【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!
计算机视觉联盟 人气:3文章目录
1 目标检测简介
2 lmdb数据制作
2.1 VOC数据制作
2.2 lmdb文件生成lmdb格式的数据是在使用caffe进行目标检测或分类时,使用的一种数据格式。这里我主要以目标检测为例讲解lmdb格式数据的制作。
1 目标检测简介
【1】目标检测主要有两个任务:
- 判断图像中对象的类别
- 类别的位置
【2】目标检测需要的数据:
- 训练所需的图像数据,可以是jpg、png等图片格式
- 图像数据对应的类别信息和类别框的位置信息。
2 lmdb数据制作
caffe一般使用lmdb格式的数据,在制作数据之前,我们需要对数据进行标注,可以使用labelImg对图像进行标注(https://github.com/tzutalin/labelImg),这里就不多赘述数据标注的问题。总之,我们得到了图像的标注Annotations数据。lmdb数据制作,首先需要将annotations数据和图像数据制作为VOC格式,然后将其生成LMDB文件即可。下边是详细的步骤:
2.1 VOC数据制作
这里我以caffe环境的Mobilenet+YOLOv3模型的代码为例(https://github.com/eric612/MobileNet-YOLO),进行lmdb数据制作,并且也假设你已经对其配置编译成功(如没成功,可以参考博文进行配置),所以我们的根目录为:caffe-Mobilenet-YOLO-master,下边为详细步骤:
【1】VOC格式目录建立:
VOC格式目录主要包含为:

其中,Annotations里存储的是xml标注信息,JPEGImages存储的是图片,ImageSets则是训练和测试的txt列表等信息,下边我们就要安装如上的目录进行建立我们自己的数据目录。
创建Annotations、JPEGImages、ImageSets/Main等文件,命令如下(也可直接界面操作哈):
注:建议新手按照我的名称,对于后续文件修改容易!!!
cd ~/ # 进入home目录
cd Documents/ # 进入Documents目录
cd caffe-Mobilenet-YOLO-master/ # 进入我们的根目录
cd data # 进入data目录内
mkdir VOCdevkit # 创建存储我们自己的数据的文件夹
cd VOCdevkit
mkdir MyDataSet # 创建存储voc的目录
cd MyDataSet
# 创建VOC格式目录
mkdir Annotations
mkdir JPEGImages
mkdir ImageSets
cd ImageSets
mkdir Main好啦,我们的文件夹就建立好了,如下图所示:
【2】将所有xml文件考入至Annotations文件夹内
【3】将所有图片考入至JPEGImages文件夹内
【4】划分训练接、验证集合测试集,如下为Python代码,需要修改的地方注释已标明:
import os
import random
# 标注文件的路径,需要你自己修改
xmlfilepath=r'/home/Documents/caffe-Mobilenet-YOLO-masterhttps://img.qb5200.com/download-x/data/VOCdevkit/MyDataSet/Annotations/'
# 这里是存储数据的本目录,需要改为你自己的目录
saveBasePath=r"/home/Documents/caffe-Mobilenet-YOLO-masterhttps://img.qb5200.com/download-x/data/VOCdevkit/"
trainval_percent=0.8 # 表示训练集和验证集所占比例,你需要自己修改,也可选择不修改
train_percent=0.8 # 表示训练集所占训练集验证集的比例,你需要自己修改,也可选择不修改
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close() 上述代码修改之后,在根目录caffe-Mobilenet-YOLO-master执行上述代码即可,
在data/VOCdevkit/MyDataSet/ImageSets下生成trainval.txt、test.txt、train.txt、val.txt等所需的txt文件,如下图所示:
这些TXT文件会包含图片的名字,不带路径,如下图所示:

2.2 lmdb文件生成
【1】执行如下命令,将生成lmdb所需的脚本复制至data/VOCdevkit/MyDataSet文件夹内:
cp data/VOC0712/create_* data/MyDataSet/ # 把create_list.sh和create_data.sh复制到MyDataSet目录
cp data/VOC0712/labelmap_voc.prototxt data/MyDataSet/ # 把labelmap_voc.prototxt复制到MyDataSet目录 
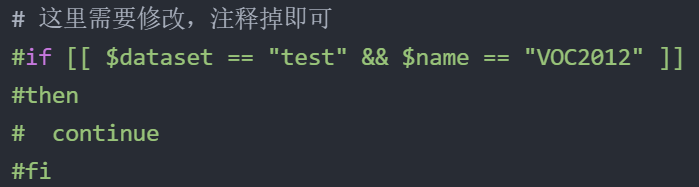
【2】修改create_list.sh文件:
1 第3行修改目录路径,截止到VOCdevkit即可

2 第13行修改为for name in MyDataSet(VOCdevkit下自己建立的文件夹名字)

3 第15-18行注释掉
4 第41行get_image_size修改为自己的路径(注意,这里是build caffe_mobilenet_yolo之后才会形成的):

