【一起学源码-微服务】Nexflix Eureka 源码八:EurekaClient注册表抓取 精妙设计分析!
一枝花算不算浪漫 人气:1前言
前情回顾
上一讲 我们通过单元测试 来梳理了EurekaClient是如何注册到server端,以及server端接收到请求是如何处理的,这里最重要的关注点是注册表的一个数据结构:ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>()
本讲目录
回头看了下之前的博客,没有一个总目录说明,每篇都是直接源码分析了。从此篇文章开始都会加上目录,以及文章最后会加上总结及读此篇源码的感受。希望这个博客系列的文章会越来越好。
目录如下:
- client端第一次注册全量抓取注册表的逻辑
- server端返回注册表信息集合的多级缓存机制
- server端注册表多级缓存过期机制:主动+定时+被动
- client端增量抓取注册表逻辑
技术亮点:
- 注册表抓取的多级缓存机制
- 增量抓取返回的全量数据hashCode,和本地数据hashCode对比,保证数据一致性
这里再啰嗦一点,之前一直吐槽EurekaClient注册的逻辑,今天看了EurekaClient注册表抓取的逻辑后,不由的感叹设计的精妙之处,这里说的精妙是指EurekaServer端对于注册表读取逻辑的设计,缓存逻辑以及增量获取时Hash一致性的判断,真的很妙,感觉又学到了不少东西。读完这段代码 一大早就很兴奋,哈哈哈,一起看看吧。
说明
原创不易,如若转载 请标明来源:一枝花算不算浪漫
EurekaClient全量抓取注册表逻辑
一直在想着怎么才能把自己看完代码后的理解用文字表达出来,这里采用一种新模式吧,先画图,然后源码,然后解读。
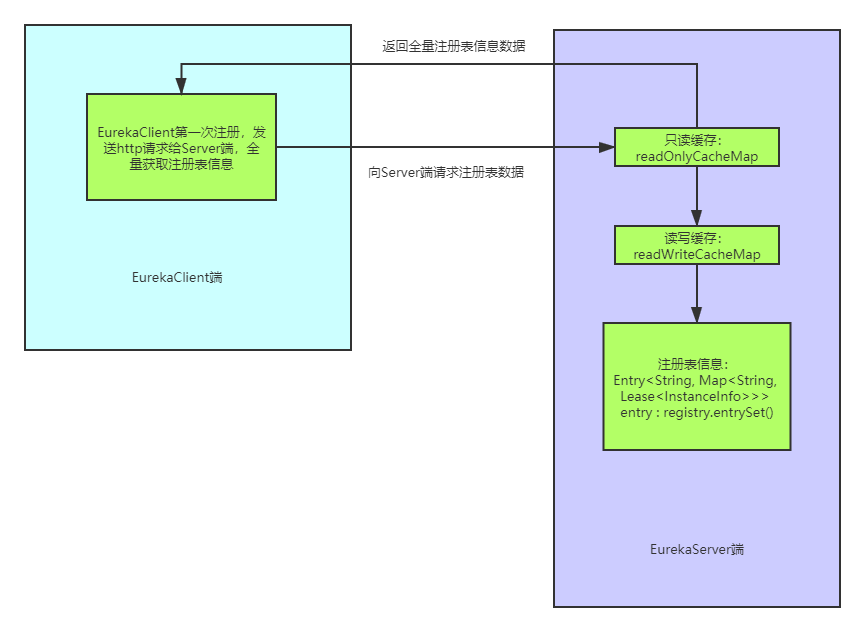
图片看起来很简单,Client发送Http请求给Server端,Server端返回全量的注册表信息给Client端。接下来就是跟进代码一步步分析,这里先有个大概印象
源码解析
- Client端发送获取全量注册表请求
@Inject
DiscoveryClient(ApplicationInfoManager applicationInfoManager, EurekaClientConfig config, AbstractDiscoveryClientOptionalArgs args,
Provider<BackupRegistry> backupRegistryProvider, EndpointRandomizer endpointRandomizer) {
// 省略很多无关代码
if (clientConfig.shouldFetchRegistry() && !fetchRegistry(false)) {
fetchRegistryFromBackup();
}
}
private boolean fetchRegistry(boolean forceFullRegistryFetch) {
Stopwatch tracer = FETCH_REGISTRY_TIMER.start();
try {
// If the delta is disabled or if it is the first time, get all
// applications
Applications applications = getApplications();
if (clientConfig.shouldDisableDelta()
|| (!Strings.isNullOrEmpty(clientConfig.getRegistryRefreshSingleVipAddress()))
|| forceFullRegistryFetch
|| (applications == null)
|| (applications.getRegisteredApplications().size() == 0)
|| (applications.getVersion() == -1)) //Client application does not have latest library supporting delta
{
logger.info("Disable delta property : {}", clientConfig.shouldDisableDelta());
logger.info("Single vip registry refresh property : {}", clientConfig.getRegistryRefreshSingleVipAddress());
logger.info("Force full registry fetch : {}", forceFullRegistryFetch);
logger.info("Application is null : {}", (applications == null));
logger.info("Registered Applications size is zero : {}",
(applications.getRegisteredApplications().size() == 0));
logger.info("Application version is -1: {}", (applications.getVersion() == -1));
getAndStoreFullRegistry();
} else {
getAndUpdateDelta(applications);
}
applications.setAppsHashCode(applications.getReconcileHashCode());
