手撕 JVM 垃圾收集日志
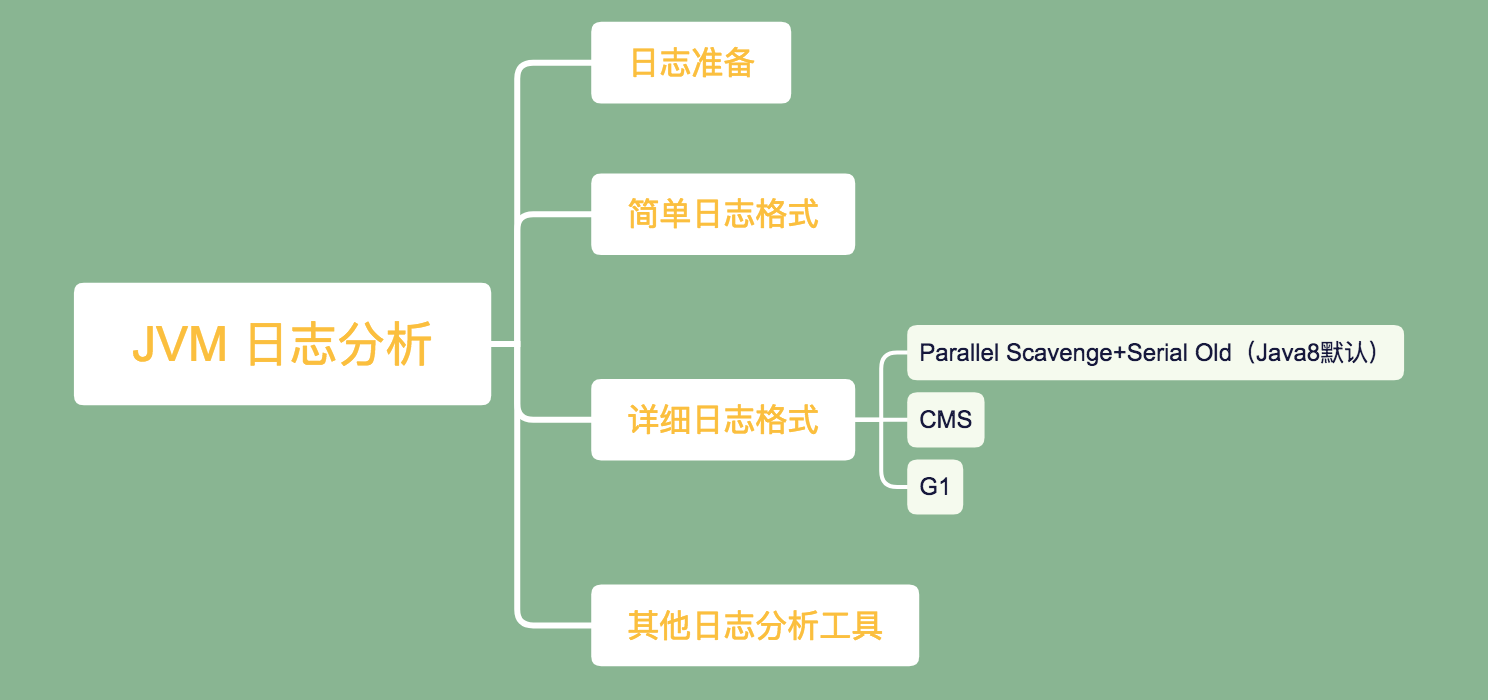
风的姿态 人气:1下图是本篇的写作大纲,将从以下四个方面介绍怎么样处理 JVM 日志。
有准备才能不慌
想要分析日志,首先你得有日志呀,对不对。凡是未雨绸蒙总是没错的。所谓有日志的意思,你要把 JVM 参数配置好,日志格式、日志存储位置等参数,当然了,除了日志相关参数外,其他的一些必要参数最好也配置上,比如 HeapDump 。
我相信大部分成熟的项目都会配置 JVM 参数。但是还是有一些小项目真的会忽略。以至于 JVM 崩溃的时候不方便查找问题原因而追悔莫及。比如下面这位同学(纯属虚构),虽然对话是虚构,但是是真的有不配置参数的。
要配置,有防备,不后悔;不配置,不准备,会追悔。
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/Users/fengzheng/jvmlog/gc.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/Users/fengzheng/jvmlog以上可以说是配置 JVM 日志以及 dump 现场最基本的配置了。这里只介绍关于日志的参数,其他的参数可以读一下 JVM 你不可不知的参数
加了以上配置的 JVM 就像是一台装有黑匣子的飞机。
一个重要概念
并发(Concurrent)和并行(Parallel)在 JVM 垃圾收集过程中的定义有很多同学搞不清楚。所以没次读到这两个概念的时候都一头雾水。
并发(Concurrent):指垃圾收集线程和用户线程可以同时进行。也就是说 JVM 在进行垃圾收集的时候,用户还是可以正常的使用应用系统提供的服务。(当然了,并没有一种完全并发的垃圾收集器,只是说在垃圾收集的大部分阶段是并发的)
并行(Parallel):指垃圾收集器是多线程工作的,比方说有4个线程同时进行垃圾收集的工作,但是在收集的过程中,用户线程是被挂起的。也就是在进行并行收集的时候,用户无法正常使用应用系统提供的服务。
分析背景
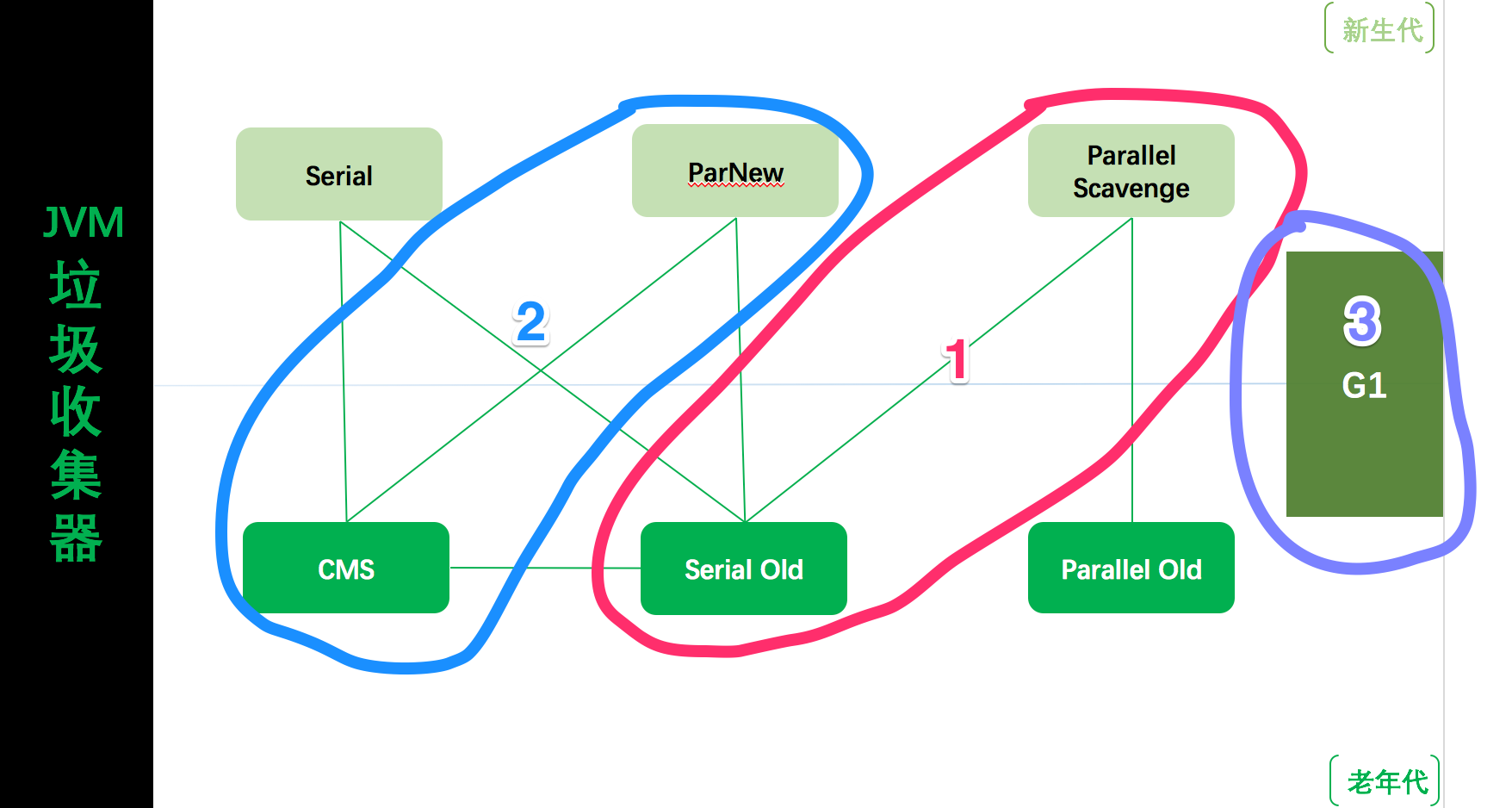
本篇的全部内容都基于 JDK 8 Hotspot JVM,分别从 ParallelGC 、CMS、G1 三种常用的垃圾收集器来分析。可以通过下图查看三种垃圾收集器的对应关系,分别对应图中标示的 1、2、3。
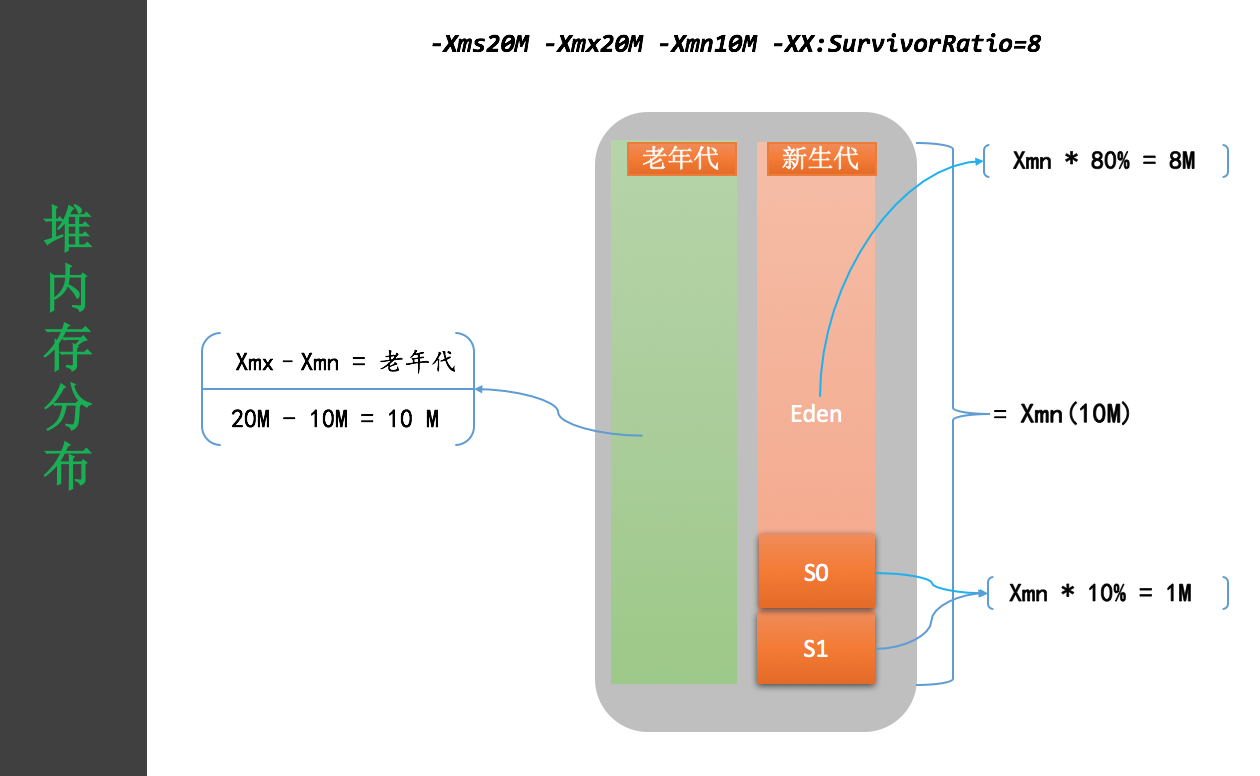
为了方便日志分析,我设置了一下简单的 JVM 作为基础参数,其中年轻代 10M,老年代 10M,堆大小 20M。
-Xms20M
-Xmx20M
-Xmn10M
-XX:SurvivorRatio=8
-XX:MetaspaceSize=6M
-XX:MaxMetaspaceSize=6M
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/Users/fengzheng/jvmlog简单日志格式
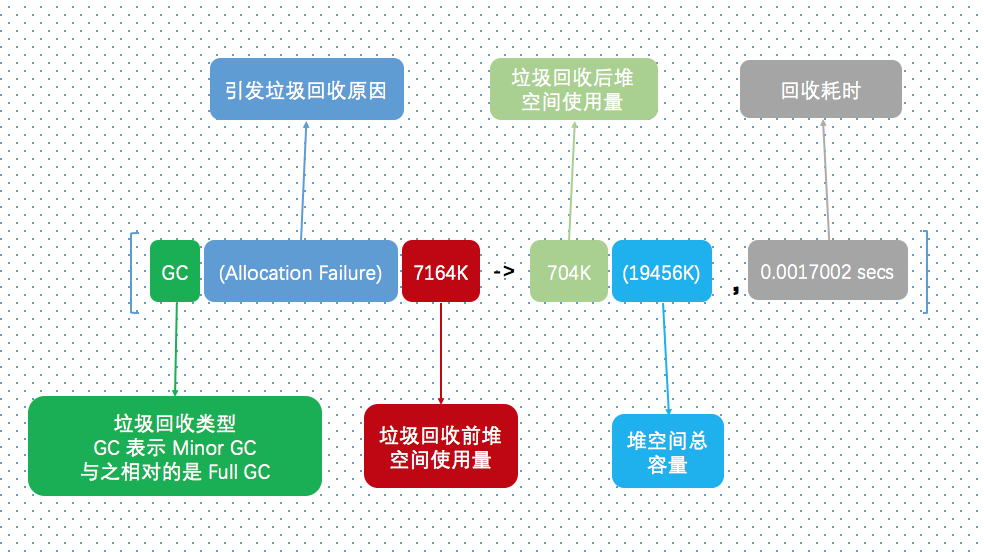
通过参数 -verbose:gc 或者 -XX:+PrintGC 可以让 JVM 开启简单日志格式,对于这几种垃圾收集期,简单日志的格式都是一致的。简单日志内容很少,只有GC类型(标示是 Minor GC 还是 Full GC)、GC 原因、堆收集前和收集后大小、堆的总大小以及收集耗时。
下面是简单日志配置下的几条收集日志,包括正常的空间分配失败引起的收集、System.gc() 触发的垃圾收集、以及执行 jmap -histo:live pid 命令执行的垃圾收集。
# Minor GC 新生代 GC
[GC (Allocation Failure) 7164K->704K(19456K), 0.0017002 secs]
