MySQL中join语句的基本使用教程及其字段对性能的影响
fengyqf 人气:0join语句的基本使用
SQL(MySQL) JOIN 用于根据两个或多个表中的字段之间的关系,从这些表中得到数据。
JOIN 通常与 ON 关键字搭配使用,基本语法如下:
... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON conditiona
table1 通常称为左表,table2 称为右表。ON 关键字用于设定匹配条件,用于限定在结果集合中想要哪些行。如果需要指定其他条件,后面可以加上 WHERE 条件 或者 LIMIT 以限制记录返回数目等。
下面以最常见的两表连接来说明 MySQL JOIN 的用法,关于多表 JOIN 请参见《MySQL JOIN 多表》。
MySQL JOIN 分类
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接):取得两个表中存在连接匹配关系的记录。
- LEFT JOIN(左连接):取得左表(table1)完全记录,即是右表(table2)并无对应匹配记录。
- RIGHT JOIN(右连接):与 LEFT JOIN 相反,取得右表(table2)完全记录,即是左表(table1)并无匹配对应记录。
关于 MySQL FULL JOIN 全连接
MySQL 没有提供 SQL 标准中的 FULL JOIN(全连接):两个表记录都取出,而不管彼此是否有对应记录。要解决此问题,可以使用 UNION 关键字来合并 LEFT JOIN 与 RIGHT JOIN,达到模拟 FULL JOIN 的目的。
MySQL INNER JOIN
INNER JOIN 用于取得两个表中存在连接匹配关系的记录。下面是两个原始数据表:

article 表中文章的所属用户是通过 uid 这个字段与 user 表关联起来的。通过观察数据不难发现,对于 uid=3 的用户,并没有发表任何文章;而文章中 aid=4 却无法在 uid 表中找到对应记录(可能是该用户被删除而其所属的文章却被保留了下来)。
我们列出所用文章与用户一一对应的数据。
SELECT … INNER JOIN … ON 语句如下:
SELECT article.aid,article.title,user.username FROM article INNER JOIN user ON article.uid = user.uid
返回查询结果如下:

对于 INNER JOIN,等同与下面的 SQL 语句:
SELECT article.aid,article.title,user.username FROM article,user WHERE article.uid = user.uid
CROSS JOIN
CROSS JOIN 即交叉连接,在不指定 ON 条件下:
SELECT article.aid,article.title,user.username FROM article CROSS JOIN user
得到的结果是被连接的两个数据表的乘积,即笛卡尔积。
实际上,在 MySQL 中(仅限于 MySQL) CROSS JOIN 与 INNER JOIN 的表现是一样的,在不指定 ON 条件得到的结果都是笛卡尔积,反之取得两个表完全匹配的结果。
INNER JOIN 与 CROSS JOIN 可以省略 INNER 或 CROSS 关键字,因此下面的 SQL 效果是一样的:
平板视图打印?
... FROM table1 INNER JOIN table2 ... FROM table1 CROSS JOIN table2 ... FROM table1 JOIN table2
join的字段字符集编码对性能的影响
先来看一下示例代码:
建utf-8编码的表 t1:
CREATE TABLE IF NOT EXISTS `t1` ( `name` varchar(50) NOT NULL DEFAULT '', KEY `name` (`name`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
随便插入些数据,数量大一点,后面实验结果更清晰,偷个懒,构造随机字符串插入语句
insert into t1(name) select concat( char(round((rand())*25)+97), char(round((rand())*25)+65), char(round((rand())*25)+65), char(round((rand())*25)+97), char(round((rand())*25)+65), char(round((rand())*25)+65), char(round((rand())*25)+97), char(round((rand())*25)+65) )
每次执行插入一条记录,用你熟悉的脚本(python,php,shell等都行)写个循环,执行一万次以上。
将该表复制成一个新表t2,删除一部分数据,1000条左右即可。(推荐使用phpMyAdmin)
再将t2复制为t3,并将字段改为gb2312编码。
使用一个left join语句,写一个语句,查出t2/t3比t1少了哪些记录。
语句很简单,如下:
SELECT SQL_NO_CACHE t1.name, t2.name FROM t1 LEFT JOIN t2 ON t1.name = t2.name WHERE t2.name IS NULL LIMIT 0 , 30
注意加入 SQL_NO_CACHE ,禁用mysql缓存。
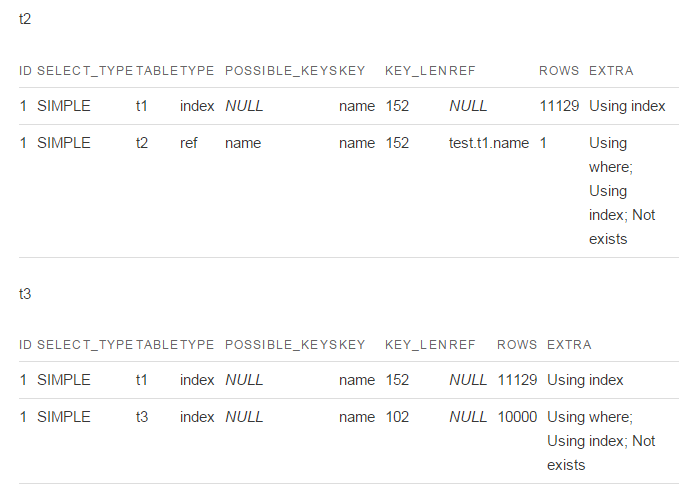
先看编码一致的t2表,phpMyAdmin里执行结果:
显示行 0 - 29 ( 1,129 总计, 查询花费 0.0010 秒)
平均耗时大概为0.0010秒
SELECT SQL_NO_CACHE t1.name, t3.name FROM t1 LEFT JOIN t3 ON t1.name = t3.name WHERE t2.name IS NULL LIMIT 0 , 30
phpMyAdmin执行结果:
显示行 0 - 29 ( 30 总计, 查询花费 0.1871 秒)
差两个数量级!
查询语句解释:
加载全部内容