关于 Kafka 的一些面试题目
后端进阶 人气:3上周客串了一下面试官,在这里就简单记录一下期间我问到的一些关于 Kafka 的面试题目,这些都是我平时在学习 Kafka 的一些总结要点。
- 谈谈你对 kafka 的整体认识?
问这个问题主要是想知道面试者对 Kafka 的整体认识如何,能够大致了解清楚面试者对 Kafka 的相关概念的熟悉程度,比如消息、topic、partition、replica、offset、重平衡、leader/follower、ISR 等等。
- 谈谈 Kafka 吞吐量为何如此高?
多分区、batch send、kafka Reator 网络模型、pagecache、sendfile 零拷贝、数据压缩。
- 谈谈你对生产者储水池机制的理解
sender 线程工作机制、ByteBuffer 缓冲区的作用等等:

- 如何提高kafka吞吐量?
生产端调整 batch.size、linger.ms 参数,以及主题分区数合理分配等。
- 生产者producer是线程安全的吗?多线程实例还是单线程实例优缺点?
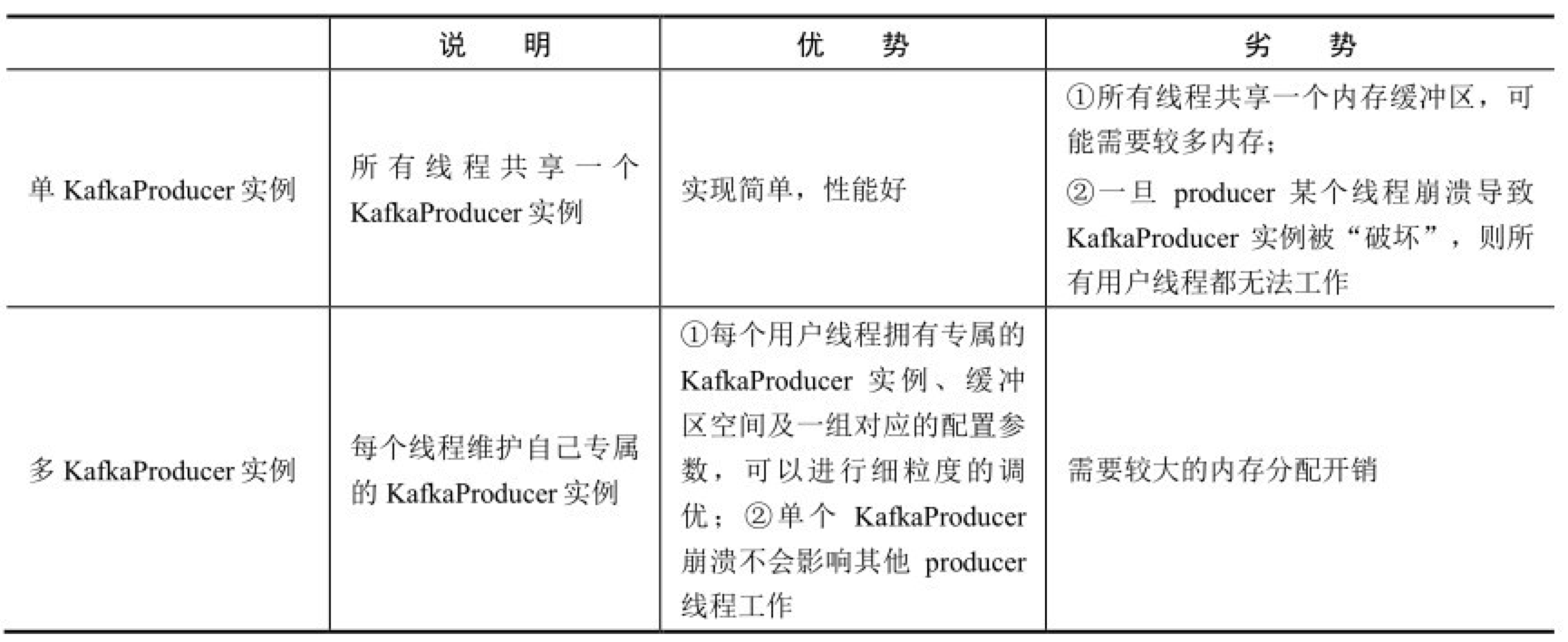
- 消费者 consumer 是线程安全的吗?多线程实例、单线程实例、单 consumer + 多 worker 线程的优缺点?