# System.gc() 触发 Full GC
[GC (System.gc()) 4157K->648K(19456K), 0.0019522 secs]
[Full GC (System.gc()) 648K->609K(19456K), 0.0099904 secs]
# jmap -histo:live 触发 Full GC
[GC (Heap Inspection Initiated GC) 938K->737K(19456K), 0.0009119 secs]
[Full GC (Heap Inspection Initiated GC) 737K->573K(19456K), 0.0070892 secs]下图说明了一条简单格式的垃圾收集日志各个字段的含义。
在实际的生产环境中,只用简单格式的 JVM 日志意义不大,得到的有用信息不多,也就是知道垃圾收集次数、收集耗时以及堆的使用量,对于排查分析问题的帮助不是很大,所以,一般都会配置更加详细的日志格式。
详细日志格式
使用 -XX:+PrintGCDetails和-XX:+PrintGCDateStamps 这两个参数可以打印详细的垃圾收集日志和垃圾收集的时间戳。当然了,除了这两个之外,还有一些更具体的参数,比如收集前后打印堆使用信息的 -XX:+PrintHeapAtGC参数等等。
当然了,参数配置的越多,打印的信息越是详细,对于排查问题越有帮助,就是内容就会变得很多,肉眼看起来会比较抓狂。
Parallel Scavenge 收集器
在 JDK 8 中,如果不指定垃圾收集器,默认是使用参数 -XX:+UseParallelGC 的,也就是新生代使用 Parallel Scavenge,老年代配合使用的是 Serial Old。
Parallel Scavenge是一款并行的、高吞吐量的垃圾收集器,采用复制算法。适用于追求高效率的、对即时响应要求不高的系统。
要了解清楚 GC 日志各部分的含义,就要了解 JVM 内存模型以及垃圾收集器对于内存的规划和管理情况,老样子,还是通过图来看一下比较清楚。JDK 8 支持的除 G1 外的垃圾收集器,都适用此图,包括下面要介绍的 CMS。
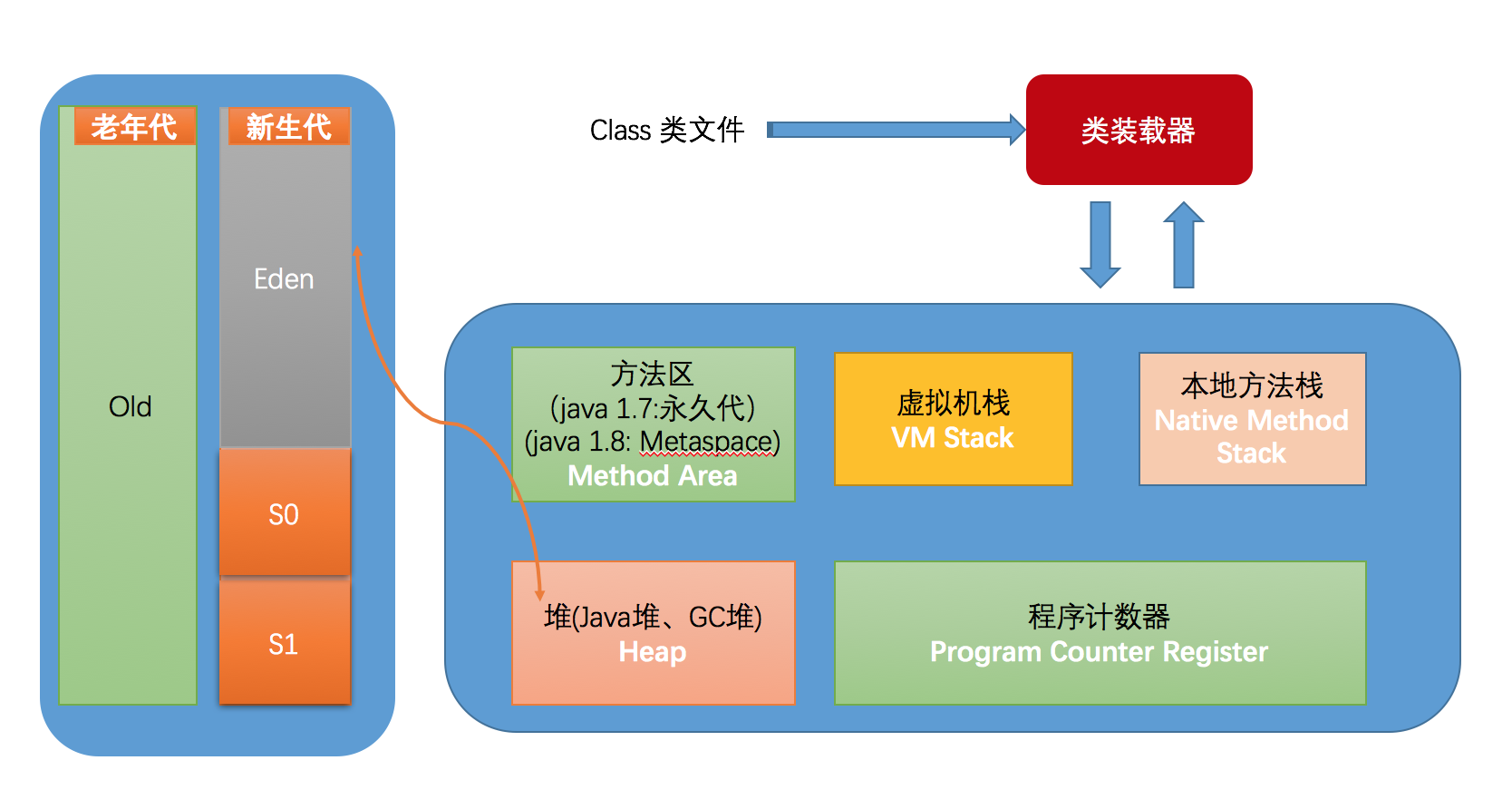
垃圾收集的部分即是上图中的「方法区」和 「堆」两部分。收集日志也基本上是描述这两部分的大小和变化情况。
在上面的背景介绍中给出了本次测试所用的参数。年轻代 10M ,老年代 10M,Metaspace 区 6M。下图是堆空间内存分布图,年轻代分为 Eden区和 S0、S1 两个区,SurvivorRatio为8,这也是默认值,表示新生代 Eden 占年轻代总大小的 80%,也就是 10*80%=8M,而 S0、S1 各占10%,也就是 1M。
好了,基于上面的基础认识。开始分析垃圾收集日志,以下是两条日志,第一条是一次 Minor GC,第二条是 Full GC。
2019-12-03T16:20:47.980-0800: [GC (System.gc()) [PSYoungGen: 4068K->656K(9216K)] 4076K->672K(19456K), 0.0016106 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2019-12-03T16:20:47.982-0800: [Full GC (System.gc())
[PSYoungGen: 656K->0K(9216K)],
[ParOldGen: 16K->570K(10240K)] 672K->570K(19456K),
[Metaspace: 3910K->3910K(1056768K)],
0.0110117 secs]
[Times: user=0.02 sys=0.00, real=0.01 secs] 为了更清楚的说明各个部分的含义,我居然又画了一张图(PS:画个图真是不容易),看一下各部分代表的含义。