logTotalInstances();
} catch (Throwable e) {
logger.error(PREFIX + "{} - was unable to refresh its cache! status = {}", appPathIdentifier, e.getMessage(), e);
return false;
} finally {
if (tracer != null) {
tracer.stop();
}
}
// 删减掉一些代码
// registry was fetched successfully, so return true
return true;
}
private void getAndStoreFullRegistry() throws Throwable {
long currentUpdateGeneration = fetchRegistryGeneration.get();
logger.info("Getting all instance registry info from the eureka server");
Applications apps = null;
EurekaHttpResponse<Applications> httpResponse = clientConfig.getRegistryRefreshSingleVipAddress() == null
? eurekaTransport.queryClient.getApplications(remoteRegionsRef.get())
: eurekaTransport.queryClient.getVip(clientConfig.getRegistryRefreshSingleVipAddress(), remoteRegionsRef.get());
if (httpResponse.getStatusCode() == Status.OK.getStatusCode()) {
apps = httpResponse.getEntity();
}
logger.info("The response status is {}", httpResponse.getStatusCode());
if (apps == null) {
logger.error("The application is null for some reason. Not storing this information");
} else if (fetchRegistryGeneration.compareAndSet(currentUpdateGeneration, currentUpdateGeneration + 1)) {
localRegionApps.set(this.filterAndShuffle(apps));
logger.debug("Got full registry with apps hashcode {}", apps.getAppsHashCode());
} else {
logger.warn("Not updating applications as another thread is updating it already");
}
}这里就不再赘述Client端是如何一步步跟进到发请求的代码的,因为之前通过单元测试代码已经搞清楚了Server端接受请求的类是ApplicationsResource.java, Client端主要核心的代码也在 DiscoveryClient.java中。
代码还是之前看了好多遍的祖传代码,只是省略了很多内容,只展示我们需要分析的地方。
clientConfig.shouldFetchRegistry() 这个配置默认是true,然后fetchRegistry方法中getAndStoreFullRegistry(),因为第一次都是获取全量注册表信息,继续往后。
getAndStoreFullRegistry 方法中可以看到就是发送Http请求给Server端,然后等待Server端返回全量注册表信息。
这里获取全量请求执行的是eurekaTransport.queryClient.getApplications(remoteRegionsRef.get())
然后再一路往下,跟踪到 AbstractJersey2EurekaHttpClient.java中,getApplicationsInternal方法,发下发送的是GET请求,于是到Server端ApplicationsResource.java中的GET方法getContainers中查看逻辑
server端返回注册表信息集合的多级缓存机制
上面已经看了Client端 发送抓取全量注册表的逻辑,到了Server端查看ApplicationsResource.java中的GET方法getContainers,接着看看这部分的源码
private final ResponseCache responseCache;
@GET
public Response getContainers(@PathParam("version") String version,
@HeaderParam(HEADER_ACCEPT) String acceptHeader,
@HeaderParam(HEADER_ACCEPT_ENCODING) String acceptEncoding,
@HeaderParam(EurekaAccept.HTTP_X_EUREKA_ACCEPT) String eurekaAccept,
