Stack Overflow上59万浏览量的提问:为什么会发生ArrayIndexOutOfBoundsException?
沉默王二 人气:6在逛 Stack Overflow 的时候,发现了一些访问量像昆仑山一样高的问题,比如说这个:为什么会发生 ArrayIndexOutOfBoundsException?这样看似简单到不值得一问的问题,访问量足足有 69万+,这不得了啊!说明有不少的初级程序员被这个问题困扰过。实话实说吧,我也有点吃不准为什么。
来回顾一下提问者的问题:
ArrayIndexOutOfBoundsException究竟意味着什么?我该如何摆脱这个错误。
如果你也曾被这个问题困扰过,或者正在被困扰,就请随我一起来梳理一下问题的答案。打怪进阶喽!
来看这样一段代码,它就可以引起 ArrayIndexOutOfBoundsException。
String[] names = { "沉", "默", "王", "二" };
for (int i = 0; i <= names.length; i++) {
System.out.println(names[i]);
}错误的堆栈信息如下所示。
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 4
at com.cmower.java_demo.stackoverflow.Cmower1.main(Cmower1.java:7)抛出这个错误的原因是由于数组使用了非法的下标访问,比如说下标为负数或者大于或者等于数组的长度。
因为数组 names 的长度为 4,但下标的起始位置为 0,而不是 1,导致 names[4] 的时候越界了。这个问题的修正方法蛮简单的,就是把 <= 改为 <。
String[] names = { "沉", "默", "王", "二" };
for (int i = 0; i < names.length; i++) {
System.out.println(names[i]);
}当 i 为 4 的时候要跳出 for 循环,names 的最大下标值为 3 而不是 4。
Java 的下标都是从 0 开始编号的(我不确定有没有从 1 开始的编程语言),这和我们平常生活中从 1 开始编号的习惯不同。Java 这样做的原因如下:
Java 是基于 C 语言实现的,而 C 语言的下标是从 0 开始的——这听起来好像是一句废话。真正的原因是下标并不是下标,在指针(C)语言中,它实际上是一个偏移量,距离开始位置的一个偏移量。第一个元素在开头,因此它的偏移量就为 0。
此外,还有另外一种说法。早期的计算机资源比较匮乏,0 作为起始下标相比较于 1 作为起始下标,编译的效率更高。
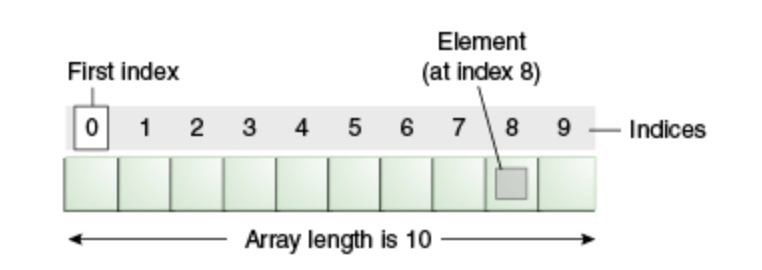
比如说,10 个元素的数组其结构如下图所示。编号从 0 开始,第 9 个元素将在下标 8 处访问。
为了摆脱 ArrayIndexOutOfBoundsException 的困扰,除了 i < 0; i < names.length;还有一种更值得推荐的做法——使用增强的 for 循环,当我们确定不需要使用下标的时候。
String[] names = { "沉", "默", "王", "二" };
for (String name : names) {
System.out.println(name);
}增强的 for 循环,彻底地甩掉了使用数组下标的可能性,也就彻底地摆脱了 ArrayIndexOutOfBoundsException。虽然这只是针对我们开发者来说。
实际上,Java 会把增强的 for 循环语句解释为普通的 for 循环语句,仍然会使用下标。
String[] names = new String[]{"沉", "默", "王", "二"};
String[] var2 = names;
int var3 = names.length;
for(int var4 = 0; var4 < var3; ++var4) {
String name = var2[var4];
System.out.println(name);
}下标 var4 的起始值为 0,var3 为数组的长度;当 var4 自增长为 4 的时候,发现 var4 不小于 var3,于是循环退出。
但不管怎么说,增强的 for 循环的确为我们开发者带来了福音——有效地摆脱了 ArrayIndexOutOfBoundsException。
来对比一下普通的 for 循环和反编译后的增强 for 循环,看看它们之间有什么区别。
for (int i = 0; i < names.length; i++) {
System.out.println(names[i]);
}
int var3 = names.length;
for(int var4 = 0; var4 < var3; ++var4) {
String name = var2[var4];
System.out.println(name);
}从性能的角度来看,差别主要有两点。
1)增强的 for 循环在遍历之前获取了数组的长度,并保存到了一个临时变量 var3 中,这就避免了每次循环的时候再去获取一次数组长度。
2)增强的 for 循环使用了前置自增 ++var4,而普通的 for 循环使用了后置自增 i++。这两者之间是有一定的差别的,感兴趣的同学可以了解一下。
如果使用的是 JDK8 以上的版本,我们还可以这样遍历数组(不使用下标)。
第一种:使用 List.forEach。
Arrays.asList(names).forEach(System.out::println);第二种:使用 Stream。
Stream.of(names).forEach(System.out::println);如果需要对数组执行其他操作,比如说过滤等操作,可以将数组转换为“流”。
这两种做法都需要用到 forEach() 方法,该方法其实是通过增强的 for 循环实现的,源码如下所示。
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (E e : a) {
action.accept(e);
}
}说到底,如果想要摆脱 ArrayIndexOutOfBoundsException 的困扰,使用增强的 for 循环来遍历数组就对了。把我们开发者容易疏忽的错误(比如 i <= names.length)交给智能化的编译器来处理,就是最好的办法。
好了各位读者朋友们,以上就是本文的全部内容了。能看到这里的都是人才,二哥必须要为你点个赞
加载全部内容
- 猜你喜欢
- 用户评论