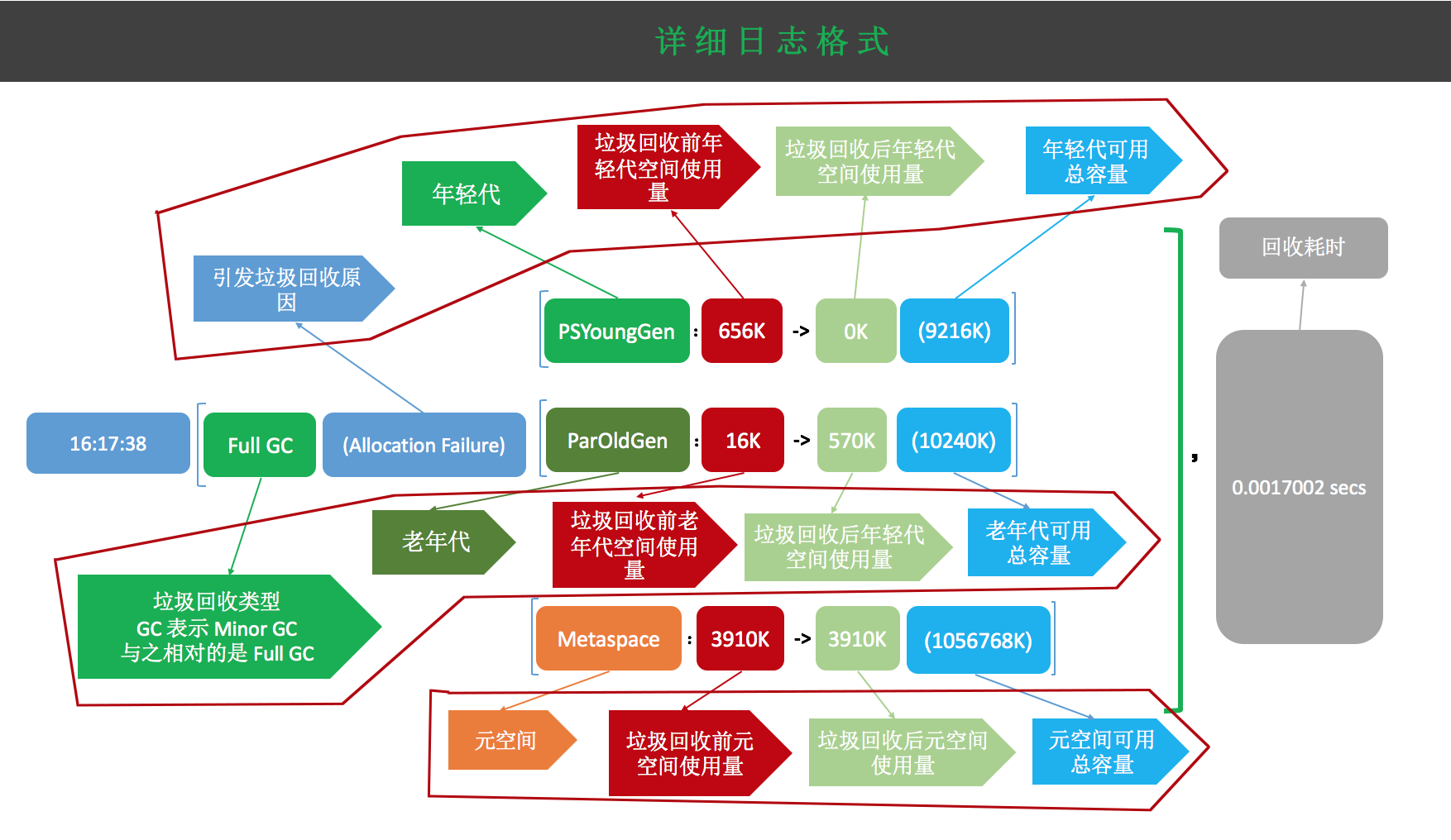
[^]: 红色线框描述各个部分的含义
上图标注的是一条 Full GC 日志,Full GC 同时收集了年轻代、老年代以及 metaspace 区。Full GC 日志包含了 Minor GC 的内容,那我们就直接分析 Full GC 了。
时间戳:日志以时间戳作为开端,表示此次垃圾收集发生的时间,由 -XX:+PrintGCDateStamps 参数决定是否开启。
收集内容主体:
沿着日志顺序往后看,Full GC (System.gc()),收集类型(是 Full GC 还是 Minor GC) ,括号里跟着发生此次垃圾收集的原因。
再后面是年轻代、老年代、Metaspace 区详细的收集情况。
[PSYoungGen: 656K->0K(9216K)],翻译为 「年轻代:年轻代收集前内存使用量->年轻代垃圾收集后内存使用量(年轻代可用内存总大小)」,垃圾收集前年轻代已使用 656K,垃圾收集后已使用 0K,说明被回收了 656K,总可用大小为 9216K(9M)。诶,不对呀?怎么是 9M 呢,年轻代不是分了 10 M 吗。因为可用内存和总内存不能划等号,S0 和 S1 只能有一块被算进可用内存,所以可用内存为 Eden + S0/S1=9M。
[ParOldGen: 16K->570K(10240K)] 672K->570K(19456K),翻译为 「[老年代:老年代收集前内存使用量->老年代垃圾收集后内存使用量(老年代可用内存总大小)] 堆空间(包括年轻代和老年代)垃圾收集前内存使用量->堆空间垃圾收集后内存使用量(堆空间总可用大小)」。
垃圾收集前老年使用 16K,收集后呢,竟然变大了,确定没有看错吗。是的,没有。这是因为年轻代的对象有一些进入了老年代导致的。老年代 16K 变成了 570K,说明有 554K 是年轻代晋升而来的。而内存总大小由 672K 减少到了 570K,说明有102K的内存真正的被清理了。
[Metaspace: 3910K->3910K(1056768K)]翻译为元空间回收前大小为 3910K,回收后大小为3910K,总可用大小为 1056768K。我们不是设置的 6M 吗,怎么这么大,没起作用吗。实际上这个值是 **CompressedClassSpaceSize +(2*InitialBootClassLoaderMetaspaceSize) **的大小,我们只设置了 MaxMetaspaceSize ,并没有设置这两个参数。使用如下命令可以看到这两个值的默认大小
jinfo -flag CompressedClassSpaceSize 75867
-XX:CompressedClassSpaceSize=1073741824
jinfo -flag InitialBootClassLoaderMetaspaceSize 75867
-XX:InitialBootClassLoaderMetaspaceSize=4194304单位是 byte,CompressedClassSpaceSize 的值是 1048576K(其实就是1G,默认值),InitialBootClassLoaderMetaspaceSize的值是 4M,用上面的公式计算,正好是 1056768K(1032M)
耗时统计
[Times: user=0.02 sys=0.00, real=0.01 secs]
user=0.02 表示执行用户态代码的耗时,这里也就是 GC 线程消耗的 CPU 时间。如果是多线程收集器,这个值会高于 real 时间。
sys=0.00 表示执行内核态代码的耗时。
real=0.01 表示应用停顿时长,多线程垃圾收集情况下,此数值应该接近(user + sys) / GCThreads(收集线程数),即单核上的平均停顿时间。
CMS 收集器