@Context UriInfo uriInfo,
@Nullable @QueryParam("regions") String regionsStr) {
// 省略部分代码
Key cacheKey = new Key(Key.EntityType.Application,
ResponseCacheImpl.ALL_APPS,
keyType, CurrentRequestVersion.get(), EurekaAccept.fromString(eurekaAccept), regions
);
Response response;
if (acceptEncoding != null && acceptEncoding.contains(HEADER_GZIP_VALUE)) {
response = Response.ok(responseCache.getGZIP(cacheKey))
.header(HEADER_CONTENT_ENCODING, HEADER_GZIP_VALUE)
.header(HEADER_CONTENT_TYPE, returnMediaType)
.build();
} else {
response = Response.ok(responseCache.get(cacheKey))
.build();
}
CurrentRequestVersion.remove();
return response;
}这里接收到Client端的请求后,会去responseCache 中去拿去全量的数据信息。
从属性名字就可以看出来,这个是从缓存中获取数据。
ResponseCacheImpl.java
String get(final Key key, boolean useReadOnlyCache) {
Value payload = getValue(key, useReadOnlyCache);
if (payload == null || payload.getPayload().equals(EMPTY_PAYLOAD)) {
return null;
} else {
return payload.getPayload();
}
}
Value getValue(final Key key, boolean useReadOnlyCache) {
Value payload = null;
try {
if (useReadOnlyCache) {
final Value currentPayload = readOnlyCacheMap.get(key);
if (currentPayload != null) {
payload = currentPayload;
} else {
payload = readWriteCacheMap.get(key);
readOnlyCacheMap.put(key, payload);
}
} else {
payload = readWriteCacheMap.get(key);
}
} catch (Throwable t) {
logger.error("Cannot get value for key : {}", key, t);
}
return payload;
}这里主要关注getValue方法,这里主要有两个map,一个是readOnlyCacheMap 另一个是readWriteCacheMap, 这里我们光看名字就可以知道一个是只读缓存,一个是读写缓存,这里用了两层的缓存结构,如果只读缓存不为空 则直接返回,如果为空查询可读缓存。
关于缓存的讲解 我们继续往下看。
server端注册表多级缓存过期机制:主动+定时+被动
继续看缓存相关,用到了多级缓存这里可能就会存在一些疑问:
- 两级缓存数据如何保存同步?
- 缓存数据如何过期?
带着疑问我们来继续看源代码
private final ConcurrentMap<Key, Value> readOnlyCacheMap = new ConcurrentHashMap<Key, Value>();
private final LoadingCache<Key, Value> readWriteCacheMap;
ResponseCacheImpl(EurekaServerConfig serverConfig, ServerCodecs serverCodecs, AbstractInstanceRegistry registry) {
// 省略部分代码
long responseCacheUpdateIntervalMs = serverConfig.getResponseCacheUpdateIntervalMs();
this.readWriteCacheMap =
CacheBuilder.newBuilder().initialCapacity(serverConfig.getInitialCapacityOfResponseCache())
.expireAfterWrite(serverConfig.getResponseCacheAutoExpirationInSeconds(), TimeUnit.SECONDS)
.removalListener(new RemovalListener<Key, Value>() {
@Override
public void onRemoval(RemovalNotification<Key, Value> notification) {
Key removedKey = notification.getKey();
if (removedKey.hasRegions()) {
