细说MySQL死锁与日志二三事
人气:0最近线上 MySQL 接连发生了几起数据异常,都是在凌晨爆发,由于业务场景属于典型的数据仓库型应用,白天压力较小无法复现。甚至有些异常还比较诡异,最后 root cause 分析颇费周折。那实际业务当中咱们如何能快速的定位线上 MySQL 问题,修复异常呢?下文我会根据两个实际 case,分享下相关的经验与方法。
Case1:部分数据更新失败
某天渠道同学反馈某报表极个别渠道数据为 0,大部分渠道数据正常。这个数据是由一个统计程序每天凌晨例行更新的,按理来说,要么全部正常,要么全部失败,那会是什么原因导致极个别数据异常呢?
首先我们能想到的自然是根据统计任务日志来看了,但是看了统计程序打印的日志没有发现诸如 SQL update 失败的异常描述,那当时的数据库究竟发生了什么呢?在查看 MySQL-server 日志之前,习惯性的看了下数据库状态:

恰好看到了凌晨这个 update 发生了死锁:

篇幅所限,上下文我这里省略了很多,从这段日志里可以看到,TRANSACTION 1 和 TRANSACTION 2 分别持有一定数量的行锁,然后又等待对方的锁,最后 MySQL 检测到 deadlock ,然后选择回滚了 TRANSACTION 1:Innodb目前处理死锁的方法是将持有最少行级排他锁的事务进行回滚。
那这里就有 3 个问题了:
1、innodb 行锁不是只锁一行?
因为这张表是 innodb 引擎的,InnoDB 支持行锁和表锁。而InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁,会把所有扫描过的行都锁定!在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;另外间隙锁也会锁多行,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!
话都说到这了,那就看下咱们业务表的索引情况:

可以看到这张表的索引极不合理:有3个索引,但是 update 却没有完全的用上索引,导致 update 没有精确的用上索引,需要锁定多行范围数据,从而引发死锁。
知道原理后,咱们再精心构建一个四字段的组合索引即可让 update 精准的走 innodb 索引,实际上,我们更新索引后,这个死锁问题即得到了解决。
注:innodb不仅会打印出事务和事务持有和等待的锁,而且还有记录本身,不幸的是,它可能超过innodb为输出结果预留的长度(只能打印1M的内容且只能保留最近一次的死锁信息),如果你无法看到完整的输出,此时可以在任意库下创建innodb_monitor或innodb_lock_monitor表,这样innodb status信息会完整且每15s一次被记录到错误日志中。如:create table innodb_monitor(a int)engine=innodb;,不需要记录到错误日志中时就删掉这个表即可。
2、回滚为什么只有部分 update 语句失败
回滚的话,为什么只有部分 update 语句失败,而不是整个事务里的所有 update 都失败?
这是因为咱们的 innodb 默认是自动提交的:

在多个 update 或 insert 语句情况下,每执行完一条 SQL,innodb 就立即 commit 一次以持久化变更,同时释放锁,这也正是本例中死锁回滚事务后只有极个别语句失败的原因。
需要注意的是,通常还有另外一种情况也可能导致部分语句回滚,需要格外留意。在 innodb 里有个参数叫:innodb_rollback_on_timeout

官方手册里这样描述:
In MySQL 5.1, InnoDB rolls back only the last statement on a transaction timeout by default. If –innodb_rollback_on_timeout is specified, a transaction timeout causes InnoDB to abort and roll back the entire transaction (the same behavior as in MySQL 4.1). This variable was added in MySQL 5.1.15.
解释:这个参数关闭或不存在的话遇到超时只回滚事务最后一个Query,打开的话事务遇到超时就回滚整个事务。
3、怎样降低 innodb 死锁几率?
死锁在行锁及事务场景下很难完全消除,但可以通过表设计和SQL调整等措施减少锁冲突和死锁,包括:
尽量使用较低的隔离级别,比如如果发生了间隙锁,你可以把会话或者事务的事务隔离级别更改为 RC(read committed)级别来避免,但此时需要把 binlog_format 设置成 row 或者 mixed 格式
精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会;
选择合理的事务大小,小事务发生锁冲突的几率也更小;
给记录集显示加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁;
不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响;
不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁;
对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。
Case2:诡异的 Lock wait timeout
连续几天凌晨6点和早上8点 都分别有一个任务失败,load data local infile 的时候报 Lock wait timeout exceeded try restarting transaction innodb 的 Java SQL 异常,和平台的同学沟通得知,这是我们自己的业务数据库的 Lock 时间太短或者锁冲突的问题。但是回头一想不应该啊?这不一直好好的吗?而且基本都是单表单任务,不存在多人冲突。
甭管谁的问题,那咱们还是先看自己的数据库有没有问题:

