小白学 Python 爬虫(24):2019 豆瓣电影排行
极客挖掘机 人气:0
人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(1):开篇
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(5):前置准备(四)数据库基础
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(7):HTTP 基础
小白学 Python 爬虫(8):网页基础
小白学 Python 爬虫(9):爬虫基础
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(19):Xpath 基操
小白学 Python 爬虫(20):Xpath 进阶
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
引言
从本篇的标题各位同学应该已经猜到了,本篇又到了实战环节~~~
2019 已经快过完了,按照本文推送的时间预估,到 2020 应该还有十来天的时间,又到了各个公司出各种 2019 榜单的时间,小编这里呢,就先帮豆瓣搞一个 2019 电影评分排行榜,希望豆瓣官方看到不要打我。
郑重声明: 本文仅限用作学习等目的。
分析
还是先看一下我们要爬取的页面:
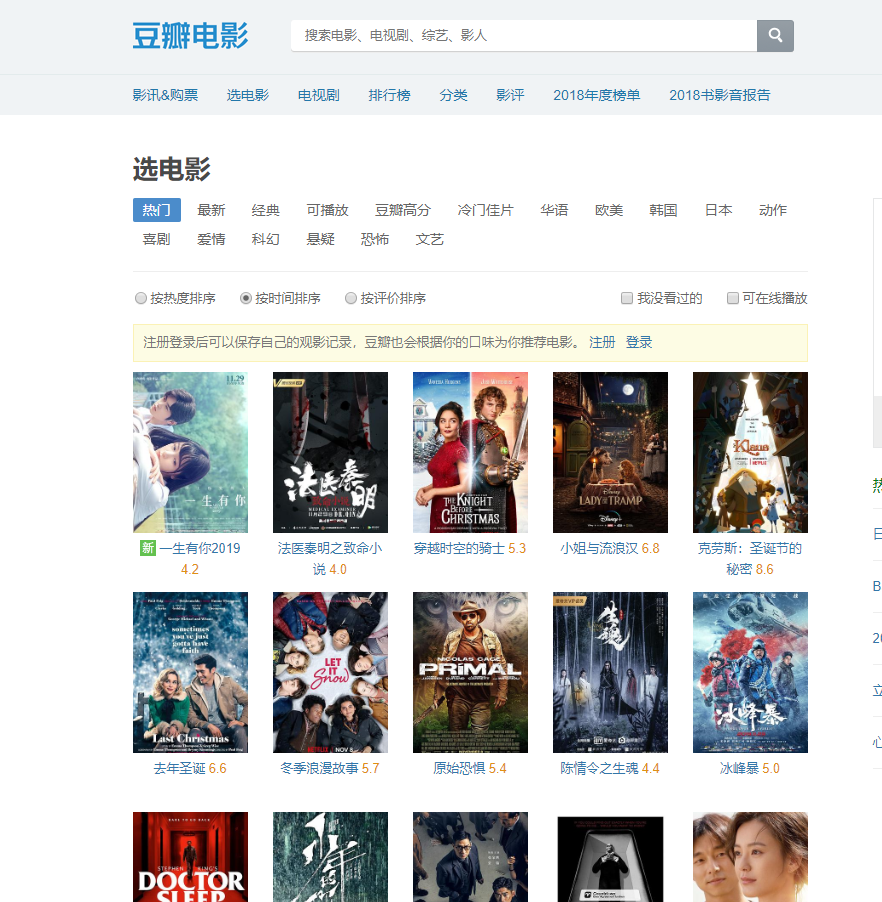
链接:
https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0思维敏捷的同学看着上面这个链接可能就已经发现了什么,对的,这个链接上已经有分页信息了。
page_limit 应该是一页的元素, page_start 应该是这一页开始的一个序号。
我们往下翻一下页面,看看下面有没有下一页之类的按钮,翻几页看下地址栏的变化是否和我们推测的一致。

emmmmmmmmm
小编猜错了,这里不是下一页,是加载更多,不过问题不大,一个意思,先点一下我们看下地址栏:
https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=20和前面一个地址作对比可以发现,只有最后的 page_start 参数有变化,说明我们刚才上面的猜测没有问题。
加载更多多点几次,可以发现,这里的电影是可以一直往后排的,可以加载到 2018 年的数据:
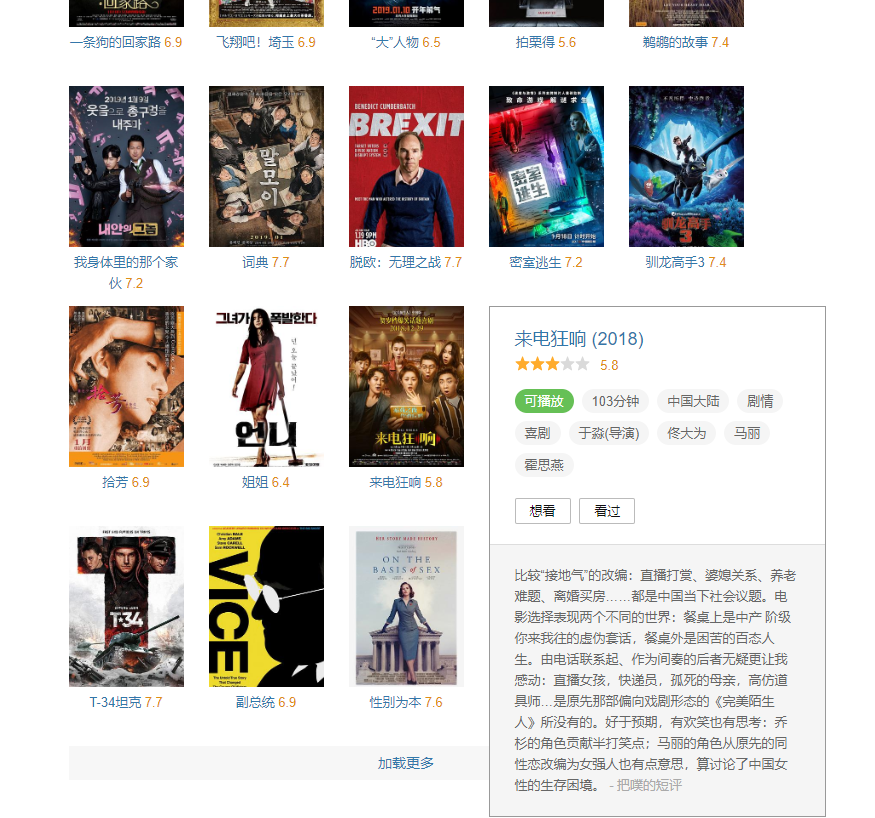
emmmmmmmmm,有点尴尬,这个数据竟然手动翻出来了,理论上是应该程序自己判断的。
这里的悬浮层上已经显示了我们想要的数据,接下来的问题是,我们如何获得这个悬浮层上的数据,直接从 DOM 节点来取可以么?
显然是不行的,不信可以自己动手试试,每个电影的悬浮层其实都是同一个 DOM 节点,只是里面填充的数据不同,显然这个 DOM 节点中的数据是鼠标挪上去的时候才动态加载出来的。
那么我们从哪里能看到加载数据的来源呢?
如果上一篇实战有仔细看实操过的同学应该已经想到了, Chrome 浏览器开发者模式中的 Network 标签。
没错,就是这里,我们看一下:
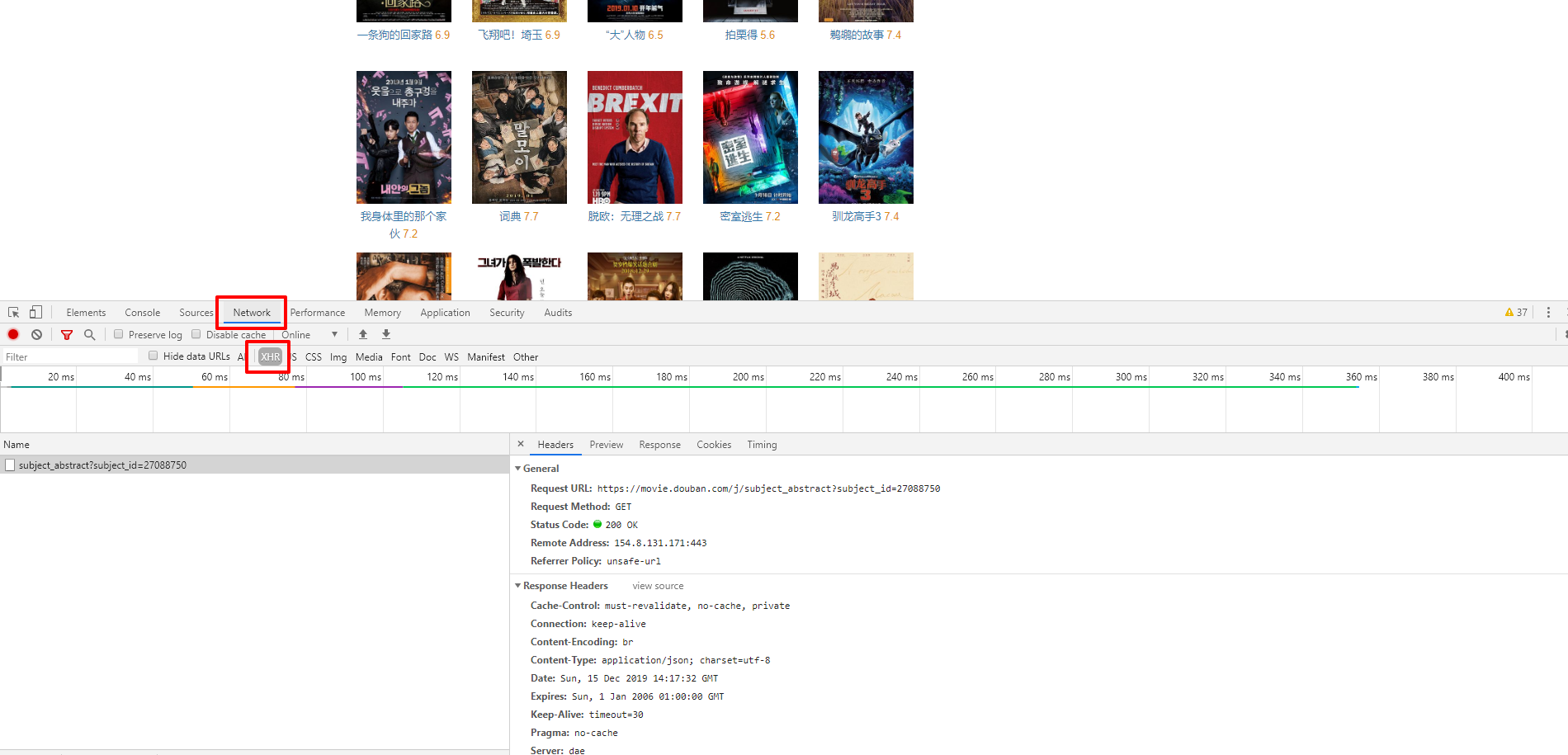
首先选择 Network 标签,然后在下面的标签上选择 XHR 。然后鼠标在不同的电影上移动,可以看到鼠标每次移到一张图片上,就会有一个请求,我们看一下这个请求的响应信息:
{"r":0,"subject":{"episodes_count":"","star":"40","blacklisted":"available","title":"我身体里的那个家伙 내안의 그놈 (2019)","url":"https:\/\/movie.douban.com\/subject\/27088750\/","collection_status":"","rate":"7.2","short_comment":{"content":"男主真的他妈帅 但是我真的接受不了和罗美兰打k ","author":"SOUL"},"is_tv":false,"subtype":"Movie","directors":["姜孝镇"],"actors":["郑振永","朴圣雄","罗美兰","李垂珉","李俊赫","金光奎","闵智雅","尹敬浩","金贤穆","朴庆惠","赵贤荣","尹颂雅","智燦","金凡振 ","郑元昌","孙光业","黄仁俊","Dae-han Kim"],"duration":"122分钟","region":"韩国","playable":false,"id":"27088750","types":["剧情","喜剧"],"release_year":"2019"}}那么我们剩下要关心的就是这个请求的地址了,先看下这个请求的地址:
https://movie.douban.com/j/subject_abstract?subject_id=27088750这里看起来好像只有最后一个 subject_id 参数是变化的,其他的都是定死的,多看几个请求检验下我们的推测,小编这里就不检验了,免得嫌弃说小编水内容。
还有一个问题,最后这个 subject_id 的数据从哪里来,好像没见过的,小编凭借自己多年丰富的开发经验,猜测这个数据应该是在页面的上的。我们接着看下这个电影的页面 DOM 结构。

看到了没,这里的数据是来源于 DOM 结构上的 data-id 属性。
PS:更新一件事情,一件异常尴尬的事情,小编偶然发现,点击加载更多的时候,实际上是对应了一个 API 接口,这个接口的访问地址如下:
https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=20这个在 NetWork 中有看到,如下图:

从图中可以看到,这里直接返回了 JSON 数据,并且这个 JSON 数据返回后,顺便还修改了地址栏的数据。
这里得到的数据如下:
{
"subjects":[
{
"rate":"6.7",
"cover_x":1382,
"title":"在无爱之森呐喊",
"url":"https://movie.douban.com/subject/30337760/",
"playable":false,
"cover":"https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2571542101.jpg",
"id":"30337760",
"cover_y":2048,
"is_new":false
}
]
}因为整体数据有 20 条,太长了放不下,小编这里仅保留了一条数据。
编码
有了上面的分析,其实写代码就已经很简单了,我们所有需要用到的数据都可以直接从 API 接口中直接获取到 JSON 的数据。
屡一下思路,首先我们从
https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0这个链接中直接获取电影的相关数据,这里对我们有用的数据是 id ,获取到这个 id 后,再从
