AI Boot Camp 分享之 ML.NET 机器学习指南
张善友 人气:2
今天在中国七城联动,全球134场的AI BootCamp胜利落幕,广州由卢建晖老师组织,我参与分享了一个主题《ML.NET 机器学习指南和Azure Kinect .NET SDK概要》,活动虽然只有短短的2天时间的宣传,报名70人,到场40多人。

下面我和你分享一下我对ML.NET 机器学习的一些内容。
作为一个.NET开发者的你,可能很难立即进入机器学习。主要原因之一就是我们无法启动Visual Studio 使用我们所精通的.NET技术尝试这个新事物,这个领域被认为更适合该工作的编程语言,例如Python和R所占据,这个更准确的来说是机器学习的前期数据分析阶段。一年多以前,微软为我们的.NET技术带来一个新功能ML.NET, 现在已经是1.4,最新发布的.NET Core 3.1之上七龙珠已经聚齐。

首先我们为什么我们应该使用ML.NET 技术而不是Python和TensorFlow? 通常来说 除技术栈外,没有其他特殊原因。如果您将ASP.NET应用程序与机器学习模块一起使用,无疑是将ML.NET集成起来要容易得多。此外,现在您可以将使用TensorFlow构建的模块加载到ML.NET中。不知道各位有没有思考一下为什么 Microsoft 现在要在.NET 平台上引入机器学习以及我们为什么要关心机器学习。

首先是机器学习这项技术正在跨越鸿沟。事实上这个鸿沟是非常难以跨越的,之所以那么多的高科技产品只是在小众范围内流传,而并没有被主流市场接受,原因就是这些公司没有能够跨越这个鸿沟。成功跨越鸿沟的典型是小米手机,而被鸿沟挡住的典型当属锤子手机,大家可以想想这两家的区别,小米早期定义「为发烧而生」,而锤子手机则是「情怀」,都是针对某个特定群体,但是你看现在小米已经不再说发烧这类的词了,因为它早已经进入主流市场。
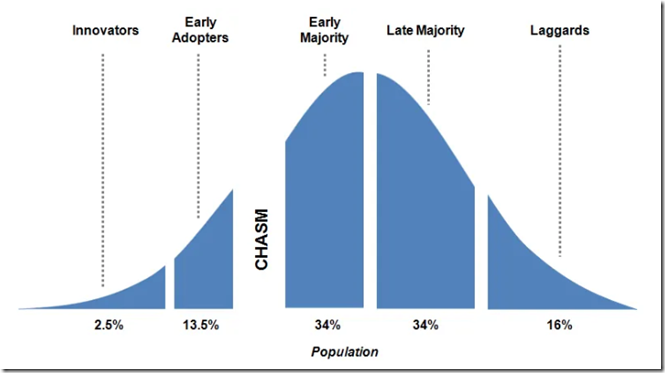
最早的机器学习算法可以追溯到20世纪初,到今天为止,已经过去了100多年。从1980年机器学习称为一个独立的方向开始算起,到现在也已经过去了近40年。在这100多年中,经过一代又一代人的努力,最近这几年终于跨越了鸿沟。 跨越鸿沟意味着机器学习正在从仅有少数人掌握的时代过渡到民主化、平民化。微软的CEO 萨提亚·纳德拉在他的书《刷新:重新发现商业与未来》 之中就有提出“民主化”的人工智能,ML.NET正是要完成这项使命的载体之一。如何实现人工智能全民化,让它惠及每个人?如何让每个人打造自己的人工智能和AI?在医疗、教育和零售机构当中,如何打造一个相适应的AI是至关重要的。当我们谈AI的时候,不能空谈任何一个AI公司,而是要“民主化”AI,让AI真正落地应用到个人。为了达到这样的一个目的,我们有一系列的解决方案。Azure 云上在AI领域的GPU和FPGA等等一些基础架构方面的合作都已准备就绪了,可以提供更多的可能性,确保业务的运行和效率。除此之外,我们的架构提供对TensorFlow的支持,这样一来我们就有了一个非常开放的环境来支持所有的开发框架。
您应该开始探索这个机器学习领域的另一个原因是,作为一个人类,我们会产生大量数据。单独地,我们无法处理那么多的数据,甚至无法处理全部数据。从技术上讲,我们面临着无法从数据中提取信息的问题。但是,机器学习模型却可以帮助我们处理海量的数据。
机器学习是计算机科学的一个分支,它使用统计技术使计算机能够学习如何解决某些问题而无需对其进行显式编程。如上所述,所有重要的机器学习概念都可以追溯到1950年代。但是,主要思想是开发一个数学模型,该模型将能够做出一些预测。通常会事先对一些数据进行训练。简而言之,数学模型使用对旧数据的见解对新数据进行预测。这整个过程称为预测建模。如果从数学上讲,我们正在尝试近似一个映射函数 – f 从输入变量 X 到输出变量 y。 我们正在尝试使用这种方法解决两大类问题:回归和分类。回归问题需要预测数量。这意味着我们的输出是连续的实值,通常是整数或浮点值。例如,我们要根据过去几个月的数据预测公司股票的价格。分类问题有点不同。他们正在尝试将输入划分为某些类别。这意味着此任务的输出是离散的。


