golang 服务诡异499、504网络故障排查
王清培 人气:2- 事故经过
- 排查
- 总结
事故经过
11-01 12:00 中午午饭期间,手机突然收到业务网关非200异常报警,平时也会有一些少量499或者网络抖动问题触发报警,但是很快就会恢复(目前配置的报警阈值是5%,阈值跟当时的采样窗口qps有直接关系)。
报警当时非200占比已经过10%并且在持续升高,根据历史规律应该很快就会恢复,我们稍微观察了几分钟(一边吃着很香的饺子一边看着手机),但是过了几分钟故障没有恢复而且占比升高了突破50%,故障逐渐升级(故障如果不在固定时间内解决会逐渐升级,故障群每次升级都会逐层拉更高level的boss进来)手机持续报警震动已经发烫了,故障占比已经快100%,影响面突然变大。
此时提现系统也开始报警,大量打款订单挤压(打款订单挤压突破一定阈值才会报警,所以不是实时),工位同事也反应支付系统也有少量连接错误,突然感觉情况复杂了,迅速停止吃饭,赶紧回公司排查。
回到工位时间差不多12:40左右,快速查看监控大盘,基本都是499、504错误,此类错误都是因为网络超时导致。
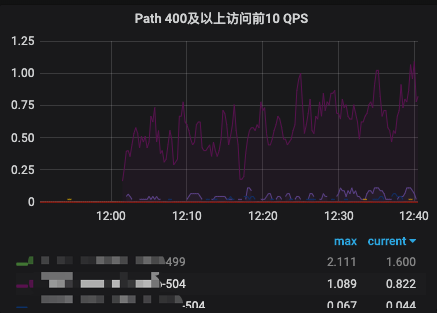
集群中的两台机器均有错,而且qps也比较平均,可以排除某台机器问题,
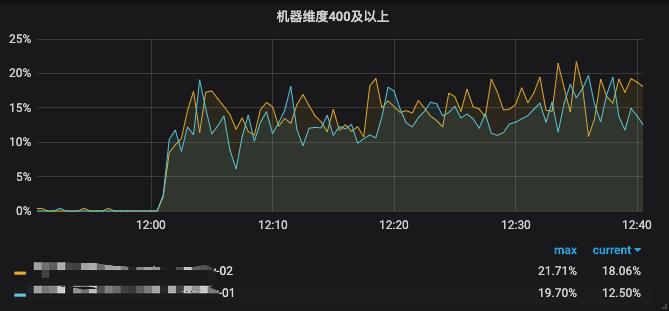
RT99线基本5s,而且连续横盘,这5s是触发了上游sidecar proxy调用超时主动断开了,真正的RT时间可能更长。
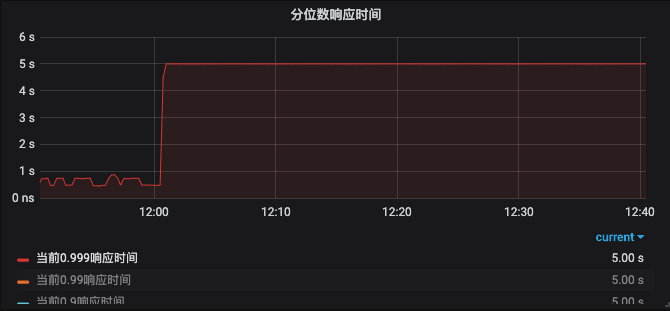
故障还未见恢复,业务运维协助一起排查,此时故障群已经升级到技术中心老大,压力瞬间大的一笔。
查看网关系统日志,大量调用我们内部的两个系统报出“下游服务器超时”错误,根据日志信息可以判断网络问题导致超时,但是我们调用的是内网服务,如果是网络问题为什么只有我们的系统受到影响。
在12:51到13:02之间错误占比情况有所好转,但是之后错误占比继续升高。
