大规模机器集群-故障自动处理(二)
曲行人 人气:1本篇开始介绍具体的实现过程,为表述方便,先定义一些名词,
-
AutoRepairSystem: 故障自动维修系统, 缩写为ARS
-
原子操作:任务的最小操作,机器任务通常是指重启、重装
-
运维人员:运维工程师= SRE = OP,系统工程师 = sys
-
远程管理工具: 远程控制操作物理机器的工具,如ipmi、ilo
先来看ARS的整体视图和流程图,



ARS的工作流程,
-
故障检测: 每5分钟发起一次故障检测,获取当前时刻整个集群的故障机器列表,推送到工作流子系统
-
安全策略: 遍历故障机器列表,依次执行安全策略,过滤不符合要求的机器,得到一个可安全执行重启、重装的机器列表
-
服务离线: 遍历可安全操作的机器列表,执行服务离线
-
故障维修: 服务离线后,发起重启、维修操作,轮询机器状态,直至重启成功或维修完成
-
环境初始化: 执行环境初始化,保证机器环境符合业务需求
-
服务上线: 恢复服务,检查服务达到可服务状态,流程结束
接下来将介绍工作流子系统,这是所有具体操作任务执行的基础;
再依次介绍上述流程中的关键环节: 服务上下线,故障检测,安全策略,维修工具及SLA;
然后通过一个线上例子,说明整体的工作流程;
最后分享系统上线后的运行数据。
2.1 工作流子系统
工作流最基本的功能,是驱动一系列预定义任务顺序执行,达到明确的结束状态;在机器故障自动处理这个问题域里,对工作流还有闭环、扩展性的要求(详见第一篇的分析).
经过分析统计机器相关的操作任务, 比如机器重启、重装、初始化环境、启动/停止服务、查看信息等,抽象出机器操作的任务模型,即”对一组机器执行相同的任务,且任务可以进一步拆分为一系列更小的原子操作组合”,如图所示,
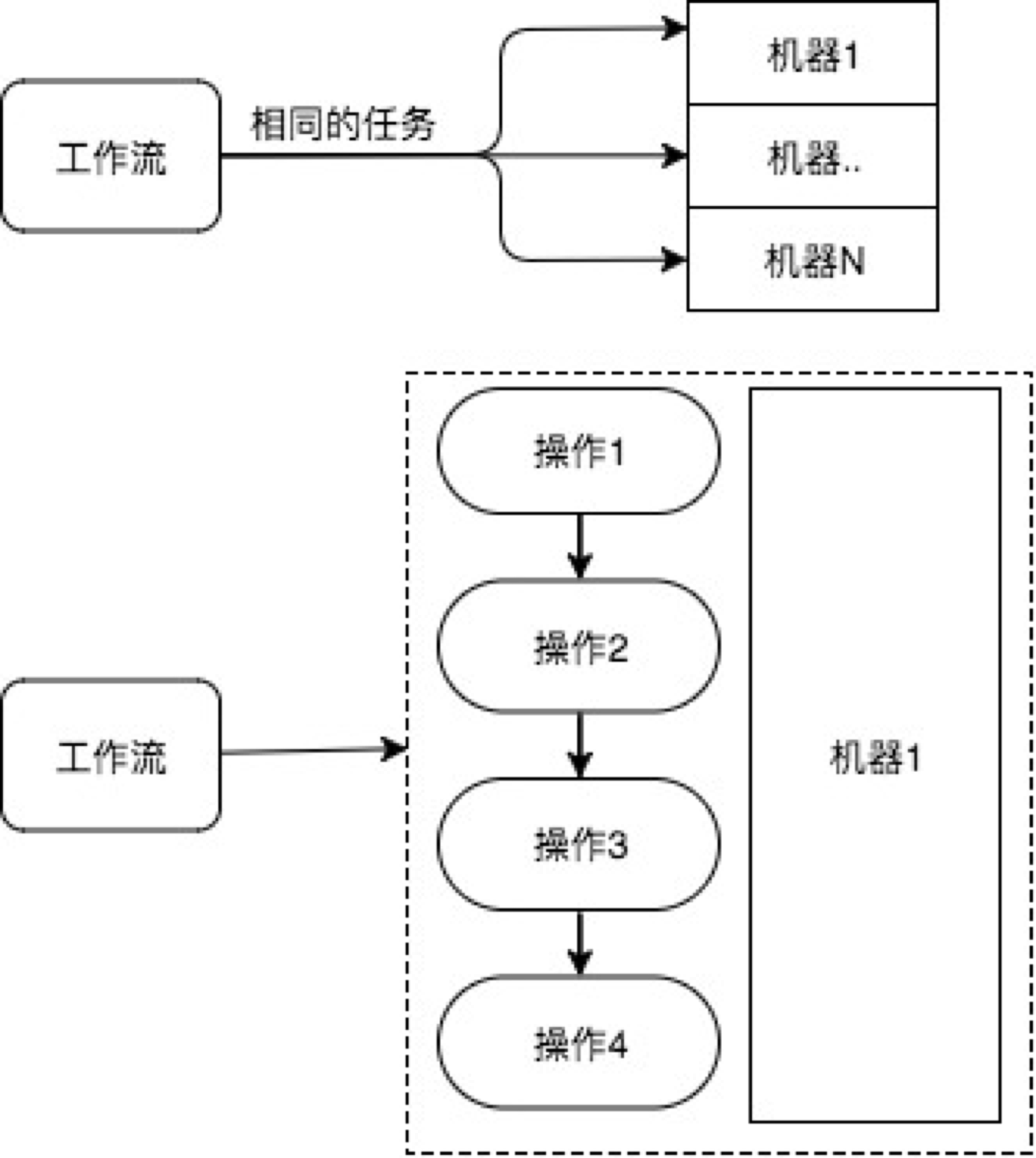

