简单讲解MySQL中的多源复制
人气:0近日ORACLE发布几个新的功能在最新的Mysql5.7.2的版本上,由此有了此篇文章。大多数的改善是在数据库性能和复制相关的功能上,这个新版本会带给我们不可思议的效果。
在这篇文章里,我将要用一些简单的步奏来尝试了解这新的多源复制工作原理以及我们怎样进行自己的测试。需要说明的是,这还是一个开发版本,不是给生产环境准备的。因此这篇文章是打算给那些想了解此新功能的人,看看它是如何在应用中工作的,都是在临时环境中进行相关操作。
什么是多源复制?
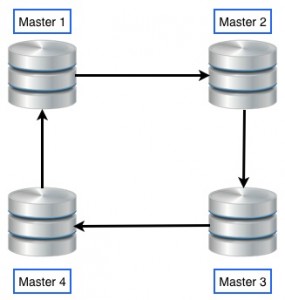
首先,我们需要清楚 multi-master 与multi-source 复制不是一样的. Multi-Master 复制通常是环形复制,你可以在任意主机上将数据复制给其他主机。
Multi-source 是不同的. MySQL在这个新版本中修复了一个复制限制 , 这限制是一个从站只能有一个主站. 这是一个在我们设计复制环境中的限制因素,也有一些极客使它正常工作了。但是现在有一个官方的解决办法了。所以。简单的说, Multi-Source 意味着一个从站能有一个以上主站. 现在, 像下图一样的复制环境是可能的:
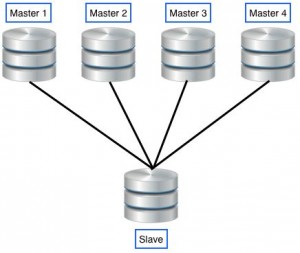
这将帮助我们创建一些复制的层次结构,这在过去是不可能的。 举个例子,你可以 将一个从站放在你的办公室里。在办公室里从所有主站中复制数据传播到世界各地。
它是怎么工作的呢?
现在我们有了通信渠道的概念,每一个通信渠道都是一个从服务器从主服务器获得2进制日志的链接。这意味着每个通信渠道都得有一个IO_THREAD .我们需要运行不同的 “CHANGE MASTER” 命令, 对于每一个主服务器。我们需要用到 “FOR CHANNEL”这个参数来提供通信链接的名字。
CHANGE MASTER MASTER_HOST='something', MASTER_USER=... FOR CHANNEL="name_of_channel";
很容易. 有一个单一的先决条件。从服务器需要在mysql5.6上配置安全功能,这意味着信息通常包含在主服务器上。信息或日志应该在一个表中,让我们开始配置吧
来个例子!
首先你需要下载测试版的mysql。点这个链接:下载.
我们需要有一个从服务器和两个主服务器的沙箱环境. 我不会细节的说明怎样配置server_id, binary logs 和 replication users.我假设已经配置好了。 如果你不知道怎么做。你可以看这个链接
首先,我们在从服务器上实现事故安全功能。
master_info_repository=TABLE; relay_log_info_repository=TABLE;
让后重启从服务器。我们可以开始创建通信渠道,用 “master1″ 和 “master2″这两个名字:
slave > change master to master_host="127.0.0.1", master_port=12047, master_user="msandbox",master_password="msandbox" for channel="master1"; slave > change master to master_host="127.0.0.1", master_port=12048, master_user="msandbox",master_password="msandbox" for channel="master2";
按照所设定的通信名字启动从服务器。
slave > start slave for channel="master1"; slave > start slave for channel="master2";
现在我们检查一下从服务器状态:
slave > show slave status\G Empty set (0.00 sec)
啊。是空的。我们需要写上通信名字。重新检查下从服务器状态:
slave > SHOW SLAVE STATUS FOR CHANNEL="master1"\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: msandbox
Master_Port: 12047
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 232
Relay_Log_File: squeeze-relay-bin-master1.000003
Relay_Log_Pos: 395
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[...]
我们也可以检查正在运行的 IO_THREAD 和 SQL_THREADS :
slave > SHOW PROCESSLIST; +----+-------------+-----------------------------------------------------------------------------+ | Id | User | State | +----+-------------+-----------------------------------------------------------------------------+ | 2 | system user | Waiting for master to send event | | 3 | system user | Slave has read all relay log; waiting for the slave I/O thread to update it | | 4 | system user | Waiting for master to send event | | 5 | system user | Slave has read all relay log; waiting for the slave I/O thread to update it | +----+-------------+-----------------------------------------------------------------------------+
测试看一下:
master1 > create database master1; master2 > create database master2; slave > show databases like 'master%'; +--------------------+ | Database (master%) | +--------------------+ | master1 | | master2 | +--------------------+
正常工作了。看起来很简单!
结论
这个新的multi-source功能使在过去需要一些复杂操作创建的复制环境变得简单了。当然,你应用程序可以考虑这个新的特性设计和开发,使用 multi-master, multi-source都需要特别注意,不要把你的数据都弄乱了。
在每一个新的版本中,mysql的复制功能给我们更多的配置,性能和设计的可能性。所有这些新功能都可以结合起来。在你新(老)的功能中增加复制功能,你的复制环境会更加出色。举个例子:你可以配置 GTID 可以用 multi-threaded slave per schema或intra-database.
加载全部内容