CMS 是一款老年代垃圾收集器,年轻代使用 ParNew 与之配合使用。它是一款并发、低停顿的垃圾收集器。适用于要求低延迟、即时响应的应用系统。
CMS 规划的内存模型和上面 Parallel Scavenge 的是一致的,可以参考上面的内存分布图。
CMS 采用标记-清除算法,算法过程比较复杂,分为一下几个步骤:
初始标记(CMS initial mark),会导致 stop the world;
并发标记(CMS concurrent mark),与用户线程同时运行;
预清理(CMS-concurrent-preclean),与用户线程同时运行;
可被终止的预清理(CMS-concurrent-abortable-preclean) 与用户线程同时运行;
重新标记(CMS remark),会导致 stop the world;
并发清除(CMS concurrent sweep),与用户线程同时运行;
并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
只有初始标记和重新标记这两个步骤会导致 STW,但是这两个步骤耗时很短,其他步骤可以与用户线程同时运行,所以用户几乎感觉不到 JVM 停顿。
使用参数 -XX:+UseConcMarkSweepGC可启用 CMS 垃圾收集器。更详细的参数如下:
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
-XX:+CMSClassUnloadingEnabled
-XX:+ParallelRefProcEnabled
# 在重新标记之前对年轻代做一次minor GC
-XX:+CMSScavengeBeforeRemark使用了-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses或-XX:+ExplicitGCInvokesConcurrent参数,在进行 Full GC 的时候,比如执行 System.gc() 操作,会触发 CMS GC,以此来提高 GC 效率。
以下是启用 CMS 后摘的一段 GC 日志,由于内容过长,下面我就直接在日志上做注释了。
# System.gc() 触发一次 Full GC
# -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses 参数
# 导致Full GC 以 CMS GC 方式执行
# 先由 ParNew 收集器回收年轻代
2019-12-03T16:43:03.179-0800: [GC (System.gc()) 2019-12-03T16:43:03.179-0800: [ParNew: 3988K->267K(9216K), 0.0091869 secs] 3988K->919K(19456K), 0.0092257 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
# 初始标记阶段,标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象
# 老年代当前使用 651K
# 老年代可用大小 10240K=10M
# 当前堆内存使用量 919K
# 当前堆可用内存 19456K=19M
# “1 CMS-initial-mark” 这里的 1 表示老生代
2019-12-03T16:43:03.189-0800: [GC (CMS Initial Mark) [1 CMS-initial-mark: 651K(10240K)] 919K(19456K), 0.0002156 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
