使用图数据库 Nebula Graph 数据导入快速体验知识图谱 OwnThink
NebulaGraph 人气:2前言
本文由 Nebula Graph 实习生@王杰贡献。
最近 @Yener 开源了史上最大规模的中文知识图谱——OwnThink(链接:https://github.com/ownthink/KnowledgeGraphData ),数据量为 1.4 亿条。
本文介绍如何将这份数据快速导入图数据库 Nebula Graph,全过程大约需要 30 分钟。
中文知识图谱 OwnThink 简介
思知(OwnThink)
知识图谱是由 Google 在 2012 年提出来的一个概念。主要是用来描述真实世界中存在的各种实体和概念,以及他们之间的关系。在搜索引擎、问答机器人、知识抽取等多个领域有着诸多应用。
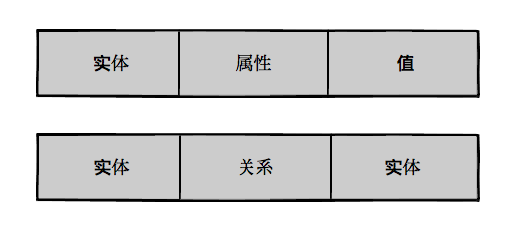
最近 Yener 开源了史上最大规模的中文知识图谱—— OwnThink(链接:https://github.com/ownthink/KnowledgeGraphData),数据量为 1.4 亿条。数据以 (实体, 属性, 值) 和 (实体, 关系, 实体) 混合的三元组形式存储,数据格式为 csv。
可以点击这里下载:https://nebula-graph.oss-accelerate.aliyuncs.com/ownthink/kg_v2.tar.gz
查看原始文件
由于 ownthink_v2.csv 数据过多,摘录部分数据为例:
红色食品,描述,红色食品是指食品为红色、橙红色或棕红色的食品。
红色食品,是否含防腐剂,否
红色食品,主要食用功效,预防感冒,缓解疲劳
红色食品,用途,增强表皮细胞再生和防止皮肤衰老
大龙湫,描述,雁荡山景区分散,东起羊角洞,西至锯板岭;南起筋竹溪,北至六坪山。
大龙湫,中文名称,大龙湫
大龙湫,外文名称,big dragon autrum
大龙湫,门票价格,50元
大龙湫,著名景点,芙蓉峰
姚明[中国篮球协会主席、中职联公司董事长],妻子,叶莉这里的 (红色食品,是否含防腐剂,否) 就是典型的 (实体, 属性, 值) 形式的三元组数据; 而 (姚明[中国篮球协会主席、中职联公司董事长],妻子,叶莉) 是典型的 (实体, 关系, 实体) 形式的三元组数据。
Step 1. 数据建模与清洗准备
建模
Nebula Graph 是一个开源的分布式图数据库(链接:https://github.com/vesoft-inc/nebula),相比 Neo4j 来说,它的主要特点是完全的分布式,因此图数据库 Nebula Graph 适合处理数据量超过单机的场景。
图数据库通常支持的数据模型为有向属性图(directed property graph)。图中的每个顶点(vertex)可以用标签(tag)来表示类型(Neo4j 叫做 Label),顶点和顶点之间的关系用边(edge)连接起来。每种 tag 和 edge 还可以带有属性。——然而,这些功能对于知识图谱的三元组数据没什么意义:
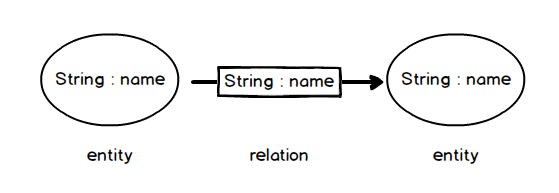
分析上图的三元组数据,发现无论是 (实体, 属性, 值) 形式的三元组数据,还是 (实体, 关系, 实体) 形式的三元组数据,每条三元组数据均可以建模成两个点和一条边的形式。前者三元组中的“实体”和“值”建模为两个点(起点、终点),“属性”建模为一条边,后者三元组中的两个“实体”也建模为两个点(起点、终点),“关系”建模为一条边.
而且,所有的点都是相同类型(取名叫entity ),只需要一个属性(叫 name ),所有的边也都是同一类型(取名叫 relation ),边上也只有一个属性(叫 name )。
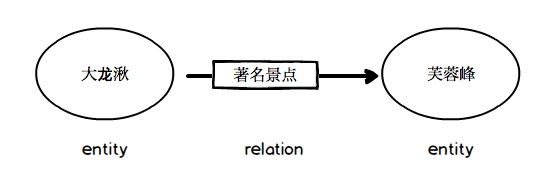
比如 (大龙湫,著名景点,芙蓉峰) 可以表示成下图这个样子:
数据清洗和预处理
按照前一节的分析,原始的每条三元组数据,还需要清洗转换为两个点和一条边才能变成属性图的模型。
下载清洗工具
本文测试的时候,使用的操作系统是 CentOS 7.5,工具由 Golang 语言编写而成。
你可以在这里 (链接:https://github.com/jievince/rdf-converter) 下载这个简单的清洗工具源代码并编译使用。
该工具会把转换后的顶点的数据写入到 vertex.csv 文件、边数据写入到 edge.csv 文件。
说明:在测试过程中,发现有大量的重复点数据,所以工具里面也做了去重。完全去重后的点的数据大概是 4600 万条,完全去重后的边的数据大概是 1 亿 4000 万条。
清洗完的 vertex.csv 文件长这样:
-2469395383949115281,过度包装
-5567206714840433083,Over Package
3836323934884101628,有的商品故意增加包装层数
1185893106173039861,很多采用实木、金属制品
3455734391170888430,非科学
9183164258636124946,教育
5258679239570815125,成熟市场
-8062106589304861485,"成熟市场是指低增长率,高占有率的市场。"说明:每一行是一个顶点,第一列整型 -2469395383949115281 是顶点的 ID(叫做 VID),它是由第二列文字通过 hash 计算出来的,例如 -2469395383949115281 就是由 std::hash("过度包装") 计算出来的值。
清洗完的 edge.csv 文件:
3413383836870836248,-948987595135324087,含义
3413383836870836248,8037179844375033188,定义
3413383836870836248,-2559124418148243756,标签
3413383836870836248,8108596883039039864,标签
2587975790775251569,-4666568475926279810,描述
2587975790775251569,2587975790775251569,中文名称
2587975790775251569,3771551033890875715,外文名称
2587975790775251569,2900555761857775043,地理位置
2587975790775251569,-1913521037799946160,占地面积
2587975790775251569,-1374607753051283066,开放时间说明:第一列是起点的 VID,第二列是终点的 VID,第三列是这条边的"属性"或者"描述"。
在本机完全去重的清洗程序运行时间大约是 6 分钟。
Step 2. Nebula Graph 启动准备
下载和安装
登陆 GitHub 后,在这里 (链接:https://github.com/vesoft-inc/nebula/actions) 找到 Nebula 的安装包。
找到你所用系统对应的下载链接:

笔者系统是 CentOS 7.5,下载 CentOS 7.5 最新的压缩包,解压后能找到 rpm 安装包 nebula-5ace754.el7-5.x86_64.rpm,注意 5ace754 是 git commit 号,使用时可能会有所不同。下载好后解压,输入下面命令进行安装,记得替换成新的 git commit:
$ rpm -ivh nebula-5ace754.el7-5.x86_64.rpm启动 Nebula Graph 服务
在 命令行 CLI 输入下面命令启动服务
$ /usr/local/nebula/scripts/nebula.service start all命令执行结果如下:

可以执行以下命令检查服务是否成功启动
$ /usr/local/nebula/scripts/nebula.service status all命令执行结果如下:

连接 Nebula Graph 服务
输入下面命令连接 Nebula Graph:
$ /usr/local/nebula/bin/nebula -u user -p password命令执行结果如下:

准备 schema 等元数据
Nebula Graph 的使用风格有点接近 MySQL,需要先准备各种元信息。
新建图空间 space
create space 的概念接近 MySQL 里面 create database。在 nebula console 里面输入下面这个命令。
nebula> CREATE SPACE test;进入 test space
nebula> USE test;创建点类型(entity)
nebula> CREATE TAG entity(name string);创建边类型 (relation)
nebula> CREATE EDGE relation(name string);最后简单确认下元数据是不是正确。
查看 entity 标签的属性:
nebula> DESCRIBE TAG entity;结果如下:

查看 relation 边类型的属性:
nebula> DESCRIBE EDGE relation;结果如下:

Step 3. 使用 nebula-importer 导入数据
登陆 GitHub 进入 https://github.com/vesoft-inc/nebula-importer ,nebula-importer 这个工具也是 Golang 语言写的,在这里下载并编译源代码。

另外,准备一个 YAML 配置文件,告诉这个 importer 工具去哪里找 csv 文件。(可直接复制下面这段)
version: v1rc1
description: example
clientSettings:
concurrency: 10 # number of graph clients
channelBufferSize: 128
space: test
connection:
user: user
password: password
address: 127.0.0.1:3699
logPath: ./err/test.log
files:
- path: ./vertex.csv
failDataPath: ./err/vertex.csv
batchSize: 100
type: csv
csv:
withHeader: false
withLabel: false
schema:
type: vertex
vertex:
tags:
- name: entity
props:
- name: name
type: string
- path: ./edge.csv
failDataPath: ./err/edge.csv
batchSize: 100
type: csv
csv:
withHeader: false
withLabel: false
schema:
type: edge
edge:
name: relation
withRanking: false
props:
- name: name
type: string说明:测试时候发现 csv 数据文件中有大量转义字符 (\) 和换行字符 (\r),nebula-importer 也做了处理。
最后:开始导入数据
加载全部内容
- 猜你喜欢
- 用户评论