默认 lock 超时时间 50s,这个时间真心不短了,估计调了也没用,事实上确实死马当活马医的试了下没用。。。
而且这次 SHOW ENGINE INNODB STATUS\G 也没出现任何死锁信息,然后又将目光转向 MySQL-server 日志,希望能从日志里看一看那个时刻前后数据究竟在做什么操作。这里先简单的介绍下MySQL日志文件系统的组成:
(a) error 日志:记录启动、运行或停止 mysqld 时出现的问题,默认开启。
(b) general 日志:通用查询日志,记录所有语句和指令,开启数据库会有 5% 左右性能损失。
(c) binlog 日志:二进制格式,记录所有更改数据的语句,主要用于 slave 复制和数据恢复。
(d) slow 日志:记录所有执行时间超过 long_query_time 秒的查询或不使用索引的查询,默认关闭。
(e) Innodb日志:innodb redo log、undo log,用于恢复数据和撤销操作。
从上面的介绍可以看到,目前这个问题的日志可能在 d 和 b 中,看了下 d 中没有,那就只能开启 b 了,但 b 对数据库的性能有一定损耗,由于是全量日志,量非常巨大,所以开启一定要谨慎:

我这里只是每天在出问题的前后半小时开启下全量日志,结果没有发现任何 MySQL-client 请求到我们的业务数据库!该日志格式如下,记录了所有的连接与命令:

那问题基本确定了,客户端请求都没到我们这边就抛出了上述的异常,和平台方再三沟通确认下,最后平台方查证是因为在执行插入前他们需要先从 SQL task 表取出 SQL 和更新 task 状态,结果这张表由于在整点存在大量 insert 和 update 并发,导致部分 SQL 等待 lock 超时了。。。
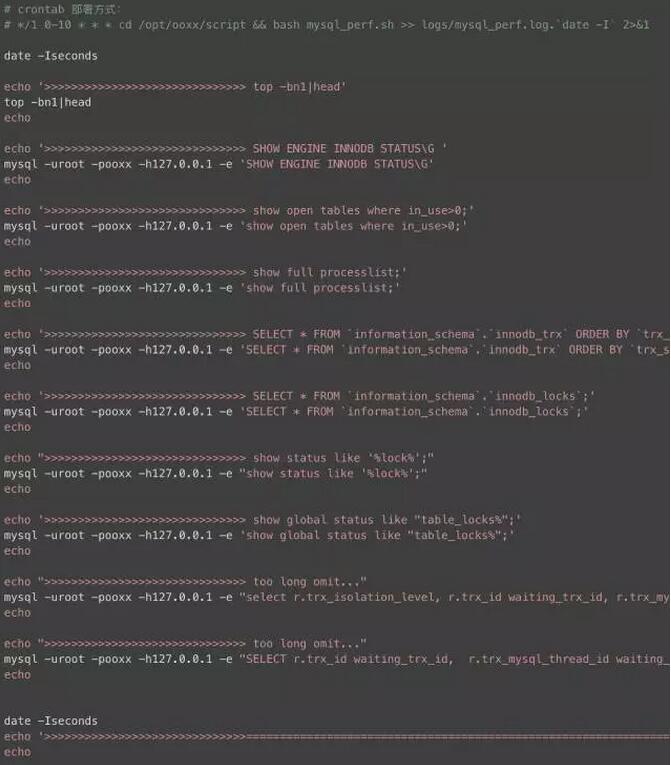
MySQL 日志分析脚本
由于凌晨是数据仓库的业务高峰,很多问题都是在这个时候爆发,一些诡异的问题往往是过了这个村就没这个店了,白天无法复现。如何能捕获我们关心的日志,便于快速的定位问题,这个是重中之重,这里我写了个小脚本,crontab 部署,可以选择时间范围开启,每分钟采样一次日志,需要说明的是 general log 没事别轻易开启,否则对数据库性能损耗较大。



加载全部内容