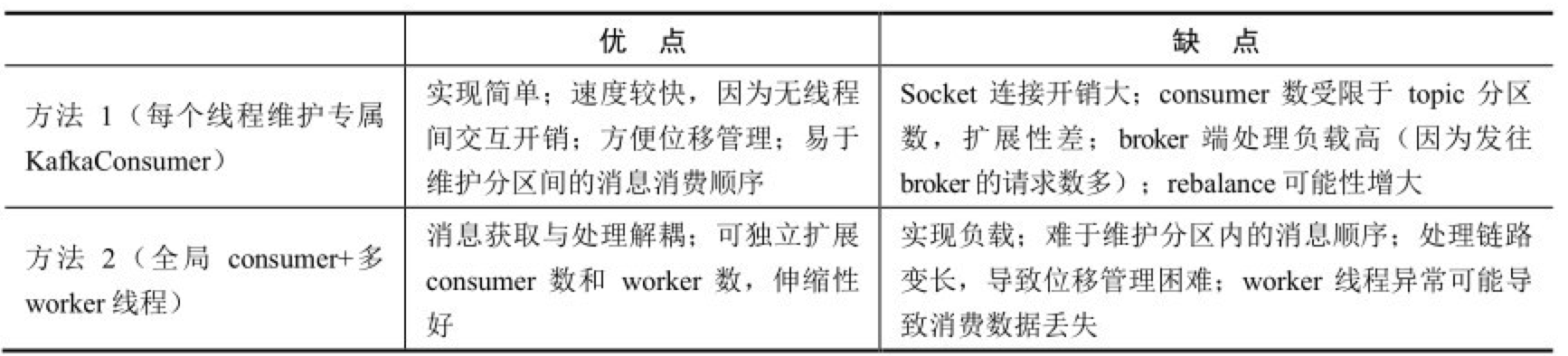
- 消息拉取时,什么情况下会造成消息重复消费?谈谈你对位移提交的理解?
理解消息交付语义:
最多一次(atmostonce):消息可能丢失也可能被处理,但最多只会被处理一次;
至少一次(atleastonce):消息不会丢失,但可能被处理多次;
精确一次(exactlyonce):消息被处理且只会被处理一次。
假若消费者在消费前提交位移,那么就是“最多一次”,若在消费后提交位移,那么就是“最少一次”,如果能够保证消费和提交位移同在一个事务中执行,就可保证“精确一次”。__consumer_offsets的一些理解。
- 什么时候会产生消费组重平衡以及重平衡会涉及到哪些相关参数、频繁重平衡会造成哪些后果?
消费组成员变更、主题数量变更、订阅信息变更;session.timeout.ms、max.poll.interval.ms、hearbeat.interval.ms;
相关文章:Kafka重平衡机制
- kafka默认不支持自动分区重分配,那么如果让你来执行分区重分配,有哪几个步骤,以及在重分配过程中kafka会有哪些动作?
RAR、OAR、AR、RAR-OAR、OAR-RAR 相关概念,
相关文章:记一次 Kafka 线上扩容、Kafka 分区重分配源码分析
- 谈谈你对 Preferred leader 选举的理解?
在 broker 挂掉之后,分区 leader 会变更,久而久之就会变得不均衡,Kafka 默认序号最小的副本为 Preferred leader,在 broker 重启回来后,Kafka 会重新调整分区的 Preferred leader 成为 leader,Preferred leader 选举分为手动选举和自动选举,涉及参数 auto.leader.rebalance.enable,还有个默认允许 10% 不均衡策略等等。
- 谈谈你对 ISR 副本同步的理解?ISR副本同步的缺陷有哪些?
相关文章:Kafka ISR 副本同步机制
