node多进程的创建与守护
蚊子博客 人气:1node是单线程运行,我们的node项目如何利用多核CPU的资源,同时提高node服务的稳定性呢?
1. node的单线程
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
线程是程序执行中一个单一的顺序控制流,它存在于进程之中,是比进程更小的能独立运行的基本单位。
早期在单核 CPU 的系统中,为了实现多任务的运行,引入了进程的概念,不同的程序运行在数据与指令相互隔离的进程中,通过时间片轮转调度执行,由于 CPU 时间片切换与执行很快,所以看上去像是在同一时间运行了多个程序。
由于进程切换时需要保存相关硬件现场、进程控制块等信息,所以系统开销较大。为了进一步提高系统吞吐率,在同一进程执行时更充分的利用 CPU 资源,引入了线程的概念。线程是操作系统调度执行的最小单位,它们依附于进程中,共享同一进程中的资源,基本不拥有或者只拥有少量系统资源,切换开销极小。
Node是基于V8引擎之上构建的,决定了他与浏览器的机制很类似。
一个node进程只能利用一个核,而且node只能运行在单线程中,严格意义上,node并非真正的单线程架构,即一个进程内可以有多个线程,因为node自己还有一定的i/o线程存在,这些I/O线程由底层的libuv处理,但这些线程对node开发者而言是完成透明的,只有在C++扩展时才会用到,这里我们就屏蔽底层的细节,专门讨论我们所要关注的。

单线程的好处是:程序状态单一,在没有多线程的情况下,没有锁、线程同步问题,操作系统在调度时,也因为较少的上下文的切换,可以很好地提高CPU的使用率。然而单核单线程也有相应的缺点:
- 这个线程挂掉后整个程序就会挂掉;
- 无法充分利用多核资源

2. node多进程的创建
node中有提供child_process模块,这个模块中,提供了多个方法来创建子进程。
const { spawn, exec, execFile, fork } = require('child_process');这4个方法都可以创建子进程,不过使用方法还是稍微有点区别。我们以创建一个子进程计算斐波那契数列数列为例,子进程的文件(worker.js):
// worker.js
const fib = (num) => {
if (num === 1 || num === 2) {
return num;
}
let a = 1, b = 2, sum = 0;
for (let i = 3; i <= num; i++) {
sum = a + b;
a = b;
b = sum;
}
return sum;
}
const num = Math.floor(Math.random() * 10) + 3;
const result = fib(num);
console.log(num, result, process.pid); // process.pid表示当前的进程id在master.js中如何调用这些方法创建子进程呢?
| 命令 | 使用方法 | 解析 |
|---|---|---|
| spawn | spawn('node', ['worker.js']) | 启动一个字进程来执行命令 |
| exec | exec('node worker.js', (err, stdout, stderr) => {}) | 启动一个子进程来执行命令,有回调 |
| execFile | exexFile('worker.js') | 启动一个子进程来执行可执行的文件 (头部要添加#!/usr/bin/env node) |
| fork | fork('worker.js') | 与spawn类似,不过这里只需要自定js文件模块即可 |
以fork命令为例:
const { fork } = require('child_process');
const cpus = require('os').cpus();
for(let i=0, len=cpus.length; i<len; i++) {
fork('./worker.js');
}3. 多进程之间的通信
node中进程的通信主要在主从(子)进程之间进行通信,子进程之间无法直接通信,若要相互通信,则要通过主进程进行信息的转发。
主进程和子进程之间是通过IPC(Inter Process Communication,进程间通信)进行通信的,IPC也是由底层的libuv根据不同的操作系统来实现的。