Key cloneWithNoRegions = removedKey.cloneWithoutRegions();
regionSpecificKeys.remove(cloneWithNoRegions, removedKey);
}
}
})
.build(new CacheLoader<Key, Value>() {
@Override
public Value load(Key key) throws Exception {
if (key.hasRegions()) {
Key cloneWithNoRegions = key.cloneWithoutRegions();
regionSpecificKeys.put(cloneWithNoRegions, key);
}
Value value = generatePayload(key);
return value;
}
});
// 省略部分代码
}readOnlyCacheMap用的是ConcurrentHashMap,线程安全的。
readWriteCacheMap用的是GuavaCache,不懂的小伙伴可以自己阅读以下,我之前的博客也有讲解这个,这个是谷歌开源的Guava项目基于内存的缓存,其内部也是实现的Map结构。主要重点我们来看下GuavaCache,这里初始化大小是
serverConfig.getInitialCapacityOfResponseCache()默认是1000,也是Map的初始大小。
expireAfterWrite刷新时间是serverConfig.getResponseCacheAutoExpirationInSeconds()默认时间是180s。
接着是build方法,这里获取注册表信息就是用的generatePayload方法,如果查询readWriteCacheMap中注册表信息为空,这会执行build方法。
继续跟进generatePayload方法:
private Value generatePayload(Key key) {
Stopwatch tracer = null;
try {
String payload;
switch (key.getEntityType()) {
case Application:
boolean isRemoteRegionRequested = key.hasRegions();
if (ALL_APPS.equals(key.getName())) {
if (isRemoteRegionRequested) {
tracer = serializeAllAppsWithRemoteRegionTimer.start();
payload = getPayLoad(key, registry.getApplicationsFromMultipleRegions(key.getRegions()));
} else {
tracer = serializeAllAppsTimer.start();
payload = getPayLoad(key, registry.getApplications());
}
} else if (ALL_APPS_DELTA.equals(key.getName())) {
if (isRemoteRegionRequested) {
tracer = serializeDeltaAppsWithRemoteRegionTimer.start();
versionDeltaWithRegions.incrementAndGet();
versionDeltaWithRegionsLegacy.incrementAndGet();
payload = getPayLoad(key,
registry.getApplicationDeltasFromMultipleRegions(key.getRegions()));
} else {
tracer = serializeDeltaAppsTimer.start();
versionDelta.incrementAndGet();
versionDeltaLegacy.incrementAndGet();
payload = getPayLoad(key, registry.getApplicationDeltas());
}
}
break;
}
return new Value(payload);
} finally {
if (tracer != null) {
tracer.stop();
}
}
}这个代码删减了一部分,到时增量抓取注册表也会走这个逻辑,ALL_APPS就是全量抓取,ALL_APPS_DELTA就是增量抓取的意思,这里先插个眼,一会增量抓取注册表的逻辑再回头看。
上面的逻辑我们只需要关注registry.getApplicationsFromMultipleRegions 即可,这个是获取注册表的逻辑。接着继续往下跟代码:
AbstractInstanceRegistry.java
public Applications getApplicationsFromMultipleRegions(String[] remoteRegions) {
Applications apps = new Applications();
apps.setVersion(1L);
for (Entry<String, Map<String, Lease<InstanceInfo>>> entry : registry.entrySet()) {
Application app = null;
if (entry.getValue() != null) {