- 谈谈你对水印备份机制的理解?LEO 更新机制、HW 更新机制?
相关文章:图解:Kafka 水印备份机制
- 水印备份机制的一些缺陷?数据丢失、数据离散?如何解决的(leader epoch)
相关文章:图解:Kafka 水印备份机制
- 谈谈你对 controller 机制的理解?controller 主要有哪些功能?
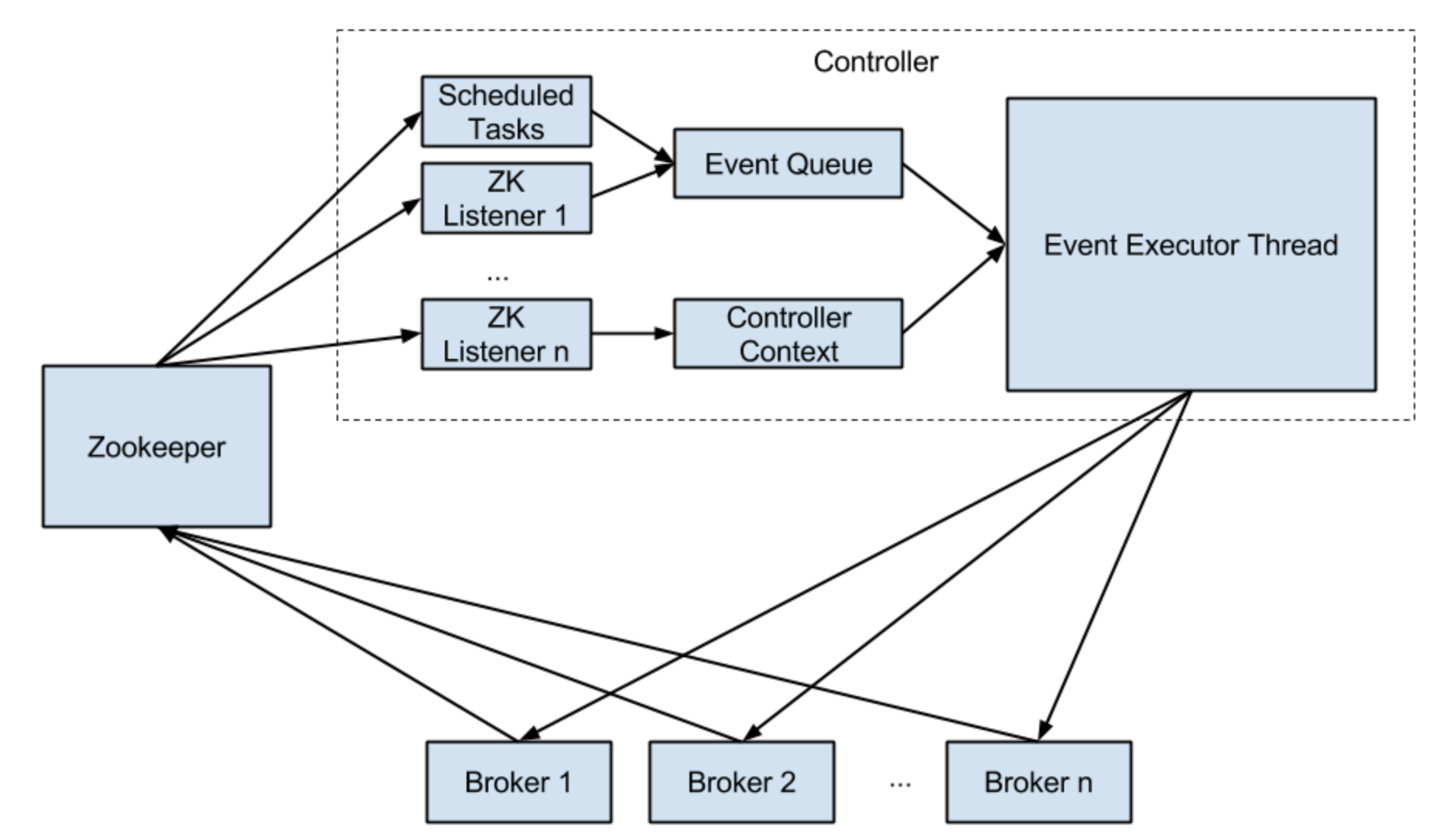
更新集群元数据信息、创建主题、删除主题、分区重分配、preferred leader 副本选举、主题分区扩展、broker 加入集群、broker 崩溃、受控关闭、controller leader 选举。
- Kafka 的日志存储机制?
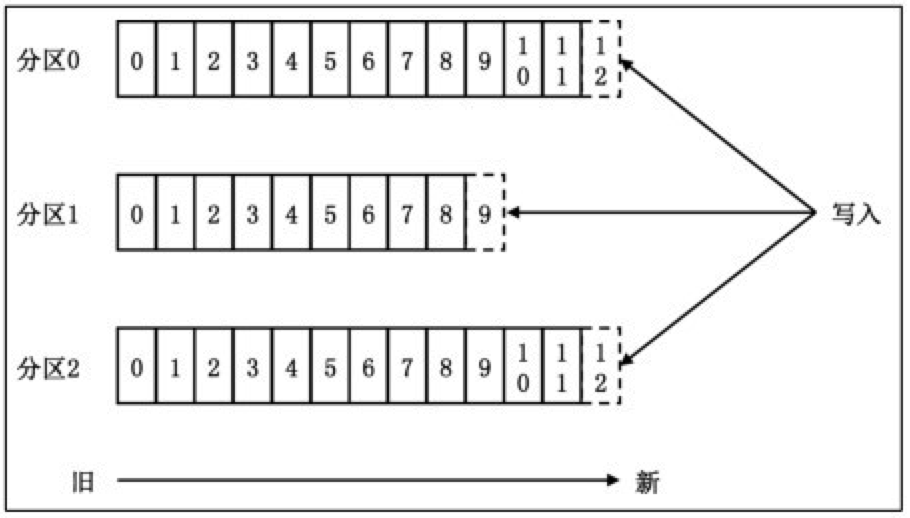
每个分区拥有单独的日志(partition log)、顺序写、到一定大小分成日志段文件(log segment file)、每个 log 文件对应一个索引文件(.index .timeindex)等等。
- Kafka 分区数越多性能就越好吗?为什么?
我的理解:
- 每个分区数都对应一个 log 文件,log 文件是顺序写的,但如果有非常多分区同时刷盘,就会变相成乱序写了,我猜想这也是为什么 RocketMQ 一个 broker 只会拥有一个 CommitLog 的原因之一吧;
- 客户端会为每个分区调用一条线程处理,多线程并发地处理分区消息,分区越多,意味着处理的线程数也就越多,到一定程度后,会造成线程切换开销大;
- 其中一个 broker 挂掉后,如果此时分区特别多,Kafka 分区 leader 重新选举的时间大大增加;
- 每个分区对应都有文件句柄,分区越多,系统文件句柄就越多;
客户端在会为每个分区分配一定的缓冲区,如果分区过多,分配的内存也越大。
更多精彩文章请关注作者维护的公众号「后端进阶」,这是一个专注后端相关技术的公众号。
关注公众号并回复「后端」免费领取后端相关电子书籍。
欢迎分享,转载请保留出处。

加载全部内容