如何打造一款m3u8视频爬虫
AntzUhl 人气:10.前言
m3u8是一种很常见的网页视频播放器的视频源,比如说中国大学MOOC中课程就是使用了该种视频格式。
随便打开一门课程,就可以发现在网络请求中存在一个m3u8的文件,在preview中预览,它并不像我们想象中是乱码的视频流。
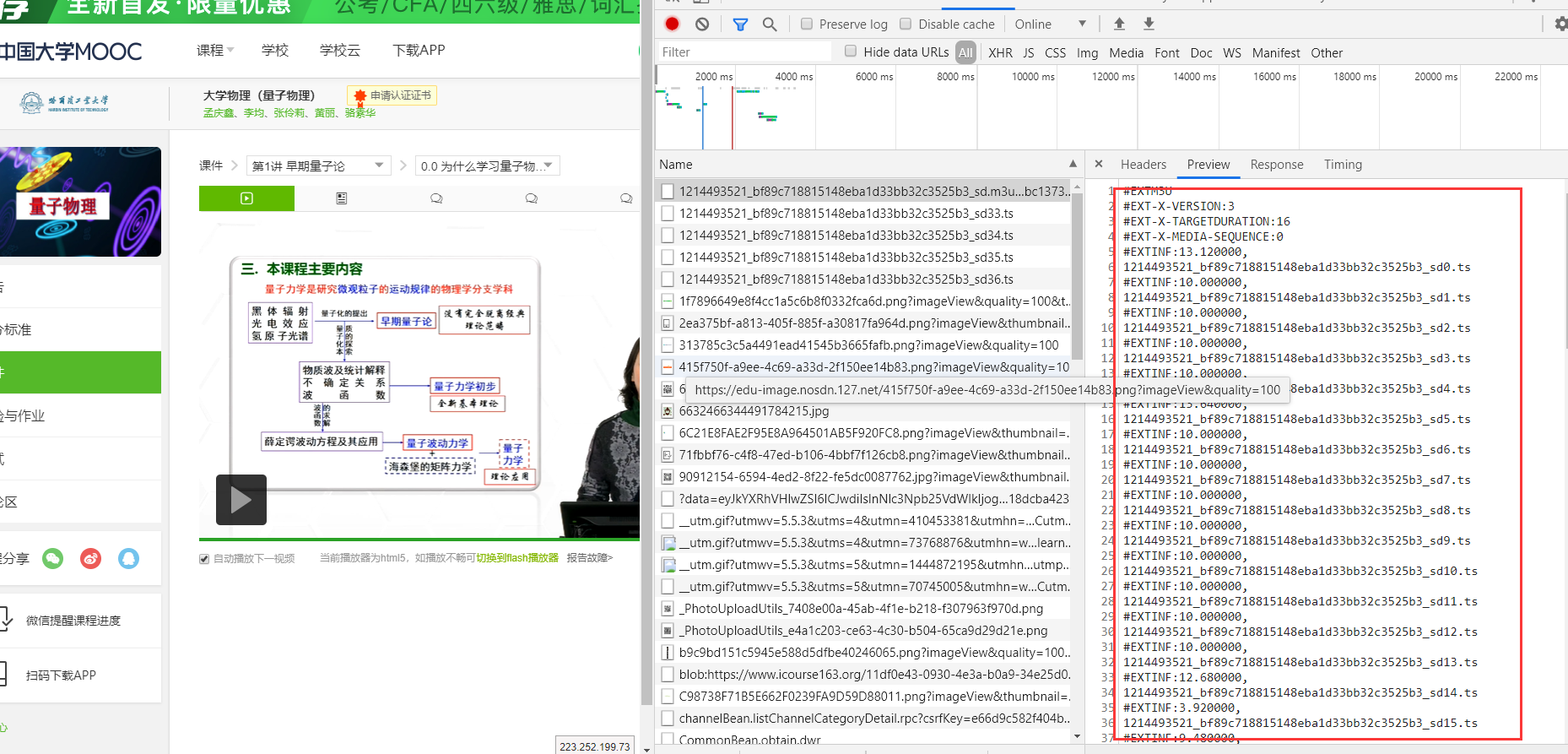
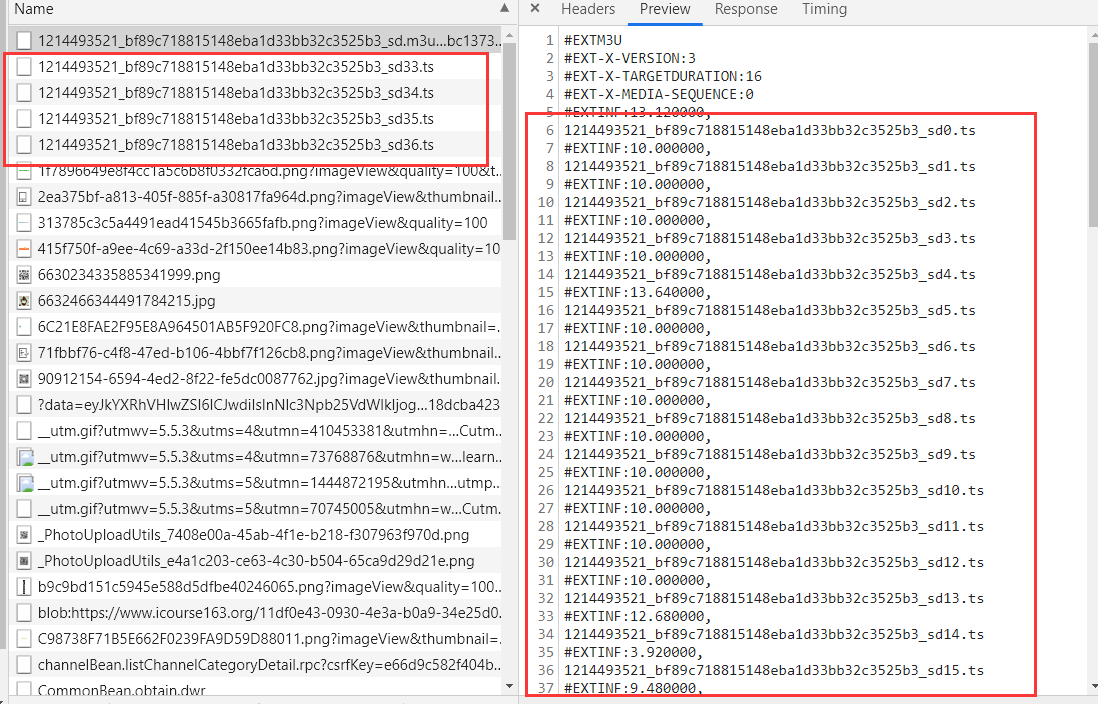