此时业务运维同步其他部门有大量302报警,时间线有点吻合,此时时间差不多13:30。但是别的部门的系统和我们的系统没有任何关系,太多的疑问大家开始集中坐到一起排查问题。
他们尝试做了版本回滚未见好转,然后尝试将访问返回302域名切到内网故障立马恢复,此时正好14:00。根据他们的反馈在做实验放量,导致在12:00的时候有一波流量高峰,但是这一波流量高峰对我的系统链路冲击在哪里,一脸懵逼,疑点重重。
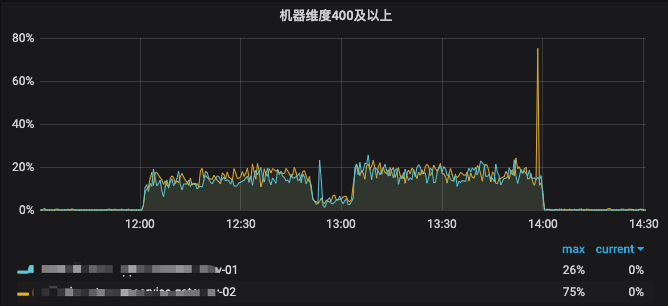
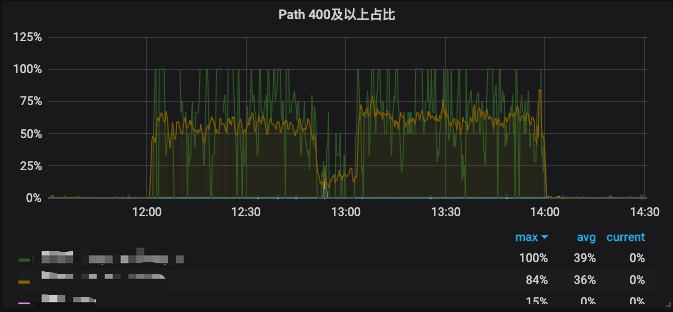
本次故障持续时间太长,报警整整报了两个小时,故障群每三种报警一次并且电话通知,报警电话几十个,微信报警群“灾难”级别的信息更多,严重程度可想而知。
排查
虽然故障是因为别的部门放量导致,但是还是有太多疑问没有答案,下次还会再出现。作为技术人员,线上环境是非常神圣的地方是禁区,一定要找到每次故障的 root cause,否则没办法给自己一个交代,我们开始逐层剥洋葱。
我们来梳理下疑问点:
1.302是什么原因,为什么做了域名切换就整体恢复了?
2.两边的系统在链路上有什么交集?如果应用链路没有交集,那么在网络链路上是否有交集?
3.我们业务网关中的“下游服务器超时”为什么其他系统没有影响?对日志的解读或者描述是否有歧义?
4.504是触发sidecar proxy 超时断开连接,网关服务设置的超时为什么没起作用?
1.302是什么原因,为什么做了域名切换就整体恢复了?
经过我们的运维和阿里云专家的排查,出现大量302是因为访问的域名触发DDos/CC高防策略。由于访问的域名配置了DDos/CC高防策略,大量请求触发了其中一条规则导致拒绝请求(具体触发了什么规则就不方便透露),所以会返回302,通过添加白名单可以解决被误杀的情况。
(从合理性角度讲内部调用不应该走到外网,有一部分是历史遗留问题。)
2.两边的系统在链路上有什么交集?如果应用链路没有交集,那么在网络链路上是否有交集?