for (Entry<String, Lease<InstanceInfo>> stringLeaseEntry : entry.getValue().entrySet()) {
Lease<InstanceInfo> lease = stringLeaseEntry.getValue();
if (app == null) {
app = new Application(lease.getHolder().getAppName());
}
app.addInstance(decorateInstanceInfo(lease));
}
}
if (app != null) {
apps.addApplication(app);
}
}
if (includeRemoteRegion) {
for (String remoteRegion : remoteRegions) {
RemoteRegionRegistry remoteRegistry = regionNameVSRemoteRegistry.get(remoteRegion);
if (null != remoteRegistry) {
Applications remoteApps = remoteRegistry.getApplications();
for (Application application : remoteApps.getRegisteredApplications()) {
if (shouldFetchFromRemoteRegistry(application.getName(), remoteRegion)) {
logger.info("Application {} fetched from the remote region {}",
application.getName(), remoteRegion);
Application appInstanceTillNow = apps.getRegisteredApplications(application.getName());
if (appInstanceTillNow == null) {
appInstanceTillNow = new Application(application.getName());
apps.addApplication(appInstanceTillNow);
}
for (InstanceInfo instanceInfo : application.getInstances()) {
appInstanceTillNow.addInstance(instanceInfo);
}
} else {
logger.debug("Application {} not fetched from the remote region {} as there exists a "
+ "whitelist and this app is not in the whitelist.",
application.getName(), remoteRegion);
}
}
} else {
logger.warn("No remote registry available for the remote region {}", remoteRegion);
}
}
}
apps.setAppsHashCode(apps.getReconcileHashCode());
return apps;
}这里再看到 registry.entrySet()是不是会特别亲切?Map<String, Map<String, Lease<InstanceInfo>> 我们上一篇讲Client注册的时候 就是将注册信息放入到registry对应这个数据结构中的,果不其然,这里拿到所有的注册信息,然后封装到Applications 对象中的。
这里最后apps.setAppsHashCode()逻辑,先插个眼 后面讲增量同步有类似的逻辑,后面再回头看。接着再回头看 返回数据后 readWriteCacheMap 的操作逻辑。
if (shouldUseReadOnlyResponseCache) {
timer.schedule(getCacheUpdateTask(),
new Date(((System.currentTimeMillis() / responseCacheUpdateIntervalMs) * responseCacheUpdateIntervalMs)
+ responseCacheUpdateIntervalMs),
responseCacheUpdateIntervalMs);
}
private TimerTask getCacheUpdateTask() {
return new TimerTask() {
@Override
public void run() {
logger.debug("Updating the client cache from response cache");
for (Key key : readOnlyCacheMap.keySet()) {
if (logger.isDebugEnabled()) {
logger.debug("Updating the client cache from response cache for key : {} {} {} {}",
key.getEntityType(), key.getName(), key.getVersion(), key.getType());
}
try {
CurrentRequestVersion.set(key.getVersion());
Value cacheValue = readWriteCacheMap.get(key);