上图表示对一组机器执行相同的任务,下图表示,这个任务具体有4个原子操作。
由此,我们可以定义工作流的几个关键类,以及他们的关系,




注:为了简化表述,这里只列出和流程执行、任务分支、通用性相关的字段和逻辑,工作流子系统的完整信息,后续会另写文章介绍。
-
Job,定义了任务类型以及要操作的目标集合
-
Task,定义了一个具体的操作目标,以及action_tree的root节点
-
Action,定义了业务逻辑的内容和加载方式
-
Scheduler, 调度Job的运行
-
Monitor, 监控 Job、Task、Action 的状态
-
Executor, 控制Job下的task/action 的执行顺序、并发等
接下来重点看看工作流系统是如何达到前文提到的扩展性、闭环要求的。
第一点,扩展性。


扩展性需求,最初来自于不同服务上下线操作的差异,主要是有状态服务。
它们之间的差异,体现在操作步骤的数量和顺序不同。例如,
-
推荐模型服务,要求先寻找可用的机器资源,在新资源上部署相同版本的服务,启动服务加载数据,判断数据加载进度,直到达到某个阈值,才算是完成“迁移”,此时才达到可维修的状态
-
Docker服务,相对简单,只需向docker发起迁移命令,等待docker返回迁移进度,迁移完成后即可维修
-
Hadoop服务,主要痛点在磁盘故障上,要求维修过程中不能长时间停服,所以维修逻辑很复杂,要先停止本机服务,umount故障磁盘,启动服务,维修故障磁盘,修复之后再停服,起服,让Hadoop重新使用这块磁盘
-
其他无状态服务相对简单,通常直接维修即可
可见,不同服务的差异化是不可穷举的,如果ARS要介入具体的维修逻辑,无异于“揽屎上身”,最终陷入泥潭里无法自拔。
我们的思路是: 对外提供一套机制,能简易地将维修逻辑嵌入工作流子系统,实现步骤如下,
-
将复杂任务拆解成多个原子操作,每个原子操作实现为一个python方法,返回值格式固定
-
定义原子操作的执行顺序以及分支
只要满足上述条件,系统就能支持任意数量、任意顺序的原子操作集合。
原子操作的python实现如下图所示,

action1为原子操作名字,do_hard_work()方法由业务sre 完成,工作流子系统只负责调用, is_succ表明本次操作是否执行成功,result通常是操作结果信息。
只要按照这个约定编写的任务,都可注册到系统里被执行,哪怕提交人只是用python 包了一坨 shell 脚本,也是可嵌入系统的,虽然我们在review的时候会“建议”他重写。
有了原子操作的实现,就可以定义它们的执行顺序,我们使用了“树”的概念,如下图json配置示例所示,