所有人焦点都集中在高防上,认为网关故障就是因为也走到了被高防的地址上,但是我们的网关配置里根本没有这个高防地址,而且我们内部系统是不会有外网地址的。
排查提现系统问题,提现系统的配置里确实有用到被高防的外网地址,认为提现打款挤压也是因为走到了高防地址,但是这个高防地址只是一个旁路作用,不会影响打款流程。但是配置里确实有配置到,所以有理由判断肯定使用到了才会影响,这在当时确实是个很重要的线索,是个突破口。
根据这个线索认为网关系统虽然本身没有调用到高防地址,但是调用的下游也有可能会走到才会导致整个链路出现雪崩的问题。
通过大量排查下游服务,翻代码、看日志,基本上在应用层调用链路没有找到任何线索。开始在网络层面寻找线索,由于是内网调用所以路线是比较简单的,client->slb->gateway->slb->sidecar proxy->ecs,几个下游被调用系统请求一切正常,slb、sidecar proxy监控也一切正常,应用层、网络层都没有找到答案。
sidecar proxy 因为没有打开日志所以看不到请求(其实有一部分调用没有直连还是通过slb、vtm中转),从监控上看下游的 sidecar proxy 也一切正常,如果网路问题肯定是连锁反应。
百般无解之后,开始仔细检查当天出现故障的所有系统日志(由于现在流行Microservice所以服务比较多,错误日志量也比较大),在排查到支付系统的渠道服务时发现有一些线索,在事故发生期间有一些少量的 connection reset by peer,这个错误基本上多数出现在连接池化技术中使用了无效连接,或者下游服务器发生重启导致。但是在事故当时并没有发布。
通过对比前一周日志没有发生此类错误,那很有可能是很重要的线索,联系阿里云开始帮忙排查当时ecs实例在链路上是否有问题,惊喜的是阿里云反馈在事故当时出现 nat网关 限流丢包,一下子疑问全部解开了。
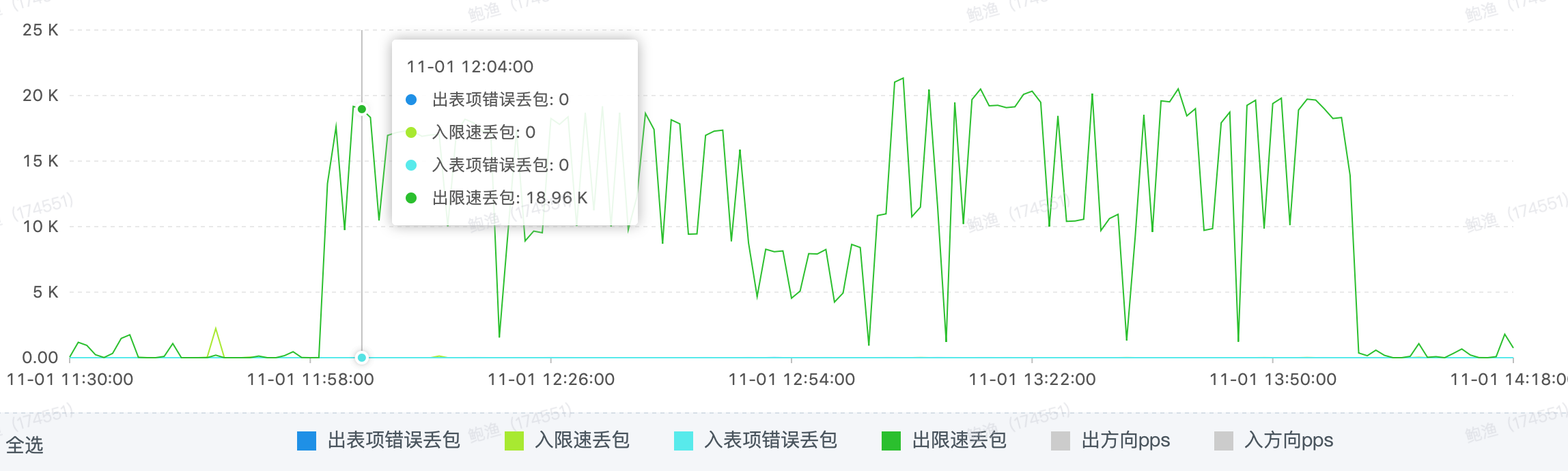
限流丢包才是引起我们系统大量错误的主要原因,所以整个故障原因是这样的,由于做活动放量导致高防302和出网限流丢包,而我们系统受到影响都是因为需要走外网,提现打款需要用到支付宝、微信等支付渠道,而支付系统也是需要出外网用到支付宝、微信、银联等支付渠道。
(由于当时我们并没有nat网关的报警导致我们都一致认为是高防拦截了流量。)
问题又来了,为什么网关调用内部系统会出现问题,但是答案已经很明显。简单的检查了下其中一个调用会走到外网,网关的接口会调用下游三个服务,其中第一个服务调用就是会出外网。
这个问题是找到了,但是为什么下游设置的超时错误一个没看见,而且“下游服务器超时”的错误日志stack trace 堆栈信息是内网调用,这个还是没搞明白。
3.我们业务网关中的“下游服务器超时”为什么其他系统没有影响?对日志的解读或者描述是否有歧义?