Value currentCacheValue = readOnlyCacheMap.get(key);
if (cacheValue != currentCacheValue) {
readOnlyCacheMap.put(key, cacheValue);
}
} catch (Throwable th) {
logger.error("Error while updating the client cache from response cache for key {}", key.toStringCompact(), th);
} finally {
CurrentRequestVersion.remove();
}
}
}
};
}这里是起了一个调度任务,会去定时比较一级和二级缓存是否一致,如果不一致 就会用二级缓存覆盖一级缓存。这就回答了上面的第一个问题,两级缓存一致性的问题,默认30s执行一次。所以这里仍会有问题,可能缓存在30s内会存在不一致的情况,这里用的是最终一致的思想。
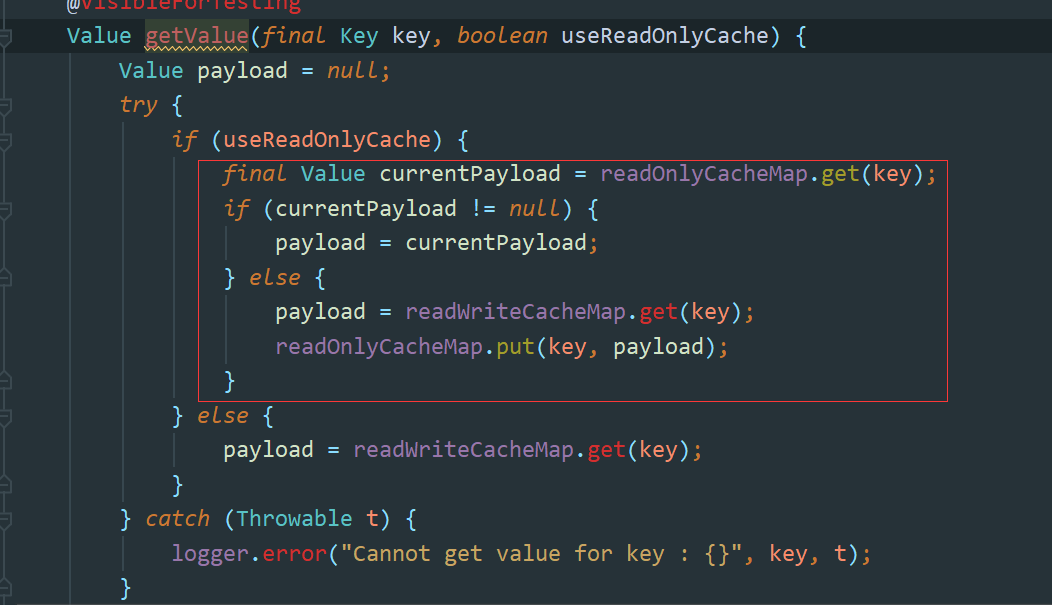
紧接着 读写缓存获取到数据后再去回写只读缓存,这是上面ResponseCacheImpl.java 的逻辑,到了这里 全量抓取注册表的代码都已经看完了,这里主要的亮点是使用了两级缓存策略来返回对应的数据。
接着整理下过期的几个机制,也是回应上面抛出的第二个问题。
用一张图作为总结:
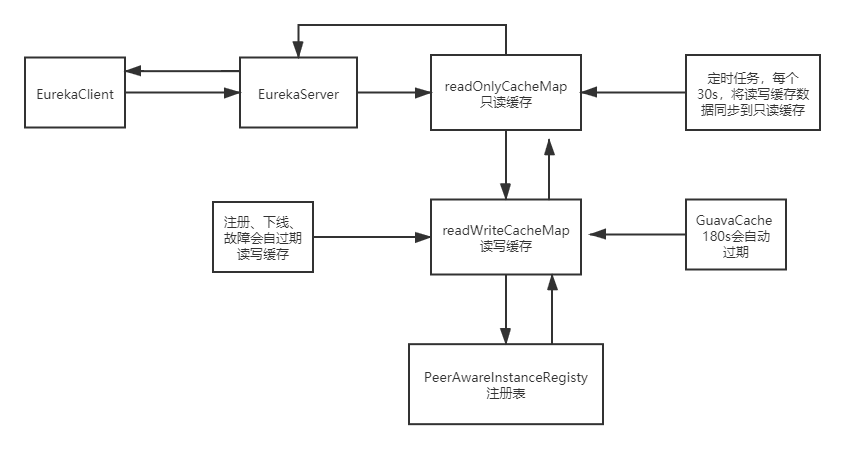
主动过期
readWriteCacheMap,读写缓存有新的服务实例发生注册、下线、故障的时候,就会去刷新readWriteCacheMap(在Client注册的时候,AbstractInstanceRegistry中register方法最后会有一个invalidateCache()方法)
比如说现在有一个服务A,ServiceA,有一个新的服务实例,Instance010来注册了,注册完了之后,其实必须是得刷新这个缓存的,然后就会调用ResponseCache.invalidate(),将之前缓存好的ALL_APPS这个key对应的缓存,给他过期掉
将readWriteCacheMap中的ALL_APPS缓存key,对应的缓存给过期掉
定时过期
readWriteCacheMap在构建的时候,指定了一个自动过期的时间,默认值就是180秒,所以你往readWriteCacheMap中放入一个数据过后,自动会等180秒过后,就将这个数据给他过期了
被动过期
readOnlyCacheMap怎么过期呢?
默认是每隔30秒,执行一个定时调度的线程任务,TimerTask,有一个逻辑,会每隔30秒,对readOnlyCacheMap和readWriteCacheMap中的数据进行一个比对,如果两块数据是不一致的,那么就将readWriteCacheMap中的数据放到readOnlyCacheMap中来。比如说readWriteCacheMap中,ALL_APPS这个key对应的缓存没了,那么最多30秒过后,就会同步到readOnelyCacheMap中去。
client端增量抓取注册表逻辑
上面抓取全量注册表的代码已经说了,这里来讲一下增量抓取,入口还是在DiscoverClient.java
中,当初始化完DiscoverClient.java 后会执行一个初始化定时任务的方法initScheduledTasks(), 其中这个里面就会每隔30s 增量抓取一次注册表信息。
这里就不跟着这里的逻辑一步步看了,看过上面的代码后 应该会对这里比较清晰了,这里我们直接看Server端代码了。
还记的我们上面插过的眼,获取全量用的是ALL_APPS 增量用的是ALL_APPS_DELTA, 所以我们这里只看增量的逻辑就行了。
else if (ALL_APPS_DELTA.equals(key.getName())) {
if (isRemoteRegionRequested) {
tracer = serializeDeltaAppsWithRemoteRegionTimer.start();
versionDeltaWithRegions.incrementAndGet();
versionDeltaWithRegionsLegacy.incrementAndGet();
payload = getPayLoad(key,
registry.getApplicationDeltasFromMultipleRegions(key.getRegions()));
} else {
tracer = serializeDeltaAppsTimer.start();
versionDelta.incrementAndGet();
versionDeltaLegacy.incrementAndGet();
payload = getPayLoad(key, registry.getApplicationDeltas());
}
}上面只是截取了部分代码,这里直接看主要的逻辑registry.getApplicationDeltasFromMultipleRegions即可,这个和全量的方法名只有一个Deltas的区别。
public Applications getApplicationDeltasFromMultipleRegions(String[] remoteRegions) {
if (null == remoteRegions) {
remoteRegions = allKnownRemoteRegions; // null means all remote regions.