我们还是以计算斐波那契数列数列为例,在这里,我们用cpu个数减1个的进程来进行计算,剩余的那一个用来输出结果。这就需要负责计算的子进程,要把结果传给主进程,再让主进程传给输出进行,来进行输出。这里我们需要3个文件:
- master.js:用来创建子进程和子进程间的通信;
- fib.js:计算斐波那契数列;
- log.js:输出斐波那契数列计算的结果;
主进程:
// master.js
const { fork } = require('child_process');
const cpus = require('os').cpus();
const logWorker = fork('./log.js');
for(let i=0, len=cpus.length-1; i<len; i++) {
const worker = fork('./fib.js');
worker.send(Math.floor(Math.random()*10 + 4)); // 要计算的num
worker.on('message', (data) => { // 计算后返回的结果
logWorker.send(data); // 将结果发送给输出进程
})
}计算进程:
// fib.js
const fib = (num) => {
if (num===1 || num===2) {
return num;
}
let a=1, b=2, sum=0;
for(let i=3; i<num; i++) {
sum = a + b;
a = b;
b = sum;
}
return sum;
}
process.on('message', num => {
const result = fib(num);
process.send(JSON.stringify({
num,
result,
pid: process.pid
}))
})输出进程:
process.on('message', data => {
console.log(process.pid, data);
})当我们运行master时,就能看到各个子进程计算的结果:
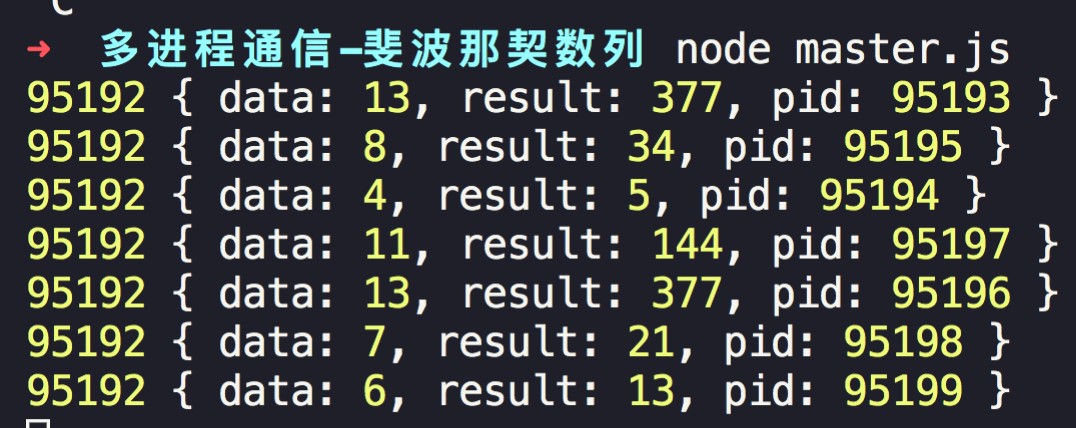
第1个数字表示当前输出子进程的编号,后面表示在各个子进程计算的数据。
同理,我们在进行http服务日志记录时,也可以采用类似的思路,多个子进程承担http服务,剩下的子进程来进行日志记录等操作。
当我想用子进程创建服务器时,采用上面类似斐波那契数列的思路,将fib.js改为httpServer.js:
// httpServer.js
const http = require('http');
http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/html'
});
res.end(Math.random()+'');
}).listen(8080);
console.log('http server has started at 8080, pid: '+process.pid);结果却出现错误了,提示8080端口已经被占用了:
Error: listen EADDRINUSE: address already in use :::8080这是因为:在TCP端socket套接字监听端口有一个文件描述符,每个进程的文件描述符都不相同,监听相同端口时就会失败。
解决方案有两种:首先最简单的就是每个子进程都使用不同的端口,主进程将循环的标识给子进程,子进程通过这个标识来使用相关的端口(例如从8080+传入的标识作为当前进程的端口号)。
第二种方案是,在主进程进行端口的监听,然后将监听的套接字传给子进程。
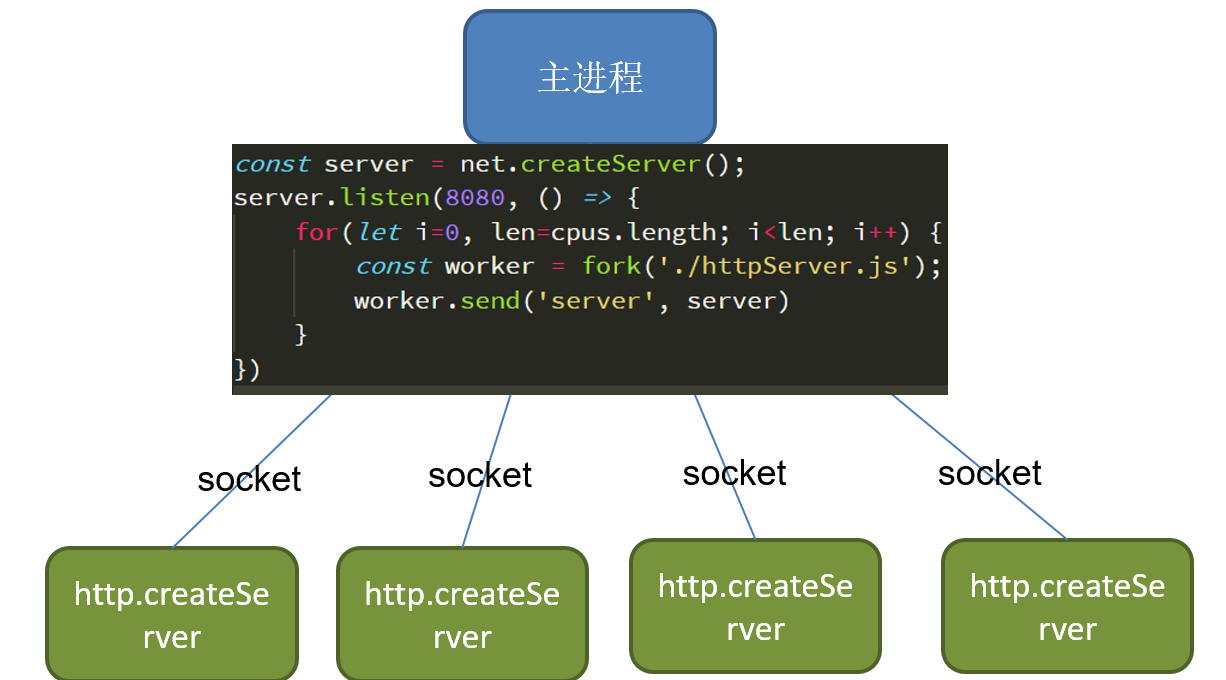
主进程:
// master.js
const fork = require('child_process').fork;
const net = require('net');
const server = net.createServer();
const child1 = fork('./httpServer1.js'); // random
const child2 = fork('./httpServer2.js'); // now
server.listen(8080, () => {
child1.send('server', server);
child2.send('server', server);
server.close();