https://movie.douban.com/j/subject_abstract?subject_id=27088750这个链接中获取到电影的详情数据,用上面得到的 id 替换这里的 subject_id 。
好像没页面 DOM 解析啥事儿了,哎,真的是一次失败的选题,下次再也不选豆瓣了。
代码内容有些简单,小编直接贴出来吧,数据还是在 Mysql 中开了一张表做存放:
import requests
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into douban2019(id, title, rate, short_comment, duration, subtype, region, release_year, create_date) values (%(id)s, %(title)s, %(rate)s, %(short_comment)s, %(duration)s, %(subtype)s, %(region)s, %(release_year)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
flag = True
def get_movie_list(page_start):
r = requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=' + str(page_start), headers = headers)
for item in r.json()['subjects']:
get_movie_info(item['id'])
def get_movie_info(subject_id):
r = requests.get('https://movie.douban.com/j/subject_abstract?subject_id=' + str(subject_id), headers=headers)
subject = r.json()['subject']
if subject['release_year'] != '2019':
global flag
flag = False
return
print(subject)
insert_data = {
"id": subject['id'],
"title": subject['title'],
"rate": subject['rate'],
"short_comment": subject['short_comment']['content'],
"duration": subject['duration'],
"subtype": subject['subtype'],
"region": subject['region'],
"release_year": subject['release_year']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(subject['title'], '写入完成')
def main():
num = 0
while(flag):
get_movie_list(num)
num += 20
if __name__ == '__main__':
main()小结
最后小编做了一下简单的统计,截止目前, 2019 豆瓣电影共计 312 部,评分超过 8.0 分的共计 37 部,超过 8.5 分的共计 14 部,超过 9.0 分的只有 1 部。
下表为评分超过 8.0 分的,还有没看过的小伙伴可以抓紧时间看一下咯~~
| 名称 | 评分 |
|---|---|
| 爱尔兰人 The Irishman (2019) | 9.1 |
