centos下初识日志式文件系统(ext3)详解
人气:0大纲
1、日志式文件系统
2、ext3的优点
3、ext3的三种日志模式
4、选择日志模式
1、日志式文件系统
通常在系统运行中写入文件内容的同时,并没有写入文件的元数据(如权限、所有者及创建和访问时间),如果在写入文件内容之后与写入文件元数据之前的时间差里,系统非正常关闭,处于写入过程中的文件系统会非正常卸载,那么文件系统就会处于不一致的状态。当重新启动时,Linux会运行fsck程序,扫描整个文件系统,保证所有的文件块都被正确地分配或使用,找到被损坏的目录项并试图修复它。但是,fsck不保证一定能够修复损坏。出现这种情况时,文件中不一致的元数据会填满已丢失文件的空间,目录项中的文件项可能会丢失,也就造成文件的丢失。
为了尽量减少文件系统的不一致性,缩短操作系统的启动时间,文件系统需追踪引起系统改变的记录,这些记录存放在与文件系统相分离的地方,通常我们叫“日志”。一旦这些日志记录被安全地写入,日志文件系统就可以应用它们清除引起系统改变的记录,并将它们组成一个引起文件系统改变的集,将它们放在数据库的事务处理中,保持在状态下有效数据的正常运行,不与整个系统的性能发生冲突。在任何系统发生崩溃或需要重新启动时,数据就遵从日志文件中的信息记录进行恢复。由于日志文件中有定期的检查点,通常非常整齐。文件系统的设计主要考虑效率和性能方面的问题。
Linux可以支持许多日志文件系统,包括FAT、VFAT、HPFS(OS/2)、NTFS(Windows NT)、UFS、XFS、JFS、ReiserFS、ext2、ext3等。
2、ext3的优点
为什么你需要从ext2迁移到ext3呢?以下有四个主要原因:可用性、数据完整性、速度、易于迁移。
可用性
在非正常当机后(停电、系统崩溃),只有在通过e2fsck进行一致性校验后,ext2文件系统才能被装载使用。运行e2fsck的时间主要取决于 ext2文件系统的大小。校验稍大一些的文件系统(几十GB)需要很长时间。如果文件系统上的文件数量多,校验的时间则更长。校验几百个GB的文件系统可能需要一个小时或更长。这极大地限制了可用性。相比之下,除非发生硬件故障,即使非正常关机,ext3也不需要文件系统校验。这是因为数据是以文件系统始终保持一致方式写入磁盘的。在非正常关机后,恢复ext3文件系统的时间不依赖于文件系统的大小或文件数量,而依赖于维护一致性所需“日志”的大小。使用缺省日志设置,恢复时间仅需一秒(依赖于硬件速度)。
数据完整性
使用ext3 文件系统,在非正常关机时,数据完整性能得到可靠的保障。你可以选择数据保护的类型和级别。你可以选择保证文件系统一致,但是允许文件系统上的数据在非正常关机时受损;这是可以在某些状况下提高一些速度(但非所有状况)。你也可以选择保持数据的可靠性与文件系统一致;这意味着在当机后,你不会在新近写入的 文件中看到任何数据垃圾。这个保持数据的可靠性与文件系统一致的安全的选择是缺省设置。
速度
尽管ext3写入数据的次数多于ext2,但是ext3常常快于ext2(高数据流)。这是因为ext3的日志功能优化硬盘磁头的转动。你可以从3种日志模式中选择1种来优化速度,有选择地牺牲一些数据完整性。第 一种模式,data=writeback,有限地保证数据完整,允许旧数据在当机后存在于文件当中。这种模式可以在某些情况下提高速度。(在多数日志文件 系统中,这种模式是缺省设置。这种模式为ext2文件系统提供有限的数据完整性,更多的是为了避免系统启动时的长时间的文件系统校验)第二种模式 ,data = orderd(缺省模式),保持数据的可靠性与文件系统一致;这意味着在当机后,你不会在新近写入的文件中看到任何垃圾数据。第三种模式,data=journal,需要大一些的日志以保证在多数情况下获得适中的速度。在当机后需要恢复的时间也长一些。但是在某些数据库操作时速度会快一些。在通常情况下,建议使用缺省模式。如果需要改变模式,请在/etc/fstab文件中,为相应的文件系统加上data=模式的选项。详情可参看mount命令的man page在线手册(执行man mount)。
易于迁移