})httpServer1.js:
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end(Math.random()+', at pid: ' + process.pid);
});
process.on('message', (type, tcp) => {
if (type==='server') {
tcp.on('connection', socket => {
server.emit('connection', socket)
})
}
})httpServer2.js:
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end(Date.now()+', at pid: ' + process.pid);
});
process.on('message', (type, tcp) => {
if (type==='server') {
tcp.on('connection', socket => {
server.emit('connection', socket)
})
}
})我们的2个server,一个是输出随机数,一个是输出当前的时间戳,可以发现这两个server都可以正常的运行。同时,因为这些进程服务是抢占式的,哪个进程抢到连接,就哪个进程处理请求。
我们也应当知道的是:
每个进程之间的内存数据是不互通的,若我们在某一进程中使用变量缓存了数据,另一个进程是读取不到的。
4. 多进程的守护
刚才我们在第3部分创建的多进程,解决了多核CPU利用率的问题,接下来要解决进程稳定的问题。
每个子进程退出时,都会触发exit事件,因此我们通过监听exit事件来获知有进程退出了,这时,我们就可以创建一个新的进程来替代。
const fork = require('child_process').fork;
const cpus = require('os').cpus();
const net = require('net');
const server = net.createServer();
const createServer = () => {
const worker = fork('./httpServer.js');
worker.on('exit', () => {
// 当有进程退出时,则创建一个新的进程
console.log('worker exit: ' + worker.pid);
createServer();
});
worker.send('server', server);
console.log('create worker: ' + worker.pid);
}
server.listen(8080, () => {
for(let i=0, len=cpus.length; i<len; i++) {
createServer();
}
})cluster模块
在多进程守护这块,node也推出了cluster模块,用来解决多核CPU的利用率问题。同时cluster中也提供了exit事件来监听子进程的退出。
一个经典的案例:
const cluster = require('cluster');
const http = require('http');
const cpus = require('os').cpus();
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 衍生工作进程。
for (let i = 0, len=cpus.length; i < len; i++) {
cluster.fork();
}
cluster.on('exit', (worker) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
cluster.fork();
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(Math.random()+ ', at pid: ' + process.pid);
}).listen(8080);
console.log(`工作进程 ${process.pid} 已启动`);
}5. 总结
node虽然是单线程运行的,但我们可以通过创建多个子进程,来充分利用多核CPU资源,通过可以监听进程的一些事件,来感知每个进程的运行状态,来提高我们项目整体的稳定性。
欢迎关注我的公众号,查阅更多的前端文章:

加载全部内容