}
boolean includeRemoteRegion = remoteRegions.length != 0;
if (includeRemoteRegion) {
GET_ALL_WITH_REMOTE_REGIONS_CACHE_MISS_DELTA.increment();
} else {
GET_ALL_CACHE_MISS_DELTA.increment();
}
Applications apps = new Applications();
apps.setVersion(responseCache.getVersionDeltaWithRegions().get());
Map<String, Application> applicationInstancesMap = new HashMap<String, Application>();
try {
write.lock();
Iterator<RecentlyChangedItem> iter = this.recentlyChangedQueue.iterator();
logger.debug("The number of elements in the delta queue is :{}", this.recentlyChangedQueue.size());
while (iter.hasNext()) {
Lease<InstanceInfo> lease = iter.next().getLeaseInfo();
InstanceInfo instanceInfo = lease.getHolder();
logger.debug("The instance id {} is found with status {} and actiontype {}",
instanceInfo.getId(), instanceInfo.getStatus().name(), instanceInfo.getActionType().name());
Application app = applicationInstancesMap.get(instanceInfo.getAppName());
if (app == null) {
app = new Application(instanceInfo.getAppName());
applicationInstancesMap.put(instanceInfo.getAppName(), app);
apps.addApplication(app);
}
app.addInstance(new InstanceInfo(decorateInstanceInfo(lease)));
}
if (includeRemoteRegion) {
for (String remoteRegion : remoteRegions) {
RemoteRegionRegistry remoteRegistry = regionNameVSRemoteRegistry.get(remoteRegion);
if (null != remoteRegistry) {
Applications remoteAppsDelta = remoteRegistry.getApplicationDeltas();
if (null != remoteAppsDelta) {
for (Application application : remoteAppsDelta.getRegisteredApplications()) {
if (shouldFetchFromRemoteRegistry(application.getName(), remoteRegion)) {
Application appInstanceTillNow =
apps.getRegisteredApplications(application.getName());
if (appInstanceTillNow == null) {
appInstanceTillNow = new Application(application.getName());
apps.addApplication(appInstanceTillNow);
}
for (InstanceInfo instanceInfo : application.getInstances()) {
appInstanceTillNow.addInstance(new InstanceInfo(instanceInfo));
}
}
}
}
}
}
}
Applications allApps = getApplicationsFromMultipleRegions(remoteRegions);
apps.setAppsHashCode(allApps.getReconcileHashCode());
return apps;
} finally {
write.unlock();
}