你可以不重新格式化硬盘,并且很方便的从ext2迁移至ext3而享受可靠的日志文件系统的好处。对,不需要做长时间的、枯燥的、有可能失误的“备份-重新格式化-恢复”操作,就可以体验ext3的优点。有两种迁移的方法:
如果你升级你的系统,Red Hat Linux安装程序会协助迁移。需要你做的工作 就是为每一个文件系统按一下选择按钮。
使用tune2fs程序可以为现存的ext2文件系统增加日志功能。如果文件系统在转换的过程已经被装载了(mount),那么在root目录下会出现文 件”.journal”;如果文件系统没有被装载,那么文件系统中不会出现该文件。转换文件系统,只需要运行tune2fs –j /dev/hda1(或者你要转换的文件系统所在的任何设备名称),同时把文件/etc/fstab中的ext2修改为ext3。如果你要转换自己的根文 件系统,你必须使用initrd引导启动。参照mkinitrd的手册描述运行程序,同时确认自己的LILO或GRUB配置中装载了initrd(如果没有成功,系统仍然能启动,但是根文件系统会以ext2形式装载,而不是ext3,你可以使用命令cat /proc/mounts 来确认这一点。)详情可参看tune2fs命令的man page在线手册(执行man tune2fs)。
3、ext3的三种日志模式
ext3提供多种日志模式,即无论改变文件系统的元数据,还是改变文件系统的数据(包括文件自身的改变),ext3 文件系统均可支持,以下是在/etc/fstab文件引导时激活的三种不同日志模式:
data=journal日志模式
日志中记录包括所有改变文件系统的数据和元数据。它是三种ext3日志模式中最慢的,但它将发生错误的可能性降至最小。使用“data=journal”模式要求ext3将每个变化写入文件系统2次、写入日志1次,这将降低文件系统的总性能。所有新数据首先被写入日志,然后才被定位。意外发生过后,日志可以被重放,将数据与元数据带回一致状态。由于记录了在ext3中元数据和数据更新情况,当一个系统重新启动的时候,这些日志将起作用。
data=ordered日志模式 (默认)
仅记录改变文件系统的元数据,且溢出文件数据要补充到磁盘中。这是缺省的ext3日志模式。这种模式降低了在写入文件系统和写入日志之间的冗余,因此速度较快,虽然文件数据的变化情况并不被记录在日志中,但它们必须做,而且由ext3的daemon程序在与之相关的文件系统元数据变化前执行,即在记录元数据前要修改文件系统数据,这将稍微降低系统的性能(速度),然而可确保文件系统中的文件数据与相应文件系统的元数据同步。
data=writeback日志模式
仅记录改变文件系统的元数据,但根据标准文件系统,写程序仍要将文件数据的变化记录在磁盘上,以保持文件系统一致性。这是速度最快的ext3日志模式。因为它只记录元数据的变化,而不需等待与文件数据相关的更新如文件大小、目录信息等情况,对文件数据的更新与记录元数据变化可以不同步,即ext3是支持异步的日志。缺陷是当系统关闭时,更新的数据因不能被写入磁盘而出现矛盾,这一点目前尚不能很好解决。
不同日志模式间有差别,但设置的方法一样方便。可以使用ext3文件系统指定日志模式,由/etc/fstab启动时完成。例如,选择data=writeback日志模式,可以做如下设置:
/dev/hda5 /opt ext3 data=writeback 1 0
在一般情况下,data=ordered日志模式是ext3文件系统的缺省模式。
要指定日志方式,可以使用如下方式:
1 向/etc/fstab的选项字段添加适当的字符串例如 data=journal
# /dev/sda3 /var ext3 defaults,data=writeback 1 2
2 在调用 mount 时直接指定 -o data=journal 命令行选项。
# mount -o data=journal /dev/sdb1 /mnt
如果我们想要查看某一个文件系统的日志方式应该怎么查询,这里可以通过dmesg 命令:
# dmesg | grep -B 1 "mounted filesystem"
kjournald starting. Commit interval 5 seconds
EXT3-fs: mounted filesystem with ordered data mode.