可以看到,整棵树有多棵子树组成,每棵子树指向一个nodes list,每个node就是一个action, action的数量和顺序可以在nodes list里任意配置扩展。
在example_trees里, action1~action6就是原子操作,执行的顺序有两种可能分支,
action1-> action2 (true)--> action3->action4->结束;
action1-> action2 (false)--> action5->action6->结束;
假设现在业务有一个大的改动,需要在action2之前增加一个操作action7, 并在action6之后,增加一个分支action8, 这只需在配置上小改动即可实现,


example_trees 会被保存在Action类的action_definition字段里,这个配置记录了执行逻辑的python 文件,类和方法; 工作流在运行时,会动态加载相应的类,根据方法名调用方法,如下图所示,


凭借这些特性,业务sre可以灵活多变的定义自己的任务树,其中公共部分,由平台sre编写,与业务相关部分由业务sre编写。
第二点,闭环。
以无状态的 web机器的宕机自动处理流程为例,(这里为了方便表述,做了简化)
-
检测宕机的机器
-
重启机器
-
如果能起来,检查程序版本,启动web 服务,流程结束
-
如果不能起来,则报修硬件故障
-
如果能修复,回到第3步
-
如果不能修复,则检查是否过保,如果是,则下架机器,流程结束
其流程树的配置如下,



可以看到,reboot_host、check_host_alive、repair_host等action为原子操作;
这棵树有两个分支节点,
如果 reboot_host之后 check_host_alive为Ture, 则执行online_service 分支,流程结束;
如果为false, 则执行repair_host 分支,如果能修好,则回到 tree2 ,最后也达到 online_service的状态, 流程结束;(只要是没过保,都能修好)
如果修不好,那么则进入 off_rack 下架流程,流程结束。(通常是机器过保)
这里之所以反复强调任务分支,是因为有了任务分支,就可以在各个可能执行失败的环节,指定下一步的操作,最终将目标操作到一个可预期的状态(机器要么被修好重新投入使用,要么修不好被下架),形成闭环,不用人工介入,真正提高自动化程度。
同时,由于在一开始就设定了维修只有两种操作:重启,重装,这两种操作都由sys来保证交付时间,所以这棵树能保证流程是闭环的。
在ARS上线之前,早期的自动工具发起重启命令之后,机器起不来,通常是人工通知sys 报修,报修之后 sys 再根据机器是否过保来给sre 反馈维修状态,这个过程,如同黑洞,吞噬了rd-sre-sys-机房外包四方大量的沟通时间, 如图所示,


