MySQL结合使用数据库分析工具SchemaSpy的方法
人气:0近来,我和一帮老客户一起工作,他们让花时间给他们说一下在他们新环境中使用的新工具。其中,我发现的一个非常有用的工具是SchemaSpy。
SchemaSpy是Java开发的的工具(要求java 5或更高版本的支持),主要用来分析数据库中数据模型的元数据,并且能生成基于浏览器可视化的显示。通过点击就可了解数据表的层次结构,父子表关系等,主要通过HTML 链接或者实体关系图来表达。它也被设计成用来帮助解决由于约束而导致的数据库关联失败的迟钝错误。
我所喜欢ERD工具所能做的一件事是能快速的生成一个图形表达,来展现数据库那个表被引用最多,那些表已经被代替了是可以删除的(为什么要保存你不需要的的数据呢?)。通过了解数据库表关系而不是仅仅看查询语句,这可以加快的开始步伐,并且还促进开发的过程使其更有效。SchemaSpy的另一个优点是,他是一个命令行工具,在每次执行后才生成html页面,所以特别适合用于crontab中,使得模型改变后能自动调整页面。很不错,是吧?
这个工具使用起来简单明了,可以帮你做很多的事。主要是,如果你的数据库有一个外键,你就偷着乐吧,如果没有,也不要太绝境,你还有更多的工作等着你。绝大多数情况下,SchemSpy可以出色的完成任务,但是有时候你需要以元数据文件的形式给它一点点的信息。
安装SchemaSpy及其相关
下载 SchemaSpy最新版的jar文件(书写本文时的版本是5.0.0)
确认你有一个能运行于你的操作平台的Java JRE
你需要一个你所用数据库的Java驱动——我在使用 MySQL Connector/J
安装graphiz 包
创建 mysql.properties文件
当需求尚不明确时,我喜欢这样建立一下,以便让命令行能又短又整洁。这是我为我的Percona Server 5.6.10沙箱所使用的属性文件:
driver=com.mysql.jdbc.Driver
connectionSpec=jdbc:mysql://127.0.0.1:5610/schemaspy
driverPath=/usr/share/java/mysql-connector-java.jar
Schema的例子:
CREATE TABLE `parent` ( `parent_id` int(10) unsigned NOT NULL AUTO_INCREMENT, PRIMARY KEY (`parent_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 CREATE TABLE `child_A` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `parent_id` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 CREATE TABLE `child_B` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `parent_id` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`id`), KEY `parent_id` (`parent_id`), CONSTRAINT `child_B_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`parent_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
请注意,在表child_A里有一个隐含的通过parent_id作为外键关联到parent的关系,但在表child_B中建立了一个显式的外键parent_id。这会影响SchemaSpy如何辨别关系,以及你是否需要提供一个提示。
运行SchemaSpy(有外键)
如果没有元数据文件,你运行SchemaSpy,你将能看到parent 表和child_B表的关系如下图所示:
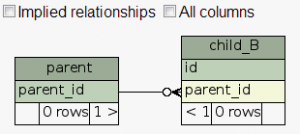
表child_A也能被加进来显示,如果你的标签指出了他们关系框,但是这个通常只能在你的子表和父表使用完全一样的名字(本例中parent_id)时候才能起作用。你的环境看起里就像是许多商店,在父表中名字是id,在他其的子表他们代表为parent_id——这情景对开发者可能比较熟悉,但是对SchemaSpy根本没有任何的帮助。那就是需要元数据文件来大显身手的时候。
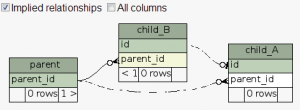
配置元数据文件
元数据文件是一个XML格式的。下面的配置实例是用来把child_A表链接到parent表。
<?xml version="1.0" encoding="UTF-8"?> <schemaMeta xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schemaspy.sourceforge.net/xmlschema/2011/02/05/schemaspy.meta.xsd"> <comments> Main Production Database. Percona, Michael Coburn </comments> <tables> <table name="parent" comments="Parent table"> <column name="parent_id" primaryKey="true"> </column> </table> <table name="child_A" comments="Non-FK relationship, implicit relationship to parent"> <column name="id" primaryKey="true"> </column> <column name="parent_id"> <foreignKey table="parent" column="parent_id"/> </column> </table> </tables> </schemaMeta>
更多的复杂配置例子的可以 访问。
运行SchemaSpy
下面的语法是连接MySQL数据库,SchemaSy同时对其他大多数流行的关系数据有很好支持。
java -jar schemaSpy_5.0.0.jar -t mysql -u msandbox_ro -p msandbox -meta schemaspy.meta.xml -o /var/www/schemaspy/
-o选项,标识SchemaSpy的输出文件目录,要确定这个目录可以被web服务器所操作。需要提及的是,我通过在jar包所在目录建立一个mysql.properties文件,这样我可以不用输入任何的服务器:端口以及数据库名称的信息。
浏览SchemaSpy输出
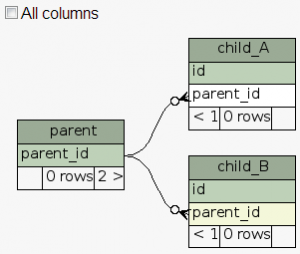
三个表的完整的关系视图如下图所示:
收尾感想
尽管我提及到了关系栏,SchemaSpy最有用的功能。为了避免SchemaSpy只有这个功能这样的假象,我要提及一下更多的功能栏:
- 表——名称,子表数量,父表,列计数,行计数,还有注解--大量用于高层次预览表大小以及一种快捷的方法是,用浏览的搜索属性定位到特定的表。
- 限制——列出数据库中明确的外键限制(这不包括通过元数据文件配置的限制!)。
- 异常——基于名字指出可能的字段/表的关系,没有索引的表,标识为可空的字段和唯一字段(吐了!),单列表,子增长字段的名称;空字符而不是实际sqlnull值的表;在发生重大错误时候,这可以作为一个大体的数据库检查项,或者细节需求的浏览。
- 字段——库总所有字段的列表,很方便通过名称筛选来查看是否有忽略的明确限制,然后把它们写到你的元数据文件中。
- 贡献——这是一个自由软件,John Currier请求得到你的捐献,一般它能有更多的理由来花费更多的精力和时间来维护这个软件,而不仅仅是他老婆的抱怨。
最后,你不要忘了,把配置好的SchemaSpy写到crontab来实现自动化。
如果正在使用其他的ERD工具,和SchemaSpy相比较怎么样?请通过评论畅所欲言。谢谢你有耐心读完本文。
加载全部内容