里面是一个列表,有一堆ts结尾的文件名,每个下面还跟了一个EXTINF的字段,好像是时间,在我们播放视频时,网络请求中会不断出现请求ts的内容。
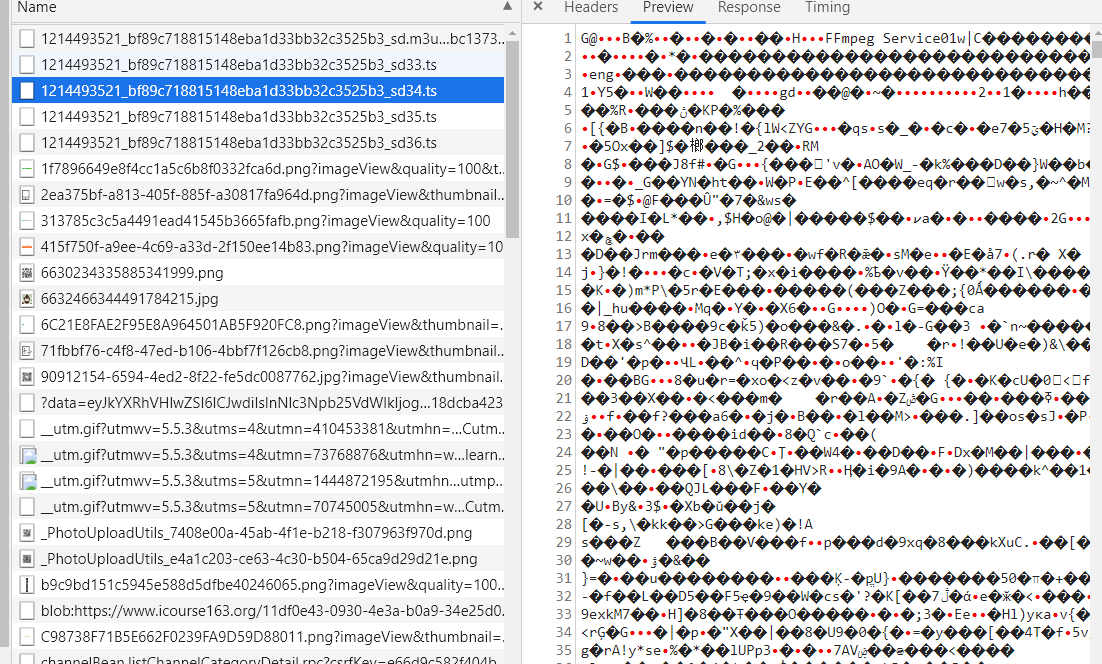
随便打开一个ts文件,它的内容却是如图视频流一般乱码的。
说到这里,你可能有猜测了,m3u8并不是视频流的文件,而有可能是组织ts文件的规范,EXTINF代表播放每多少秒去请求下一片ts流。
这种边看边加载的方法无疑可以减少我们的网络负荷。
要用爬虫爬取这类视频的方法也很简单,我们只需要获得m3u8文件,就可以得到视频的ts地址了,将所有ts请求下来之后进行合并,就可以得到视频文件了。