--
EXT3 FS on sda1, internal journal
EXT3-fs: mounted filesystem with ordered data mode.
--
EXT3 FS on sdb1, internal journal
EXT3-fs: mounted filesystem with journal data mode.
--
EXT3 FS on sdb1, internal journal
EXT3-fs: mounted filesystem with writeback data mode.
4、选择日志模式
速度
在一些典型的情况下,使用选项data=writeback可以显著地提高速度,但是同时会降低对数据一致性的保护。在这些情况下,数据一致性的保护基本上与ext2文件系统相同,不同的是在正常操作时,系统不断地维护文件系统的完整性(这是其它日志文件系统使用的日志模式)。这包括频繁的共享写操作,还包括频繁地创建和删除大量的小文件,例如发送大量的小电子邮件信息。如果你从ext2切换到ext3,发现应用程序性能大幅度下降,选项data=writeback可能会对你提高性能有帮助。即使你没有获得昂贵的数据一致性保护措施,你仍然可以享受ext3的好处(文件系统总是保持一致)。Red Hat还在做工作,以提高ext3某些方面的性能,所以ext3的某些方面性能在将来可以获得改善。这也意味着即使你现在选择了data=writeback,你也需要以data=journal的缺省值重新测试将来的版本,来确定新版本的改变是否与自己的工作有关。
数据完整性
在大多数情况下,用户都是在文件的末尾写入数据。仅仅在某些情况下(例如数据库),用户在现存文件的中间写入数据。甚至覆盖现存文件的操作,是通过先截断该文件,然后再从文件末尾写入数据来实现的。在data=ordered模式中,如果正在写文件时系统崩溃,那么数据块可能被部分改写,但是写入过程并没有完成,所以系统存在不属于任何文件的不完整数据块。在data=ordered模式中,崩溃后残存无序数据块的唯一情况是在崩溃过程中一个程序正在重写某个文件。在这种情况下,无法绝对保证写入顺序,除非该程序使用了fsync()和O_SYNC强制写操作按特定顺序进行。
ext3文件系统还涉及到如何cache中的数据刷到硬盘上。它是通过kupdate进程来实现定期刷的,默认是5秒检查一次,将超过30秒的脏数据刷到硬盘。
在as 3.0中可以通过修改/proc/sys/vm/bdflush来达到目的。而在as 4.0中可以通过修改/proc/sys/vm/dirty_writeback_centisecs和/proc/sys/vm/dirty_expire_centisecs来达到目的。
由于默认是ordered模式,在这种模式下面,如果一个IO先写数据文件,然后再写日志文件。假如说在写完数据文件之后,写日志文件之前时,系统发生crashed,则这部分数据将会丢失,这在数据库是绝对不允许的,不管是Oracle还是MySQL。所以对数据库的写来说,每一次写操作都会先写到pagecache中,然后通知kernelthread 将这个buffers刷到硬盘,然后再将元数据写日志,最后才返回写成功的操作。这样对数据库来说写操作是明显不如写祼设备快。
所以说在采用Ext3跑数据库的情况下,将日志模式设为journal模式,性能反而应该会有所提升(没有测试过,理论上分析应该 是这样)。 因为在journal模式下数据库一个写操作,先是直接将数据和文件系统的变化写到日志中(绕开cache直接写,性能较好),然后将数据写到cache 中,接着由kupdate进程将数据刷新到硬盘上。 相比之下,对DB来讲,它的性能应该比前面一种要快。
