pandas将list数据拆分成行或列的实现
XerCis 人气:0这篇文章主要介绍了pandas将list数据拆分成行或列的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
数据
import numpy as np
import pandas as pd
data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
data
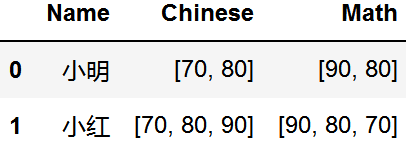
拆分成行
def split_row(data, column):
'''拆分成行
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
row_len = list(map(len, data[column].values))
rows = []
for i in data.columns:
if i == column:
row = np.concatenate(data[i].values)
else:
row = np.repeat(data[i].values, row_len)
rows.append(row)
return pd.DataFrame(np.dstack(tuple(rows))[0], columns=data.columns)
split_row(data, column='Chinese')
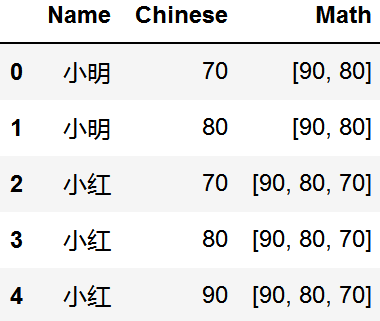
拆分成列

from copy import deepcopy
def split_col(data, column):
'''拆分成列
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
data = deepcopy(data)
max_len = max(list(map(len, data[column].values))) # 最大长度
new_col = data[column].apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[column + str(i)] = j
return data
split_col(data, column='Chinese')
其他情况
1. 批量处理+不要原列

def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(len, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data
2. 带int和list数据
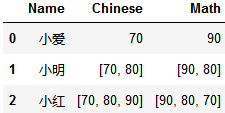
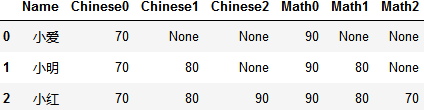
转成这样:
import numpy as np
import pandas as pd
data = [{'Name': '小爱', 'Chinese': 70, 'Math': 90},
{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(lambda x:len(x) if isinstance(x, list) else 1, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x+[None]*(max_len - len(x)) if isinstance(x, list) else [x]+[None]*(max_len - 1)) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data
参考文献
加载全部内容