不过要提的一点是,很多视频网站会对他们的ts进行加密,我们下载下来合并之后可能视频能看,但是播放器放着放着就卡住了,然后之后黑屏画面。
1.编码部分
我们先根据m3u8来判断一下创建咋样一个代表M3U8视频对象的类。
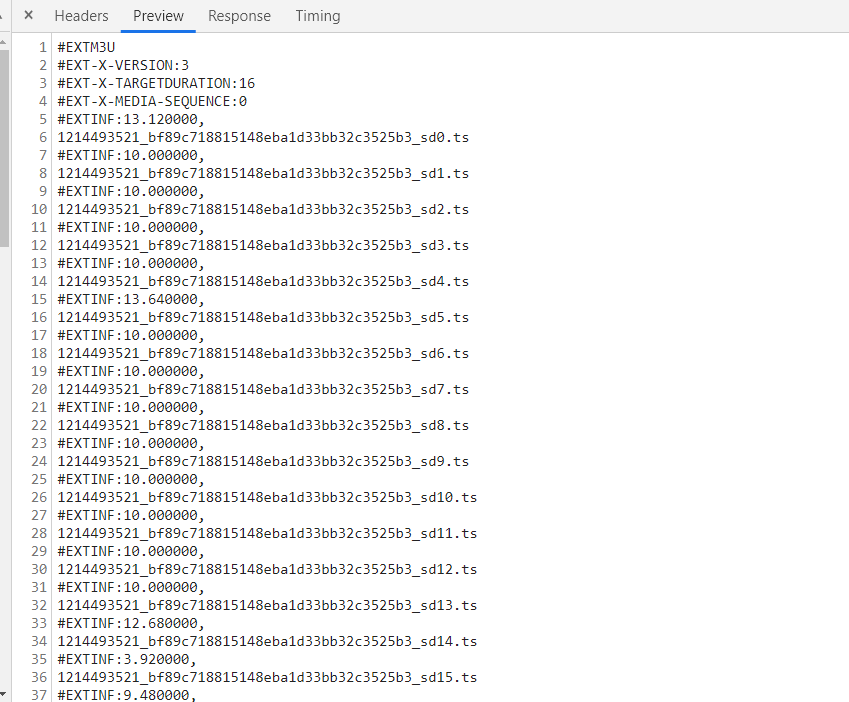
我们首先需要定义一个list,来存放这个m3u8视频下所有的ts文件,也就是后面说到的TS类。
这里提一点,m3u8里面的ts的路径一般对路径,会和m3u8在同一文件夹,我们代码中也是这么认为了,但