理解MySQL变量和条件
pursuer.chen 人气:0一、概述
变量在存储过程中会经常被使用,变量的使用方法是一个重要的知识点,特别是在定义条件这块比较重要。
mysql版本:5.6
二、变量定义和赋值
#创建数据库 DROP DATABASE IF EXISTS Dpro; CREATE DATABASE Dpro CHARACTER SET utf8 ; USE Dpro; #创建部门表 DROP TABLE IF EXISTS Employee; CREATE TABLE Employee (id INT NOT NULL PRIMARY KEY COMMENT '主键', name VARCHAR(20) NOT NULL COMMENT '人名', depid INT NOT NULL COMMENT '部门id' ); INSERT INTO Employee(id,name,depid) VALUES(1,'陈',100),(2,'王',101),(3,'张',101),(4,'李',102),(5,'郭',103);
declare定义变量
在存储过程和函数中通过declare定义变量在BEGIN...END中,且在语句之前。并且可以通过重复定义多个变量
注意:declare定义的变量名不能带‘@'符号,mysql在这点做的确实不够直观,往往变量名会被错成参数或者字段名。
DECLARE var_name[,...] type [DEFAULT value]
例如:
DROP PROCEDURE IF EXISTS Pro_Employee; DELIMITER $$ CREATE PROCEDURE Pro_Employee(IN pdepid VARCHAR(20),OUT pcount INT ) READS SQL DATA SQL SECURITY INVOKER BEGIN DECLARE pname VARCHAR(20) DEFAULT '陈'; SELECT COUNT(id) INTO pcount FROM Employee WHERE depid=pdepid; END$$ DELIMITER ;
SET变量赋值
SET除了可以给已经定义好的变量赋值外,还可以指定赋值并定义新变量,且SET定义的变量名可以带‘@'符号,SET语句的位置也是在BEGIN ....END之间的语句之前。
1.变量赋值
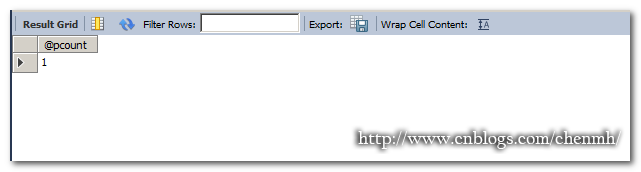
SET var_name = expr [, var_name = expr] ... DROP PROCEDURE IF EXISTS Pro_Employee; DELIMITER $$ CREATE PROCEDURE Pro_Employee(IN pdepid VARCHAR(20),OUT pcount INT ) READS SQL DATA SQL SECURITY INVOKER BEGIN DECLARE pname VARCHAR(20) DEFAULT '陈'; SET pname='王'; SELECT COUNT(id) INTO pcount FROM Employee WHERE depid=pdepid AND name=pname; END$$ DELIMITER ; CALL Pro_Employee(101,@pcount); SELECT @pcount;
2.通过赋值定义变量
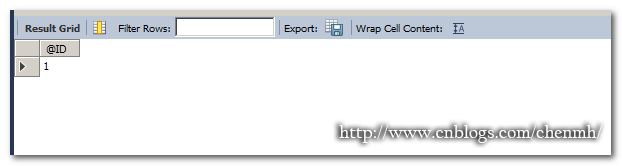
DROP PROCEDURE IF EXISTS Pro_Employee; DELIMITER $$ CREATE PROCEDURE Pro_Employee(IN pdepid VARCHAR(20),OUT pcount INT ) READS SQL DATA SQL SECURITY INVOKER BEGIN DECLARE pname VARCHAR(20) DEFAULT '陈'; SET pname='王'; SET @ID=1; SELECT COUNT(id) INTO pcount FROM Employee WHERE depid=pdepid AND name=pname; SELECT @ID; END$$ DELIMITER ; CALL Pro_Employee(101,@pcount);
SELECT ... INTO语句赋值