通过分析代码,这个日志的输出并不是直接调用某个服务发生超时timeout,而是 go Context.Done() channel 的通知,我们来看下代码:
func Send(ctx context.Context, serverName, method, path string, in, out interface{}) (err error) {
e := make(chan error)
go func() {
opts := []utils.ClientOption{
utils.WithTimeout(time.Second * 1),
}
if err = utils.HttpSend(method, path, in, out, ops, opts...); err != nil {
e <- err
return
}
e <- nil
}()
select {
case err = <-e:
return
case <-ctx.Done():
err = errors.ErrClientTimeOut
return
}
}Send 的方法通过 goroutine 启动一个调用,然后通过 select channel 感知http调用的结果,同时通过 ctx.Done() 感知本次上游http连接的 canceled。
err = errors.ErrClientTimeOut
ErrClientTimeOut = ErrType{64012, "下游服务器超时"}这里的 errors.ErrClientTimeOut 就是日志“下游服务器超时”的错误对象。
很奇怪,为什么调用下游服务器没有超时错误,明明设置了timeout时间为1s。
opts := []utils.ClientOption{
utils.WithTimeout(time.Second * 1),
}
if err = utils.HttpSend(method, path, in, out, ops, opts...); err != nil {
e <- err
return
}这个 utils.HttpSend 是有设置调用超时的,为什么一条调用超时错误日志没有,跟踪代码发现虽然opts对象传给了utils.HttpSend方法,但是里面却没有设置到 __http.Client__对象上。
client := &http.Client{}
// handle option
{
options := defaultClientOptions
for _, o := range opts {
o(&options)
}
for _, o := range ops {
o(req)
}
//set timeout
client.Timeout = options.timeout
}
// do request
{
if resp, err = client.Do(req); err != nil {
err = err502(err)
return
}
defer resp.Body.Close()
}就是缺少一行 client.Timeout = options.timeout 导致http调用未设置超时时间。加上之后调用一旦超时会抛出 “net/http: request canceled (Client.Timeout exceeded while awaiting headers)” timeout 错误。
问题我们大概知道了,就是因为我们没有设置下游服务调用超时时间,导致上游连接超时关闭了,继而触发context.canceled事件。
上层调用会逐个同步进行。
couponResp, err := client.Coupon.GetMyCouponList(ctx, r)
// 不返回错误 降级为没有优惠券
if err != nil {
logutil.Logger.Error("get account coupon faield",zap.Any("err", err))
}
coins, err := client.Coin.GetAccountCoin(ctx, cReq.UserID)
// 不返回错误 降级为没有金币
if err != nil {
logutil.Logger.Error("get account coin faield",zap.Any("err", err))
}
subCoins, err := client.Coin.GetSubAccountCoin(ctx, cReq.UserID)
// 不返回错误 降级为没有金币
if err != nil {
logutil.Logger.Error("get sub account coin faield",zap.Any("err", err))
}client.Coupon.GetMyCouponList 获取优惠券
client.Coin.GetAccountCoin 获取金币账户
client.Coin.GetSubAccountCoin 获取金币子账户
这三个方法内部都会调用Send方法,这个接口逻辑就是获取用户名下所有的现金抵扣权益,并且在超时时间内做好业务降级。但是这里处理有一个问题,就是没有识别Send方法返回的错误类型,其实连接断了之后程序再往下走已经没有意义也就失去了Context.canceld的意义。
(go和其他主流编程语言在线程(Thread)概念上有一个很大的区别,go是没有线程概念的(底层还是通过线程在调度),都是goroutine。go也是完全隐藏routine的,你无法通过类似Thread Id 或者 Thread local线程本地存储等技术,所有的routine都是通过context.Context对象来协作,比如在java 里要想取消一个线程必须依赖Thread.Interrupt中断,同时要捕获和传递中断信号,在go里需要通过捕获和传递Context信号。)
4.504是触发sidecar proxy 超时断开连接,网关服务器设置的超时为什么没起作用?