# 并发标记开始
# 标记所有存活的对象,它会根据上个阶段找到的 GC Roots 遍历查找
2019-12-03T16:43:03.189-0800: [CMS-concurrent-mark-start]
# 并发标记阶段耗时统计
2019-12-03T16:43:03.190-0800: [CMS-concurrent-mark: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
# 并发预清理阶段开始
# 在上述并发标记过程中,一些对象的引用可能会发生变化,JVM 会将包含这个对象的区域(Card)标记为 Dirty
# 在此阶段,能够从 Dirty 对象到达的对象也会被标记,这个标记做完之后,dirty card 标记就会被清除了
2019-12-03T16:43:03.190-0800: [CMS-concurrent-preclean-start]
# 并发预清理耗时统计
2019-12-03T16:43:03.190-0800: [CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
# 重新标记阶段,目的是完成老年代中所有存活对象的标记
# 上一阶段是并发执行的,在执行过程中对象的引用关系还会发生变化,所以再次标记
# 因为配置了 -XX:+CMSScavengeBeforeRemark 参数,所以会在标记发生一次 Minor GC
# 进行一次Minor GC,完成后年轻代可用空间 267K,年轻代总大小9216K
2019-12-03T16:43:03.190-0800: [GC (CMS Final Remark) [YG occupancy: 267 K (9216 K)]
# 更详细的年轻代收集情况
2019-12-03T16:43:03.190-0800: [GC (CMS Final Remark) 2019-12-03T16:43:03.190-0800: [ParNew: 267K->103K(9216K), 0.0021800 secs] 919K->755K(19456K), 0.0022127 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
# 在程序暂停时重新进行扫描(Rescan),以完成存活对象的标记
2019-12-03T16:43:03.192-0800: [Rescan (parallel) , 0.0002866 secs]
# 第一子阶段:处理弱引用
2019-12-03T16:43:03.193-0800: [weak refs processing, 0.0015605 secs]
# 第二子阶段:卸载不适用的类
2019-12-03T16:43:03.194-0800: [class unloading, 0.0010847 secs]
# 第三子阶段:清理持有class级别 metadata 的符号表(symbol tables),以及内部化字符串对应的 string tables
# 完成后老年代使用量为651K(老年代总大小10240K=10M)
# 整个堆使用量 755K(总堆大小19456K=19M)
2019-12-03T16:43:03.195-0800: [scrub symbol table, 0.0015690 secs]
2019-12-03T16:43:03.197-0800: [scrub string table, 0.0003786 secs][1 CMS-remark: 651K(10240K)] 755K(19456K), 0.0075058 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
#开始并发清理 清除未被标记、不再使用的对象以释放内存空间
2019-12-03T16:43:03.198-0800: [CMS-concurrent-sweep-start]
#并发清理阶段耗时