通过select into语句可以将值赋予变量,也可以之间将该值赋值存储过程的out参数,上面的存储过程select into就是之间将值赋予out参数。
DROP PROCEDURE IF EXISTS Pro_Employee; DELIMITER $$ CREATE PROCEDURE Pro_Employee(IN pdepid VARCHAR(20),OUT pcount INT ) READS SQL DATA SQL SECURITY INVOKER BEGIN DECLARE pname VARCHAR(20) DEFAULT '陈'; DECLARE Pid INT; SELECT COUNT(id) INTO Pid FROM Employee WHERE depid=pdepid AND name=pname; SELECT Pid; END$$ DELIMITER ; CALL Pro_Employee(101,@pcount);
这个存储过程就是select into将值赋予变量;
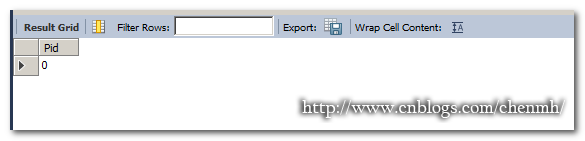
表中并没有depid=101 and name='陈'的记录。
三、条件
条件的作用一般用在对指定条件的处理,比如我们遇到主键重复报错后该怎样处理。
定义条件
定义条件就是事先定义某种错误状态或者sql状态的名称,然后就可以引用该条件名称开做条件处理,定义条件一般用的比较少,一般会直接放在条件处理里面。
DECLARE condition_name CONDITION FOR condition_value condition_value: SQLSTATE [VALUE] sqlstate_value | mysql_error_code
1.没有定义条件:
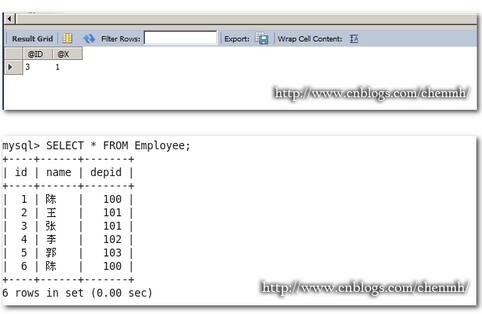
DROP PROCEDURE IF EXISTS Pro_Employee_insert; DELIMITER $$ CREATE PROCEDURE Pro_Employee_insert() MODIFIES SQL DATA SQL SECURITY INVOKER BEGIN SET @ID=1; INSERT INTO Employee(id,name,depid) VALUES(1,'陈',100); SET @ID=2; INSERT INTO Employee(id,name,depid) VALUES(6,'陈',100); SET @ID=3; END$$ DELIMITER ; #执行存储过程 CALL Pro_Employee_insert(); #查询变量值 SELECT @ID,@X;

报主键重复的错误,其中1062是主键重复的错误代码,23000是sql错误状态

2.定义处理条件
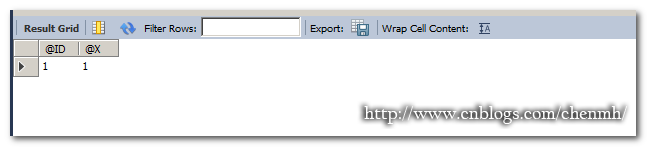
DROP PROCEDURE IF EXISTS Pro_Employee_insert; DELIMITER $$ CREATE PROCEDURE Pro_Employee_insert() MODIFIES SQL DATA SQL SECURITY INVOKER BEGIN #定义条件名称, DECLARE reprimary CONDITION FOR 1062; #引用前面定义的条件名称并做赋值处理 DECLARE EXIT HANDLER FOR reprimary SET @x=1; SET @ID=1; INSERT INTO Employee(id,name,depid) VALUES(1,'陈',100); SET @ID=2; INSERT INTO Employee(id,name,depid) VALUES(6,'陈',100); SET @ID=3; END$$ DELIMITER ; CALL Pro_Employee_insert(); SELECT @ID,@X;
在执行存储过程的步骤中并没有报错,但是由于我定义的是exit,所以在遇到报错sql就终止往下执行了。
接下来看看continue的不同