}这里代码还是比较多的,我们只需要抓住重点即可:
- 从
recentlyChangedQueue中获取注册信息,从名字可以看出来 这是最近改变的client注册信息的队列 - 使用writeLock,因为这里是获取增量注册信息,是从队列中获取,如果不加写锁,那么获取的时候又有新数据加入队列中,新数据会获取不到的
基于上面第一点,我们来看看这个队列怎么做的:
- 数据结构:
ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue AbstractInstanceRegistry.java初始化的时候会启动一个定时任务,默认30s中执行一次。如果注册时间小于当前时间的180s,就会放到这个队列中
AbstractInstanceRegistry.java具体代码如下:
protected AbstractInstanceRegistry(EurekaServerConfig serverConfig, EurekaClientConfig clientConfig, ServerCodecs serverCodecs) {
this.serverConfig = serverConfig;
this.clientConfig = clientConfig;
this.serverCodecs = serverCodecs;
this.recentCanceledQueue = new CircularQueue<Pair<Long, String>>(1000);
this.recentRegisteredQueue = new CircularQueue<Pair<Long, String>>(1000);
this.renewsLastMin = new MeasuredRate(1000 * 60 * 1);
this.deltaRetentionTimer.schedule(getDeltaRetentionTask(),
serverConfig.getDeltaRetentionTimerIntervalInMs(),
serverConfig.getDeltaRetentionTimerIntervalInMs());
}
private TimerTask getDeltaRetentionTask() {
return new TimerTask() {
@Override
public void run() {
Iterator<RecentlyChangedItem> it = recentlyChangedQueue.iterator();
while (it.hasNext()) {
if (it.next().getLastUpdateTime() <
System.currentTimeMillis() - serverConfig.getRetentionTimeInMSInDeltaQueue()) {
it.remove();
} else {
break;
}
}
}
};
}这里就能看明白了,也就是说增量抓取会获取EurekaServer端3分钟内保存的变动的Client信息。
最后还有一个亮点,我们上面说过,无论是全量抓取还是增量抓取,最后都会返回一个全量注册表的hash值,代码是apps.setAppsHashCode(allApps.getReconcileHashCode());, 其中apps就是返回的Applications中的属性,最后我们再看看这个hashCode的用法。
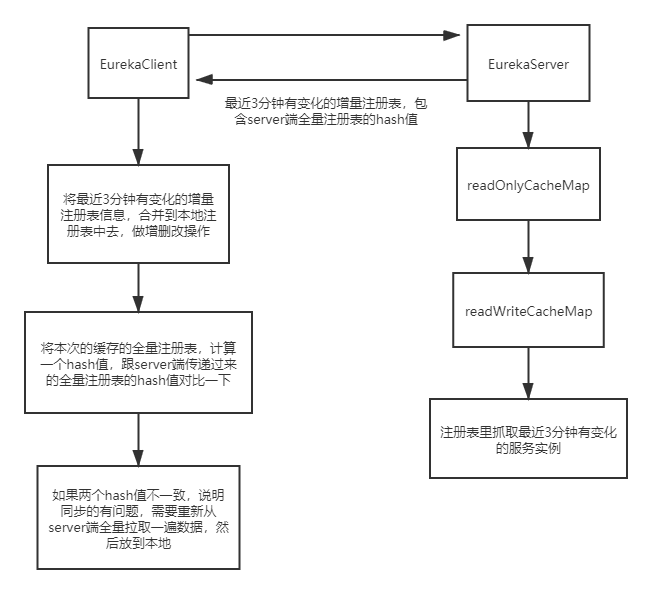
回到DiscoveryClient.java, 找到refreshRegistry 方法,然后一路跟踪到getAndUpdateDelta方法,这里具体代码我就不贴了,流程如下:
- 获取delta增量数据
- 根据增量数据和本地注册表数据进行合并
- 计算中本地注册表信息的hashCode值
- 如果本地hashCode值和server端返回的hashCode值不一致则再全量获取一次注册表信息
最后一张图总结增量注册表抓取逻辑:
总结&感悟
这篇文章写得有点长了,确实自己也很用心去写了,我感觉这里多级缓存机制+增量数据Hash一致性的对比方案做的很优秀,如果要我做一个数据全量+增量同步 我也会借鉴这种方案。
看源码 能够学到的就是别人的设计思想。总结的部分可以看上面的一些图,注册表抓取的源码学习就到这了,后面 还准备看下心跳机制、保护机制、集群等等一些的源码。
这里读完源码之后会发下一个问题:
假设有服务实例注册、下线、故障,要调用这个服务的其他服务,可能会过30秒之后才能感知倒,为什么呢?因为这里再获取服务注册表的时候,有一个多级缓存的机制,最多是30秒后才会去更新一级缓存。
申明
本文章首发自本人博客:https://www.cnblogs.com/wang-meng 和公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫

加载全部内容