工作流子系统还涉及状态机、并发控制、重试、任务重入、超时、执行进度等,后续另写文章介绍。
在下一节里,将介绍故障检测、安全策略等内容。
2.2故障检测
故障检测的完整性、正确性是故障维修自动化的前提。
通过分析历史机器故障类型,可将故障分为5个层次,如下表,基本覆盖了sre日常处理的故障。
|
层次 |
异常类型 |
常见问题 |
检测方式 |
|
业务相关 |
执行异常 |
磁盘空间不足、部署时调用的control脚本返回值异常、目录权限 |
Falcon |
|
运维系统 |
平台自身异常 |
帐号异常、Executor执行任务异常、部署系统异常 |
Falcon+运维系统接口 |
|
基础环境 |
依赖异常 |
环境异常(依赖库/文件缺失)、版本不符(内核/python/perl)、limits.conf不符 |
Falcon+shell/python |
|
系统层 |
读写异常 |
文件系统错误(Input/Output Error)、文件系统挂载错误(read-only、home未挂载) |
Falcon+shell/python |
|
机器层 |
连接异常 |
硬盘故障, 宕机故障, 内存故障, 电源故障, 风扇故障, CPU/GPU故障 |
ping/ssh/Falcon+ipmi |
ARS主要覆盖了机器层、系统层,下面分别做说明。
磁盘故障
磁盘故障率高的业务类型很多, 如hadoop、索引服务、分布式文件系统服务、机器学习模型训练服务等,这些服务的机器,磁盘块数最高多达36块,大量读写磁盘,造成磁盘故障率很高。
常见的磁盘故障类型有掉盘、读写错误(Input/Output Error)、漂盘、挂载错误、 read-only错误、性能剧降(ls https://img.qb5200.com/download-x/disk/ 超过10分钟无反应);
磁盘故障的积累,有可能会导致数据丢失,以及拖慢整个系统的性能,所以要尽早检测到尽早处理。
宕机故障
宕机故障分为完全死机,假死。
完全死机(指连续3个小时失去心跳,并且主动ssh 探测失败的机器),这种情况容易处理,直接进入自动重启流程;
假死,有如下类型,
l Connection timed out
l Connection closed by remotehost
l Connection reset by peer
l Connection refused
l Connection closed by
这些假死状态,可能会造成业务受损。
比如机器假死,服务端口还能连接,但实际业务进程内部无法正常工作,如果是前端web机器出现这种情况,会导致业务5xx监控飙升;此时,想手动重启,ssh已经无法连接,只能通过ilo重启,或者紧急联系机房,处理耗时往往超过半小时。
内存故障
内存故障时,通常机器还没有死机,(在/var/log/message 里显示CE error on CPU#1Channel#2_DIMM#1)
rd认为机器还能跑,不愿意停服务;
如果积攒到多台机器出现类似错误,极有可能在短时间内出现连续死机,导致服务容量突然减少,服务性能大幅下降的业务故障,所以对于一些敏感服务,出现这种故障,还是要当作死机来处理。
电源故障
双电源是突然断电、市政施工的保障,如果电源坏了不修,在这种情况下,机器会断电关机,如果积攒多了,服务容量会突减,影响业务。
风扇故障
不会马上造成死机,但是会产生连锁反应。风扇故障会导致cpu温度升高,引发死机。
上述故障检测的实现,主要是通过 Falcon监控系统 + scripts 实现,涉及了 ping/ssh/ipmihttps://img.qb5200.com/download-x/dmesg/proc/sar…等大量系统命令和系统信息。
Falcon 运行这些scripts,检测故障,外部应用就可以从接口里查询故障列表信息,如下,


ARS从Falcon拉取当前时刻集群内所有故障机器的列表,附带了相应的故障信息,推送到工作流里,进行维修。
2.3 安全策略
对机器的操作,通常是重装、重启、root环境修改、部署基础agent等;此类操作往往不可逆且无法暂停,所以需要严格的安全策略保证机器操作不影响线上服务或影响最小。
经过“故障检测”这个环节后,得到一个当前时刻所有故障机器列表,安全策略会对这个列表进行分析过滤,下表是我们使用的安全策略列表,
|
策略 |
作用&应用场景 |
实现 |
|
filter_bw _lists |
黑白名单; 通常用于敏感服务,如支付、隔离环境服务 |
只处理白名单内的机器 跳过黑名单内的机器 |
|
filter_alive_hosts |
过滤掉处于非死机的机器; 防止误判,重启了非死机的机器 |
1、3分钟内连续ping机器,如果有响应,则过滤机器 2、过滤可以响应 ssh 请求的机器 3、防止网络抖动误判,在多个机房 ping,交叉验证 |
|
filter_switch_fail |
防止交换机故障引起误判,比如批量机器无法联通 |
按分钟统计机器的故障时间,如是同一分钟内报上来的(falcon采集周期是1分钟),本次就不会向后端推送任何机 |
|
filter_base_agent |
过滤掉基础agent端口存活的机器; 某些特殊服务会禁止ping/ssh命令,所以通过基础agent端口来判断存活 |
通过 telnet/curl ip:port 判断基础agent是否存活,基础agent存活代表机器存活,过滤机器 |
|
filter_running_service_hosts |
过滤掉有服务处于running状态的机器; 防止误判,操作了服务还在运行的机器 |
检查机器网卡流量、磁盘io等指标,超过阈值则认为存在服务,过滤机器 |
|
filter_capacities |
根据服务容量过滤; 防止因操作了机器,导致服务容量不足 |
计算服务容量, 当前running实例数/总实例数 < 阈值(90%),过滤机器 |
|
filter_duplicate |
去重,保证同一时刻同一台机器只有一个操作任务在执行; 防止多个任务叠加到同一台机器,出现未预期结果 |
遍历系统所有任务,如果此机器有处于running的任务,跳过此机器 |
|
filter_pattern |
过滤指定patterns的机器; 这是最严格的过滤器,通常是单点服务使用此策略 |
对机器的机器名、节点名、运行服务名、在各类配置中心注册名进行正则匹配,如果匹配,则过滤机器 |
|
filter_threshold |
阈值保护,保证同时进行的机器操作任务数低于允许维修的数量 |
1、按机房粒度,对于不同的任务类型,如果当前此机房的机器操作任务数大于阈值,跳过此机器 2、按服务(app)粒度,如果当前此服务(app)的机器操作任务数大于阈值,跳过此机器 例如这个例子,当前app1任务数是3,而允许维修的阈值是5,所以只能再发起2台机器的维修 current_repairing/beijing/app1: 3 threshold /beijing/app1: 5 |
|
filter_by_date |
遵循分级发布原则,在一个星期内的某一天,只能维修对应机房的机器 |
1、指定每天允许维修的机房 2、遍历所有机器,如果一台机器所属的机房不是当天允许维修的,跳过此机器 |
这个安全策略表,是总结分析多个业务线的历史case study得出来的, 在线上运行以来,未出现过误判,保证了自动任务的安全性。
每一个安全策略,实现为工作流里的一个原子操作,即action,结合上述重启的例子,json配置如下,(维修的流程也可以使用这些安全策略,这里不再单独列出)