另外这里还提一下MySQL中的sync_binlog这个参数。如果将这个参数设为1,也就是说每次写binlog文件将同时刷到硬盘上面去,就 像Oracle的写IO一样。如果将这个参数关闭,则它交给OS来管理,也就是每5秒检查一次,发现有30秒以前的老数据则刷到硬盘上。 innodb_flush_log_at_trx_commit参数来也涉及到刷硬盘的问题。
ext3作为ext2的增强版,和ext2使用的superblock、inode、group descriptor等数据结构几乎一模一样,所以ext3前向兼容ext2。在不用备份ext2文件系统数据的情况下,可以用:
1
# tune2fs –j/dev/sd1
在不用卸载分区的状态下直接将ext2文件系统转换成ext3文件系统。
假如说,我们在编辑文件时,突然停电了、或系统被锁定被迫得重启,会出现什么后果?轻则文件丢失部分内容,重则整个文件内容混乱,更有甚者文件系统直接崩溃。这将会是多么可怕的一件事儿。在linux正常关机时我们都会看到一条卸载文件系统的打印信息,而非正常关机会导致文件系统出现不一致,在系统重新启动阶段挂文件系统时会发现这种不一致,然后它便会尝试去修复它。不幸的是,随着存储设备容量的增大,这种修复工作所花费的时间越来越无法让人容忍。
Ext3的最大特性就是在ext2的基础上增加了日志功能,所以ext3文件系统也经常被人们称之为日志文件系统,但日志文件系统觉不仅仅只有ext3,还有诸如JFS、reiserFS和XFS,以及我们在Windows上经常见到的NTFS等。
Ext3的日志特性主要是依靠其下层一个名为“日志块设备层”的中间设备来完成,叫做JBD(Journaling Block Device layer 简称JBD)。JBD并不是文件系统规范的一部分,它和ext3文件系统的规范是没有任何的关系的,而JBD正是文件系统事务处理功能的实现基础。简而言之,JBD 被设计成在任何块设备上实现日志的特殊目的(越说越抽象,事务是个啥玩意儿啊⊙﹏⊙….)
关于事务,有过数据库开发经验或者做数据运维的同学肯定不会陌生。这里咱不就结概念,也不拘泥学术定义,大家只要知道事务的主要作用就是为了保证操作的原子性。这句话如何理解?比如说,在金融系统中,要从账户A转账X元到账户B。这一业务必须要确保从A账户成功划出了X元,然后往B账户成功增加了X元。只有这两个操作同时成功才能任务是转账成功,任何一个操作失败该业务必须终止。假如从A账户转出X元成功,当往B账户写入时出现了错误,那么从A账户转出的X元必须被退还到A账户。更极端的情况是,此时A账户所在的数据由于种种原因又崩溃了,那么数据库的事务机制必须保证A账户的X元不会丢失。这就是数据库业务操作的原子性。在日志文件系统中这种对文件数据操作的原子性是由JBD来提供保证,Ext3 通过“钩子(hooking in)”JBD的API 来实现其日志记录的功能。JBD层本身虽然代码不多,但却是个相当复杂的软件部分,这里我们先不鸟它,以后有机会再陪它玩玩儿。
日志文件系统当然要记录日志,而日志也需要占存储空间。所以,日志文件系统就是在存储介质上开辟一个块特殊的区域专门用于存储日志信息:
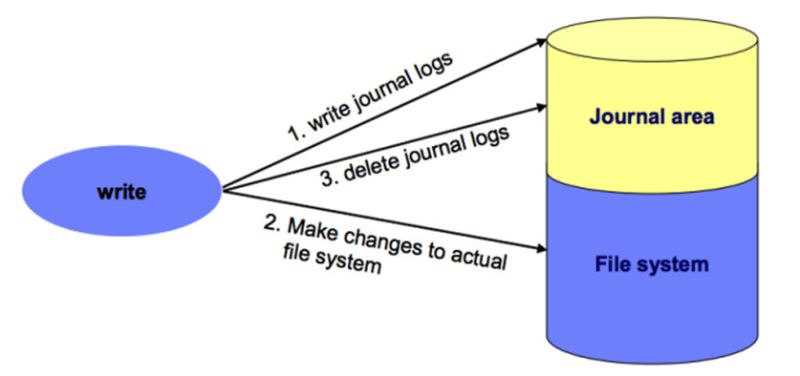
我们利用一幅图来简单描述ext3底层的layout:

加载全部内容