用机器学习打造聊天机器人(六) 原理篇
程序员一一涤生 人气:0本文是用机器学习打造聊天机器人系列的第六篇,主要介绍代码中用到的相关算法的原理。了解算法原理,可以让我们知道程序背后都做了些什么,为什么有时候会出现错误以及什么场景下选择哪种算法会更合适。
- word2vec
我们使用的词向量模型就是基于word2vec训练的,word2vec 是 Google 在 2013 年推出的一个 NLP 工具,它的特点 是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间 的关系,挖掘词之间的联系。

word2vec 基于分布式表征(Dristributed Representation)的 思想,相比于 One hot 可以用更低维数的向量表示词汇。 有一个有趣的研究表明,用词向量表示我们的词时,我们可以发 现:King - Man + Woman = Queen。
word2vec 实现了 CBOW 和 Skip-Gram 两个神经网络 模型,SkyAAE 在训练词向量的时候就是使用的 CBOW 模型。
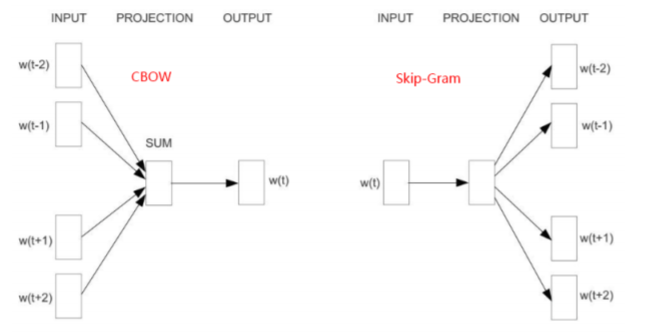
CBOW(Continuous Bag-of-Words,连续词袋)的核心思想是可 以用一个词的周围的词来预测这个词。该模型的训练输入是某一个特 征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的 词向量。 比如这段话:“...an efficient method for 【learning】 high quality distributed vector...”,我们要预测 learning,则 可以选取上下文大小为 4,也就是我们需要输出的词向量,上下文对 应的词有 8 个,前后各 4 个,这 8 个词是我们模型的输入。由于 CBOW 使用的是词袋模型,因此这 8 个词都是平等的,也就是不考虑他们和 我们关注的词之间的距离大小,只要在我们上下文之内即可。与 CBOW 相对应的是 Skip-Gram 模型,核心思想是可以用当前词去预测该词的 周围的词。
可以看出,当word2vec模型训练好了之后,词的向量表征也就确定了,以后再次使用的时候,输入一个词,模型就给你那个确定的向量。所以我们表示一个句子的时候,需要先分词,然后分别取出词的向量,然后通过一些方式将这些向量融合在一起来表示整个句子,比如累加后除以分词列表的长度。 - 余弦相似度
我们在语义匹配阶段使用的算法就是余弦相似度。余弦相似度是指通过测量两个向量的夹角的余弦值来度量它们 之间的相似性。我们知道,0 度角的余弦值是 1,而其他任何角度的 余弦值都不大于 1;并且其最小值是-1,但是余弦相似度通常用于 正空间,因此给出的值为 0 到 1 之间。两个向量有相同的指向时, 余弦相似度的值为 1;两个向量夹角为 90°时,余弦相似度的值为 0,所以两个向量之间的角度的余弦值可以确定两个向量是否大致指 向相同的方向。具体公式如下:
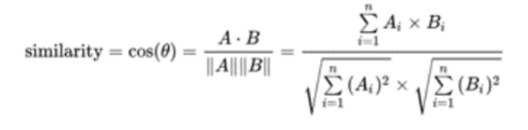
- 朴素贝叶斯
我们在意图分类阶段使用了多项式朴素贝叶斯算法来将输入的问题分到对应的意图类别下,让我们先来看看什么式朴素贝叶斯。朴素贝叶斯算法是基于贝叶斯定理与特征条件独立假设的分类 方法。 贝叶斯公式推导过程:

c
随机事件的其中一种情况,比如电影领域问答中的意图分类可能包括:闲聊,评分,上映时间,演员等,把用户问问题看成是随机事件,则用户问评分的问题就是随机事件的其中一种情况。
x
泛指与随机事件相关的因素,这里做为概率的条件。
P(c|x)
条件 x 下,c 出现的概率。比如 P(“评分”|“功夫这部电影评分怎么样?”)就是表示问题“功夫这部电影评分怎么样?”的意图是“评分”的概率。
P(x|c)
知出现 c 情况的条件下,条件 x 出现的概率,后验概率,可以根据历史数据计算得出。
P(c)
不考虑相关因素,c 出现的概率。
P(x)
不考虑相关因素,x 出现的概率。
由推导过程可以得到
P(c|x) = P(c)P(x|c)/P(x)
假设我们有电影领域问题和所属意图分类的数据集,那么P(c(i))=c(i)出现的次数/所有情况出现的总次数,(例如:c(i)可能是‘评分’意图或者‘上映时间’意图);
根据特征条件独立假设的朴素思想可以得出如下式子:
p(x|c) = Πp(xi|c) (1<=i<=d),d 为属性的个数
至此得到朴素贝叶斯的具体公式:(这里的 c 就是 c(i))

利用该公式进行分类的思想就是计算所有的 p(c(i)|x),然后取值(概率)最大的 c(i)做为所属分类。用公式表达如下:
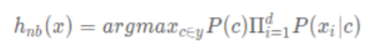
h 是基于朴素贝叶斯算法训练出来的 hypothesis(假设),它的值就是贝叶斯分类器对于给定的 x 因素下,最可能出现的情况c。y 是 c 的取值集合。这里去掉了 P(x)是因为它和 c 的概率没有关系,不影响取最大的 c。
朴素贝叶斯直观上理解,就是和样本属性以及样本类别的出现频率有关,利用已有的样本属性和样本类别计算出的各个概率,来代入新的样本的算式中算出属于各类别的概率,取出概率最大的做为新样本的类别。
所以为了计算准确,要满足如下几个条件:
• 各类别下的训练样本数量尽可能均衡
• 各训练样本的属性取值要覆盖所有可能的属性的值
• 引入拉普拉斯修正进行平滑处理。 - 多项式朴素贝叶斯
再选择朴素贝叶斯分类的时候,我们使用了one-hot的思想来构建句向量,其中的值都是0或1的离散型特征,所以使用多项式模型来计算 p(xi|c)会更合适(对于连续性的值,选用高斯模型更合适):
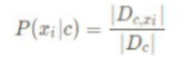
Dc 表示训练集 D 中第 c 类样本组成的集合,外加两条竖线 表示集合的元素数量;
Dc,xi 表示 Dc 中第 i 个特征上取值为 xi 的样本组成的集 合。
为避免出现某一维特征的值 xi 没在训练样本中与 c 类别同时出 现过,导致后验概率为 0 的情况,会做一些平滑处理:
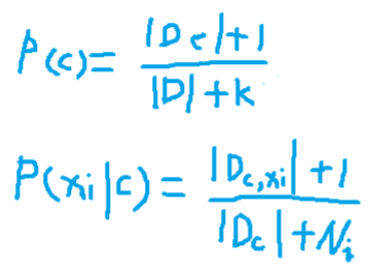
K表示总的类别数;
Ni表示第 i 个特征可能的取值的数量。 - 莱文斯坦距离
chatterbot的默认语义匹配算法采用的就是莱文斯坦距离,该算法又称Levenshtein距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。例如将kitten转成sitting:
kitten(k→s)sitten (e→i)sittin (→g)sitting
该算法的逻辑清晰简洁,但做为聊天机器人的语义匹配算法还是太简单了,所以我们并没有选择使用,具体原因在《手把手教你打造聊天机器人(三) 设计篇》中已经详细介绍,这里不再赘述。
本文是"手把手教你打造聊天机器人"系列的最后一篇,介绍了我们打造的聊天机器人的相关算法原理,下一篇会对本系列做一个总结。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
加载全部内容