是难免有些网站会单独存放m3u8和ts文件,如果遇到这种情况,修改一下代码即可。
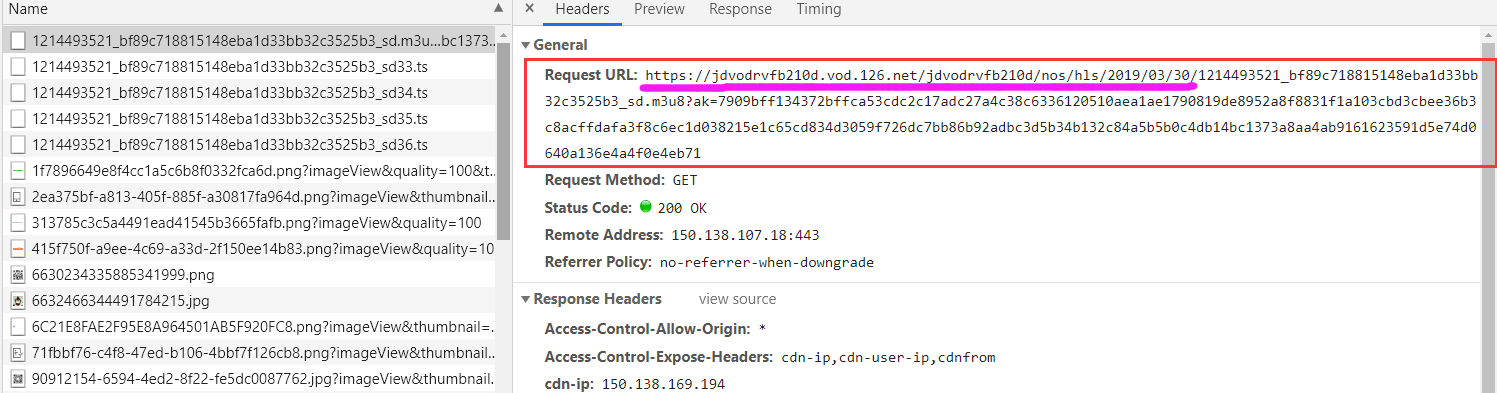
有了ts的名称,我们还需要URL的前缀,也就是图中紫色划线部分,也就是basepath。
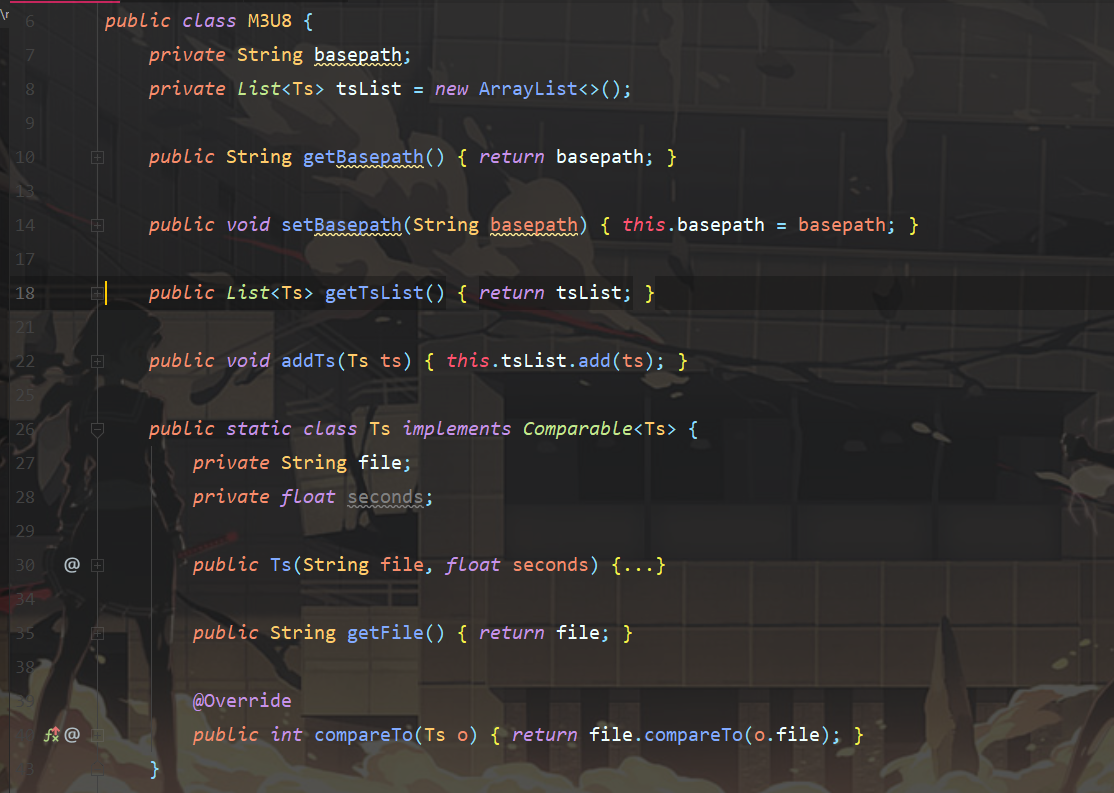
此外,我们还需要一个TS对象。
这个对象中存储TS文件名称以及时间EXTINF。
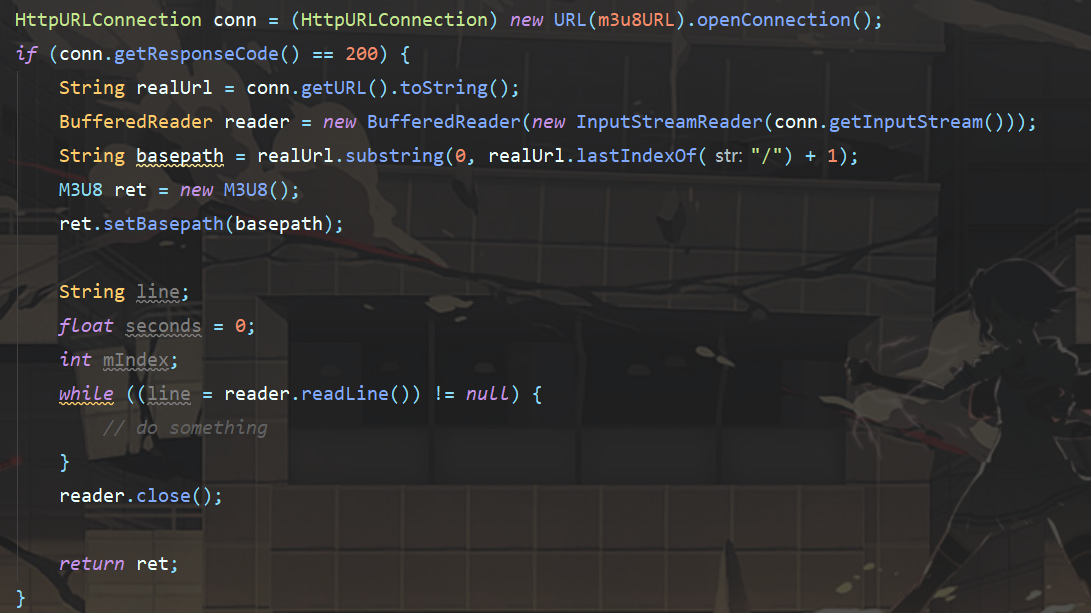
定义完实体类,就需要编写下载视频的过程了。