这些策略,可复用也可自由组合、调整顺序,这对于接入不同业务的机器进行自动维修,有很大的便利性和灵活性,同时降低了接入成本。
如果业务有自己的安全策略需求,只需按照上述的action 方法规范,自己写一个安全策略方法,在配置里指定即可使用。
2.4 维修工具及SLA
机器硬件故障维修,是真实世界中的事件,这个过程需要人去到机房现场,从仓库拿出配件,走到机架旁边,拆卸机器,装配硬件。
所以这个环节是“不可抗力”产生的地方,比如配件备货不足;节假日厂商人员放假,无法赶赴机房;赶上两会,机房封禁,不让进入等各种问题。
1 交付时间
为了达到流程闭环,我们(甲方)和机器厂商(乙方)约定机器维修交付时间, 通常是36小时交付(不同公司、厂商可能不一样),至于怎么解决上述“不可抗力”,由乙方负责。
2 远程管理工具可用率
远程管理工具是机器操作自动化的必备工具,reboot_host/repair_host底层调用的就是ipmi;
为了尽可能地减少机房现场人员操作,我们要求sys保证远程管理工具可用率达到 99.9%,比如,ilo,ipmi
有了这两个SLA,我们可以认为 reboot_host、repair_host 这两个原子操作的最长耗时为36小时,所以维修流程是一定可以闭环的,避免了因任务中断导致的人工介入。
当然,有了这些,也只是修复了硬件,还有系统参数设置、环境初始化、基础agent的问题,这个内容比较多,在下一篇讲。
将上述提及的技术细节汇总,得到ARS的完整视图,