2019-12-03T16:43:03.198-0800: [CMS-concurrent-sweep: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
# 开始并发重置,重置CMS算法相关的内部数据, 为下一次GC循环做准备
2019-12-03T16:43:03.198-0800: [CMS-concurrent-reset-start]
# 重置耗时
2019-12-03T16:43:03.199-0800: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
# 下面是执行 jmap -histo:live 命令触发的 Full GC
# GC 类型是 Full GC
# 触发原因是 Heap Inspection Initiated GC
# CMS收集老年代:从清理前的650K变为清理后的617K,总的老年代10M,耗时0.0048490秒
# 总堆使用大小由 1245K变为617K,总堆19M
# metaspace: 3912K变为3912K,
# metaspace 总大小显示为 CompressedClassSpaceSize +(2*InitialBootClassLoaderMetaspaceSize)
2019-12-03T16:43:20.115-0800: [Full GC (Heap Inspection Initiated GC) 2019-12-03T16:43:20.115-0800: [CMS: 650K->617K(10240K), 0.0048490 secs] 1245K->617K(19456K), [Metaspace: 3912K->3912K(1056768K)], 0.0049050 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] 以上就是对 CMS 垃圾收集器产生日志的分析,因为过程复杂,所以产生的日志内容也比较多。
G1 收集器
G1 收集器是在 JDK 7 版本中就已经正式推出,并且作为 JDK 9 默认的垃圾收集器。
Parallel Scavenge:我追求高吞吐量,现在社会什么最重要,效率呀,有没有。
CMS:效率固然重要,极致的用户体验才是王道啊,不能让用户等啊,不能等啊,低停顿、即时响应是我毕生追求。
G1(一脸不屑):有句话不只当讲不当讲,首先声明没有恶意,我想说,在座的各位都是垃圾。上面两位说的,我全都有,是的,全都有。 (ps:结果被打)
以上纯属开个玩笑,只是为了说明 G1 在满足了低停顿的同时也保证了高吞吐量,适用于多核处理器、大内存容量的服务端系统。
G1 是 CMS 的替代版本,具有如下特点:
- 横跨年轻代和老年代,不需要其他收集器配合;
- 并发收集器,可以与用户线程并发执行;
- 会压缩内存碎片;
- 可预测的停顿时间与高吞吐量;
与其他的垃圾收集器不同,G1 对堆内存做了不一样的规划,虽然还是使用分代策略,分为老年代、年轻代,年轻代又分为 Eden、Survivior 区,但是只是逻辑划分,物理上并不连续。它是将堆内存分为一系列大小在1M-32M 不等的 Region 区,通过下方的图可以直观的看出效果。
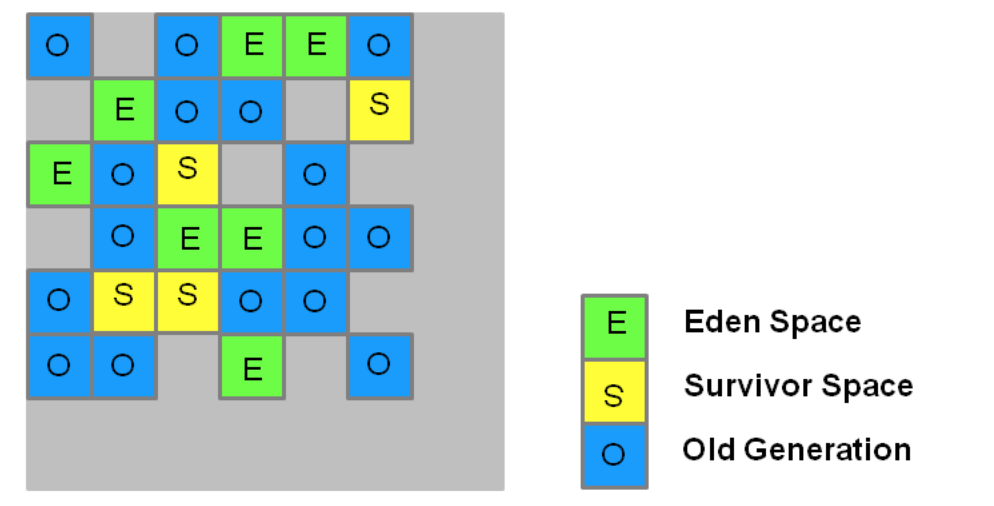
G1 垃圾收集包括年轻代收集和老年代收集两部分。
年轻代比较简单,收集器如果检测到存活区对象存活时间达到阈值,就会将这些存活对象转移到新的 Survivor 区或老年代,此过程会导致 stop the world。
老年代的收集就比较复杂了,包括如下几个阶段:
- 初始标记阶段(Initial Marking Phase),会导致 stop the wrold;
- 根区域扫描(Root Region Scan),与应用程序并发执行;