首先需要请求到m3u8的文件,此处使用Java的HttpURLConnection来请求获取,其它语言类似,只需要请求到文件即可。
请求到了m3u8的文本内容,我们还需要解析它 ,从中得到ts的名称。
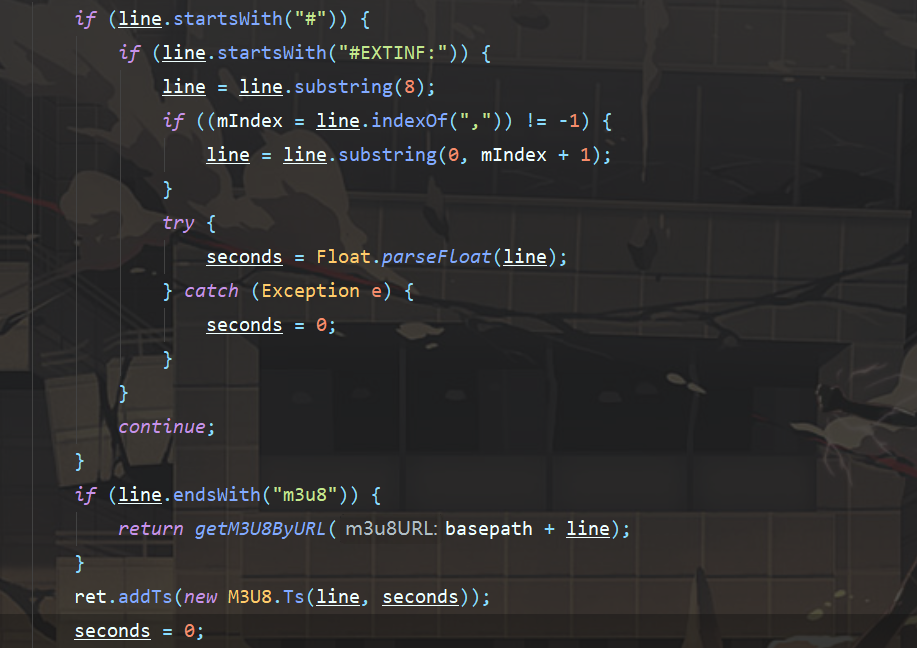
得到了M3U8视频对象之后,我们就可以遍历请求它的list中TS对象的名称属性来下载ts文件了。
这么多ts文件如果我们在单线程中遍历请求,会很耗费时间,Java给我们提供了Stream,其中parallel可以让我们并发去遍历集合,效率会提升不少。