#!/bin/bash
# 如果严格安装我上述的步骤,就可以不用修改路径位置。
# 需要修改的位置也使用注释进行了标注和解释
# 这里需要更改,你数据的根目录位置,需要修改的地方!!!!
root_dir="/home/Documents/Caffe_Mobilenet_YOLOhttps://img.qb5200.com/download-x/data/VOCdevkit/"
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in MyDataSet # 如果你建立的不是MyDataSet,这里需要修改为你自己的名字
do
# 这里需要修改,注释掉即可
#if [[ $dataset == "test" && $name == "VOC2012" ]]
#then
# continue
#fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\/JPEGImages\//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-master/build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"【3】creat_data.sh修改:
1 第2行修改为自己的路径:root_dir="/home/Documents/caffe-MobileNet-YOLO-master/"

2 第7行修改为:data_root_dir="/home/Documents/caffe-MobileNet-YOLO-masterhttps://img.qb5200.com/download-x/data/VOVdevkit/

3 第8行修改为:dataset_name="MyDataSet"

4 第9行修改为:mapfile="\(root_dirhttps://img.qb5200.com/download-x/data/VOCdevkit/\)dataset_name/labelmap_voc.prototxt"

5 第26行修改为\(root_dirhttps://img.qb5200.com/download-x/data/VOCdevkit/\)dataset_name/$subset.txt

cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
# 修改为自己的路径
root_dir="/home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-master/"
cd $root_dir
redo=1
# 这里需要修改为自己的路径
data_root_dir="/home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-masterhttps://img.qb5200.com/download-x/data/VOCdevkit/"
dataset_name="MyDataSet" # 修改为自己的名字
mapfile="$root_dirhttps://img.qb5200.com/download-x/data/VOCdevkit/$dataset_name/labelmap_voc.prototxt" # 修改为自己的路径
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
# subset.txt路径需要修改
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type \
--label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width \
--resize-height=$height --check-label $extra_cmd $data_root_dir $root_dirhttps://img.qb5200.com/download-x/data/VOCdevkit/$dataset_name/$subset.txt \
$data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name【3】修改labelmap_voc.prototxt文件:
除了第一个背景标签部分不要修改,其他改成自己的标签就行,多的删掉,少了添加进入就行
【4】最后在caffe-MobileNet-YOLO-master/examples文件夹内新建一个MyDataSet文件夹(空的)
【5】运行create_list.sh脚本: .https://img.qb5200.com/download-x/data/VOCdevkit/MyDataSet/create_list.sh,运行完后,会在自己建的VOCdevkit/MyDataSet/目录内生成trainval.txt, test.txt, test_name_size.txt。
【6】运行create_data.sh脚本: .https://img.qb5200.com/download-x/data/VOCdevkit/MyDataSet/create_data.sh
运行此命令时,提示:bash:.https://img.qb5200.com/download-x/data/VOCdevkit/MyDataSet/create_list.sh:Permission denied,没有权限,需要执行如下命令赋予执行命令:
chmod u+x data/VOCdevkit/MyDataSet/create_data.sh
出现了错误:ValueError: need more than 2 values to unpack,

需要将create_annoset.py中第88行的seg去掉,因为我们的Annotations只有两个值,img_file和anno。
运行完后,会在会在自己建的VOCdevkit/MyDataSet目录内生成lmdb文件夹:
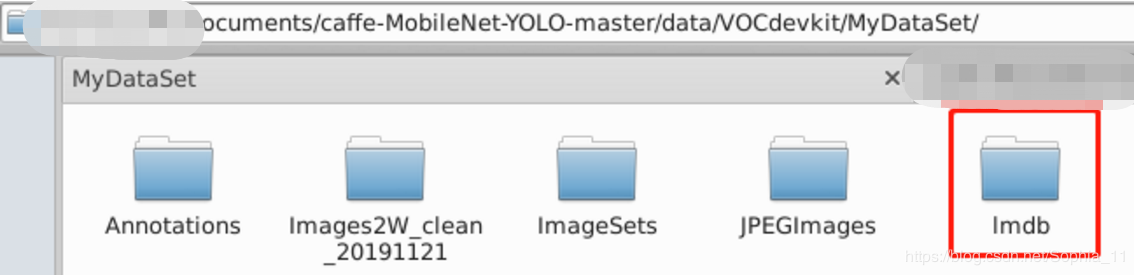
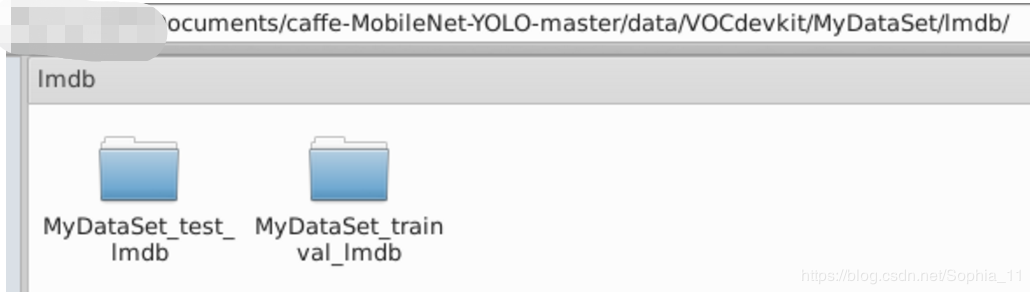
lmdb对应训练集和测试集的lmdb格式的文件夹:
 ***
***
好啦,今天的教程就到这里,如有疑问,可关注公众号【计算机视觉联盟】私信我或留言交流!!
加载全部内容