| 银河英雄传说 Die Neue These 星乱 第1章 銀河英雄伝説 Die Neue These 星乱 第1章 (2019) | 8.9 |
| 小丑 Joker (2019) | 8.8 |
| 婚姻故事 Marriage Story (2019) | 8.8 |
| 玩具总动员4 Toy Story 4 (2019) | 8.7 |
| 寄生虫 기생충 (2019) | 8.7 |
| 代号基亚斯:复活的鲁路修 コードギアス 復活のルルーシュ (2019) | 8.7 |
| 82年生的金智英 82년생 김지영 (2019) | 8.7 |
| 克劳斯:圣诞节的秘密 Klaus (2019) | 8.6 |
| 痛苦与荣耀 Dolor y gloria (2019) | 8.6 |
| 青春期猪头少年不做怀梦少女的梦 青春ブタ野郎はゆめみる少女の夢を見ない (2019) | 8.6 |
| 复仇者联盟4:终局之战 Avengers: Endgame (2019) | 8.5 |
| 哪吒之魔童降世 (2019) | 8.5 |
| 普罗米亚 プロメア (2019) | 8.5 |
| 少年的你 (2019) | 8.4 |
| 少年泰坦出击大战少年泰坦 Teen Titans Go! vs Teen Titans (2019) | 8.4 |
| 悲惨世界 Les misérables (2019) | 8.4 |
| 我的一级兄弟 나의 특별한 형제 (2019) | 8.3 |
| 燃烧女子的肖像 Portrait de la jeune fille en feu (2019) | 8.3 |
| 再见钟情 Mon inconnue (2019) | 8.3 |
| 我在雨中等你 The Art of Racing in the Rain (2019) | 8.2 |
| 罗小黑战记 (2019) | 8.2 |
| 行骗天下JP:浪漫篇 コンフィデンスマンJP (2019) | 8.2 |
| 阿松 剧场版 劇場版 えいがのおそ松さん (2019) | 8.2 |
| 蜡笔小新:新婚旅行飓风之遗失的野原广志 映画クレヨンしんちゃん 新婚旅行ハリケーン ~失われたひろし~ (2019) | 8.2 |
| 驭风男孩 The Boy Who Harnessed the Wind (2019) | 8.1 |
| 对不起,我们错过了你 Sorry We Missed You (2019) | 8.1 |
| 续命之徒:绝命毒师电影 El Camino: A Breaking Bad Movie (2019) | 8.1 |
| 我失去了身体 J'ai perdu mon corps (2019) | 8.1 |
| 最初的梦想 Chhichhore (2019) | 8.1 |
| 千子2 センコロール コネクト (2019) | 8.0 |
| 地久天长 (2019) | 8.0 |
| 金发男子 Un rubio (2019) | 8.0 |
| 心理测量者SS2:第一卫士 PSYCHO-PASS サイコパス Sinners of the System Case.2「First Guardian」 (2019) | 8.0 |
| 漫长的告别 長いお別れ (2019) | 8.0 |
| 我的喜马拉雅 (2019) | 8.0 |
| 小委托人 어린 의뢰인 (2019) | 8.0 |
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
示例代码-Github
示例代码-Gitee
加载全部内容