ML.NET 是什么 给我们介绍了 ML.NET在几乎每种情况下都遵循相同的基本步骤。它结合了数据加载,转换和模型训练,使您轻松创建机器学习模型。
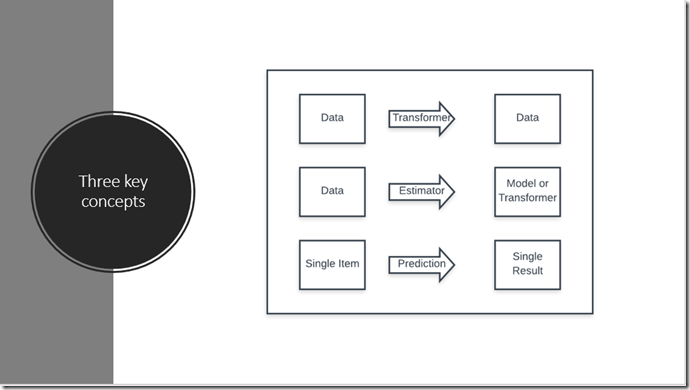
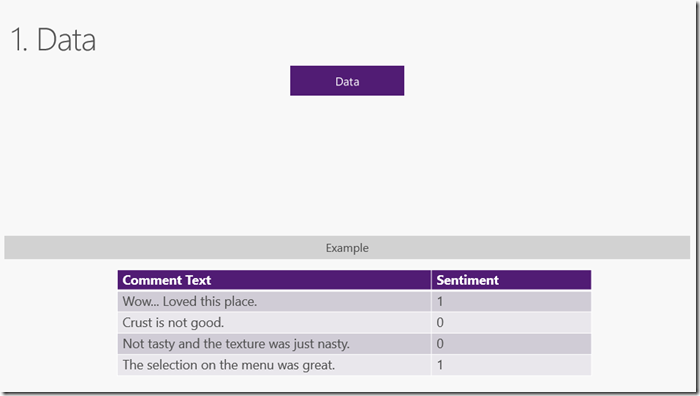
机器学习使用已知数据(例如训练数据)来找到模式,以便对新的未知数据进行预测。机器学习的输入称为 特征,这是用于进行预测的属性。机器学习的输出称为Label,它是实际的预测。 ML.NET中的数据表示为IDataView,这是一种描述表格数据(例如行和列)的灵活,高效的方法。IDataView对象可以包含数字,文本,布尔值,向量等。您可以将数据从文件或实时流源加载到IDataView。具体参考 从文件和其他源加载数据
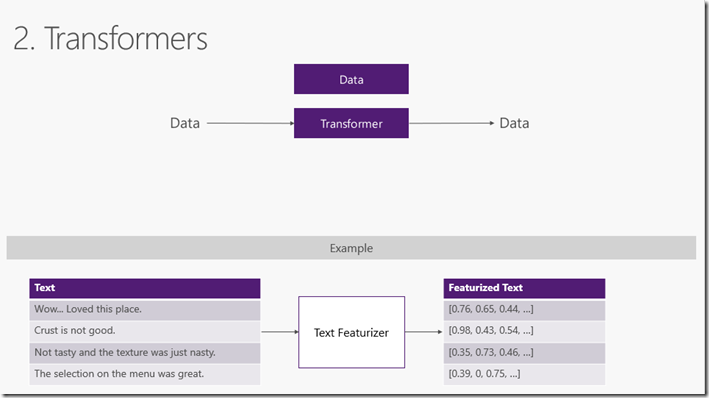
在大多数情况下,您可用的数据不适合直接用于训练机器学习模型。原始数据需要使用数据转换进行预处理。Transformers 获取数据,对其进行一些处理,然后返回经过转换的新数据。ML.NET内置了一组数据转换,用于替换缺失值,数据转换,使文本特征化等等。参考准备建模的数据
Estimator从数据中学习以创建Transformer 。现在,将输入要素转换为输出预测的模型是Transformer

ML.NET 基础知识
概述
- 什么是 ML.NET?
VIDEO
- 机器学习基础知识
概念
- 机器学习任务和算法
- 如何选择算法
10 分钟入门
快速入门
- 在 Visual Studio 中设置模型生成器
- ML.NET API 入门
- 在 Mac OS、Windows 或 Linux 上安装 CLI
教程
- 分析网站评论情绪(模型生成器)
- 预测价格(模型生成器)
- 对卫生违规行为分类(模型生成器和 SQL Server)
- 对支持问题进行分类 (API)
- 使用图像分类 API (API) 分类图像
- 使用模型组合 (API) 分类图像
- 检测图像中的对象 (API)
- 检测产品销售中的异常 (API)
- 预测自行车租赁需求(API 和 SQL Server)
- 生成电影推荐系统 (API)
操作指南
- 从各种源加载数据
- 准备建模的数据
- 训练和评估模型
- 使用经过训练的模型进行预测
- 保存和加载经过训练的模型
- 重新训练模型
参考
- ML.NET API 引用
- ML.NET 示例
加载全部内容