依旧是使用HttpURLConnection来做请求,不过最好本次设置超时时间。
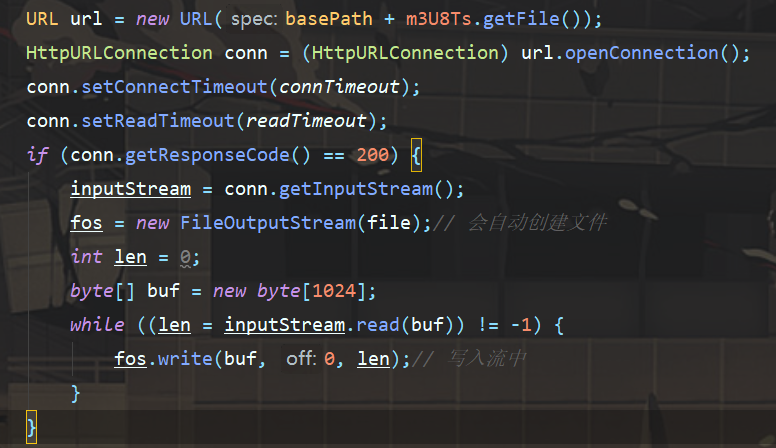
这样就可以请求到所有ts文件了。
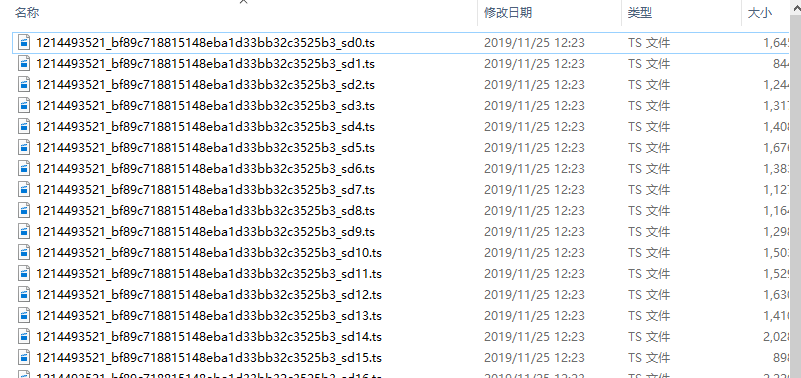
最后要做的就是合并这些ts文件成为一个MP4文件。
对于未加密的正常ts文件,我们只需要按照编号顺序直接拼接即可。
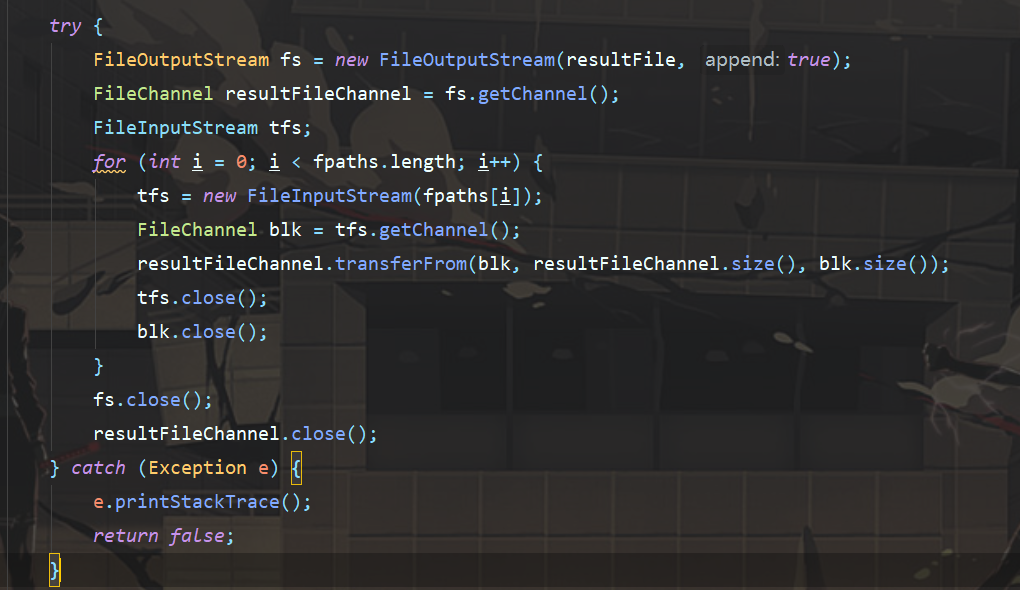