- 根区域扫描(Root Region Scan),与应用程序并发执行;
- 并发标记(Concurrent Marking),与应用程序并发执行;
- 最终标记(Remark),会导致 stop the wrold;
- 复制/清除(Copying/Cleanup),会导致 stop the wrold;
开启 G1 收集器的参数如下:
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100使用 G1 收集器时,一般不设置年轻代的大小。
以下是一次 G1 收集的日志,简单的分析直接写到下面的日志内了。
# 进行了一次年轻代 GC,耗时0.0008029S
[GC pause (G1 Humongous Allocation) (young), 0.0008029 secs]
# 4个GC线程并行执行
[Parallel Time: 0.5 ms, GC Workers: 4]
# GC 线程耗时统计,反应收集的稳定性和效率
[GC Worker Start (ms): Min: 90438.1, Avg: 90438.2, Max: 90438.4, Diff: 0.3]
# 扫描堆外内存耗时统计
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.2, Max: 0.2, Diff: 0.2, Sum: 0.6]
# 更新和扫描RSets 耗时统计
[Update RS (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Processed Buffers: Min: 0, Avg: 0.2, Max: 1, Diff: 1, Sum: 1]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
#扫描堆中的 root 对象耗时统计
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
# 拷贝存活对象耗时统计
[Object Copy (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
# GC 线程确保自身安全停止耗时统计
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.5]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
# GC的worker 线程的工作时间总计
[GC Worker Total (ms): Min: 0.1, Avg: 0.4, Max: 0.5, Diff: 0.3, Sum: 1.5]
# GC的worker 线程完成作业的时间统计
[GC Worker End (ms): Min: 90438.6, Avg: 90438.6, Max: 90438.6, Diff: 0.0]
# 修复GC期间code root指针改变的耗时
[Code Root Fixup: 0.0 ms]
# 清除code root耗时
[Code Root Purge: 0.0 ms]
# 清除card tables 中的dirty card的耗时
[Clear CT: 0.0 ms]
# 其他方面比如选择CSet、处理已用对象、引用入ReferenceQueues、释放CSet中的region等的耗时
[Other: 0.3 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.1 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.0 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
