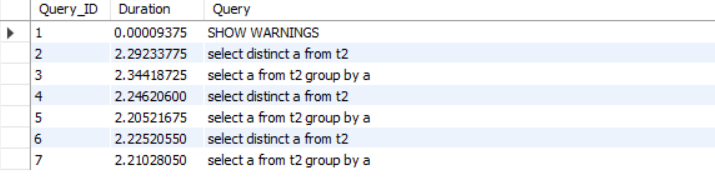
由此可见:大量种类多数据下,加索引,distinct和group by性能相差无几。
总结
去重场景下,未加索引时,更偏向于使用distinct,而加索引时,distinct和group by两者都可以使用。
总结
加载全部内容