这样就算是完成了M3U8视频抓取了。
2.打包使用
下载地址:https://github.com/CasterWx/resources/releases/tag/1.0.1
在命令行中java -jar m3u8-down.jar [m3u8地址],会显示报错信息。
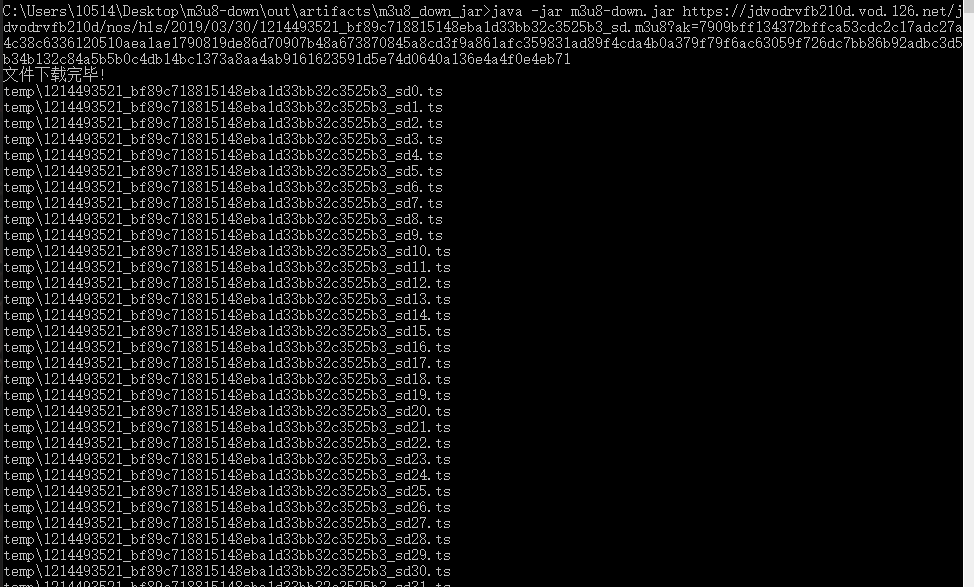
也可以直接m3u8-down.jar [m3u8地址],不会显示保存信息,会在后台执行。
最终会在同目录下生成一个output.mp4的文件,temp文件可以删除。

加载全部内容