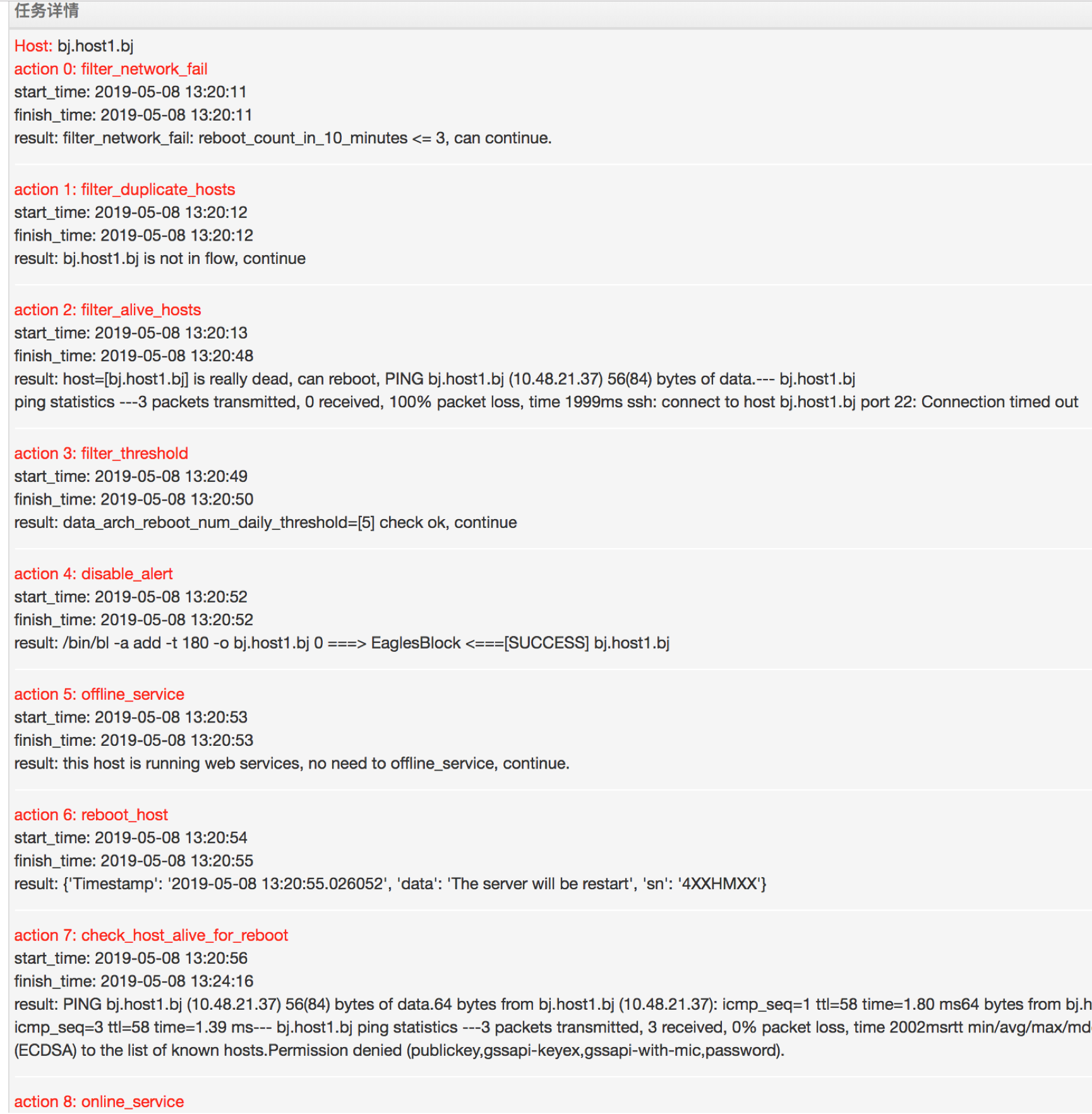
最后,看一个自动重启的例子,

可以看到任务树定义的actions 是怎么执行的,先是执行一系列的 filter_*安全策略,然后屏蔽报警,执行服务离线,发起重启,然后轮询机器状态,直到任务结束。
2.5 系统运行数据
ARS上线后,覆盖数万台机器的故障自动处理,死机数量保持在10台左右,所有硬件故障总数量保持在100台以下,这对于一个数万台机器的集群来说,是非常理想的状态了。
人力方面,对于20人的sre 团队,机器故障只需要 0.5人力维护系统正常运转,例如新服务的接入、业务要求紧急修复之类的情况;当机器规模增长时,人力并不需要相应的增加。
2.6 总结
最后,总结一下几个关键点,
-
标准,定义了有哪些类型的故障,什么故障执行什么样的修复,修复的标准流程
-
闭环,对于机器的操作,用任务分支覆盖操作成功或失败的情况,用SLA约束厂商在约定时间内交付机器,保证流程可达到明确的结束状态,避免人工介入
-
安全,10个安全策略组成的过滤链,并支持低成本的增加新策略,保证自动化任务是安全的
在本文中,有一个重要的事项没有提到,就是环境初始化,这个再下一篇文章讲述。
排列文字,重组感受。
我是曲行人,日常写码,闲时写点儿文字,
如果你觉得有点意思,或者有点用,可以关注我,
我将在大脑里的思维原子做布朗运动时,输出文字。
公众号: qxren7
二维码:

加载全部内容