DROP PROCEDURE IF EXISTS Pro_Employee_insert; DELIMITER $$ CREATE PROCEDURE Pro_Employee_insert() MODIFIES SQL DATA SQL SECURITY INVOKER BEGIN #定义条件名称, DECLARE reprimary CONDITION FOR SQLSTATE '23000'; #引用前面定义的条件名称并做赋值处理 DECLARE CONTINUE HANDLER FOR reprimary SET @x=1; SET @ID=1; INSERT INTO Employee(id,name,depid) VALUES(1,'陈',100); SET @ID=2; INSERT INTO Employee(id,name,depid) VALUES(6,'陈',100); SET @ID=3; END$$ DELIMITER ; CALL Pro_Employee_insert(); SELECT @ID,@X;
其中红色标示的是和上面不同的地方,这里定义条件使用的是SQL状态,也是主键重复的状态;并且这里使用的是CONTINUE就是遇到错误继续往下执行。
条件处理
条件处理就是之间定义语句的错误的处理,省去了前面定义条件名称的步骤。
DECLARE handler_type HANDLER FOR condition_value[,...] sp_statement handler_type: CONTINUE| EXIT| UNDO condition_value: SQLSTATE [VALUE] sqlstate_value | condition_name | SQLWARNING | NOT FOUND | SQLEXCEPTION | mysql_error_code
handler_type:遇到错误是继续往下执行还是终止,目前UNDO还没用到。
CONTINUE:继续往下执行
EXIT:终止执行
condition_values:错误状态
SQLSTATE [VALUE] sqlstate_value:就是前面讲到的SQL错误状态,例如主键重复状态SQLSTATE '23000'
condition_name:上面讲到的定义条件名称;
SQLWARNING:是对所有以01开头的SQLSTATE代码的速记,例如:DECLARE CONTINUE HANDLER FOR SQLWARNING。
NOT FOUND:是对所有以02开头的SQLSTATE代码的速记。
SQLEXCEPTION:是对所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE代码的速记。
mysql_error_code:是错误代码,例如主键重复的错误代码是1062,DECLARE CONTINUE HANDLER FOR 1062
语句:
DROP PROCEDURE IF EXISTS Pro_Employee_insert; DELIMITER $$ CREATE PROCEDURE Pro_Employee_insert() MODIFIES SQL DATA SQL SECURITY INVOKER BEGIN #引用前面定义的条件名称并做赋值处理 DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET @x=2; #开始事务必须在DECLARE之后 START TRANSACTION ; SET @ID=1; INSERT INTO Employee(id,name,depid) VALUES(7,'陈',100); SET @ID=2; INSERT INTO Employee(id,name,depid) VALUES(6,'陈',100); SET @ID=3; IF @x=2 THEN ROLLBACK; ELSE COMMIT; END IF; END$$ DELIMITER ; #执行存储过程 CALL Pro_Employee_insert(); #查询 SELECT @ID,@X;
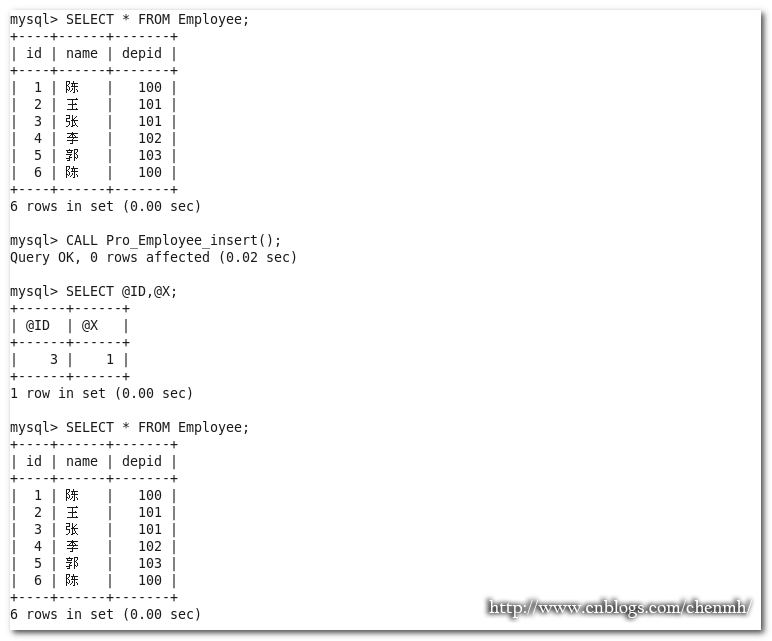
通过SELECT @ID,@X可以知道存储过程已经执行到了最后,但是因为存储过程后面有做回滚操作整个语句进行了回滚,所以ID=7的符合条件的记录也被回滚了。
总结
变量的使用不仅仅只有这些,在光标中条件也是一个很好的功能,刚才测试的是continue如果使用EXIT的话语句执行完“SET @ID=2;”就不往下执行了,后面的IF也不被执行整个语句不会被回滚,但是使用CONTINE当出现错误后还是会往下执行如果后面的语句还有很多的话整个回滚的过程将会很长,在这里可以利用循环,当出现错误立刻退出循环执行后面的if回滚操作,在下一篇讲循环语句会写到,欢迎关注。
加载全部内容