# 收集前 Eden区使用量 1024K(总容量9216K),收集后容量0B(总容量9216K)
# Survivors 区收集前后的大小
# 堆空间收集前使用量13.4M(总量20M),收集后650.2K
[Eden: 1024.0K(9216.0K)->0.0B(9216.0K) Survivors: 1024.0K->1024.0K Heap: 13.4M(20.0M)->650.2K(20.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
# 初始标记阶段,耗时0.0031800s
2019-12-03T16:48:25.456-0800: [GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0031800 secs][Parallel Time: 2.5 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 4115.2, Avg: 4115.4, Max: 4115.8, Diff: 0.6]
...
[Eden: 3072.0K(10.0M)->0.0B(9216.0K) Survivors: 0.0B->1024.0K Heap: 9216.0K(20.0M)->744.0K(20.0M)]
[Times: user=0.01 sys=0.00, real=0.00 secs]
# Root区扫描
2019-12-03T16:48:25.460-0800: [GC concurrent-root-region-scan-start]
2019-12-03T16:48:25.462-0800: [GC concurrent-root-region-scan-end, 0.0024198 secs]
# 并发标记
2019-12-03T16:48:25.462-0800: [GC concurrent-mark-start]
2019-12-03T16:48:25.462-0800: [GC concurrent-mark-end, 0.0001306 secs]
# 再次标记
2019-12-03T16:48:25.462-0800: [GC remark 2019-12-03T16:48:25.462-0800: [Finalize Marking, 0.0015922 secs] 2019-12-03T16:48:25.464-0800: [GC ref-proc, 0.0004899 secs] 2019-12-03T16:48:25.465-0800: [Unloading, 0.0016093 secs], 0.0040544 secs]
[Times: user=0.01 sys=0.00, real=0.00 secs]
# 清理工作
2019-12-03T16:48:25.467-0800: [GC cleanup 4000K->4000K(20M), 0.0003710 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs] 其他工具
大多数时候靠肉眼分析日志是很困难的,借助一些分析工具是必不可少的。
在线日志分析网站:https://gceasy.io/
在线 JVM 参数生成:https://opts.console.perfma.com/result/generate/JlKEV
【【【【【【【 写文不易,疯狂求推荐 】】】】】】
还可以读:
JVM 你不可不知的参数
无意中就做了个 web 版 JVM 监控端
JConsole、VisualVM 依赖的 JMX 技术
Java 调试工具、热部署、JVM 监控工具都用到了它
我们说的 JVM 内存是什么
分析 JVM 常用的 JDK 内置工具
欢迎关注,不定期更新本系列和其他文章
古时的风筝 ,进入公众号可以加入交流群

加载全部内容