sidecar proxy 断开连接有三个场景:
1.499同时会关闭下游连接
2.504超时直接关闭下游连接
3.空闲超过60s关闭下游连接
事故当时499、504 sidecar proxy 主动关闭连接,网关服务Context.Done()方法感知到连接取消抛出异常,上层方法输出日志“下游服务器超时”。那为什么我们网关服务器本身的超时没起作用。
http/server.Server对象有四个超时参数我们并没有设置,而且这一类参数通常会被忽视,作为一个服务器本身对所有进来的请求是有最长服务要求,我们一般关注比较多的是下游超时会忽视服务本身的超时设置。
type Server struct {
// ReadTimeout is the maximum duration for reading the entire
// request, including the body.
//
// Because ReadTimeout does not let Handlers make per-request
// decisions on each request body's acceptable deadline or
// upload rate, most users will prefer to use
// ReadHeaderTimeout. It is valid to use them both.
ReadTimeout time.Duration
// ReadHeaderTimeout is the amount of time allowed to read
// request headers. The connection's read deadline is reset
// after reading the headers and the Handler can decide what
// is considered too slow for the body.
ReadHeaderTimeout time.Duration
// WriteTimeout is the maximum duration before timing out
// writes of the response. It is reset whenever a new
// request's header is read. Like ReadTimeout, it does not
// let Handlers make decisions on a per-request basis.
WriteTimeout time.Duration
// IdleTimeout is the maximum amount of time to wait for the
// next request when keep-alives are enabled. If IdleTimeout
// is zero, the value of ReadTimeout is used. If both are
// zero, ReadHeaderTimeout is used.
IdleTimeout time.Duration
}这些超时时间都会通过setDeadline计算成绝对时间点设置到netFD对象(Network file descriptor.)上。
由于没有设置超时时间所以相当于所有的连接关闭都是通过sidecar proxy触发传递下来的。
我们已经知道 sidecar proxy 关闭连接的1、2两种原因,第3种情况出现在http长连接上,但是这类连接关闭是无感知的。
默认的tcpKeepAliveListener对象的keepAlive是3分钟。
func (ln tcpKeepAliveListener) Accept() (net.Conn, error) {
tc, err := ln.AcceptTCP()
if err != nil {
return nil, err
}
tc.SetKeepAlive(true)
tc.SetKeepAlivePeriod(3 * time.Minute)
return tc, nil
}我们服务host是使用endless框架,默认也是3分钟,这其实是个约定90s,过小会影响上游代理。
func (el *endlessListener) Accept() (c net.Conn, err error) {
tc, err := el.Listener.(*net.TCPListener).AcceptTCP()
if err != nil {
return
}
tc.SetKeepAlive(true) // see http.tcpKeepAliveListener
tc.SetKeepAlivePeriod(3 * time.Minute) // see http.tcpKeepAliveListener
c = endlessConn{
Conn: tc,
server: el.server,
}
el.server.wg.Add(1)
return
}sidecar proxy 的超时是60s,就算我们要设置keepAlive的超时时间也要大于60s,避免sidecar proxy使用了我们关闭的连接。
(但是这在网络不稳定的情况下会有问题,如果发生HA Failover 然后在一定小概率的心跳窗口内,服务状态并没有传递到注册中心,导致sidecar proxy重用了之前的http长连接。这其实也是个权衡,如果每次都检查连接状态一定会影响性能。)
这里有个好奇问题,http是如何感知到四层tcp的状态,如何将Context.cancel的事件传递上来的,我们来顺便研究下。
type conn struct {
// server is the server on which the connection arrived.
// Immutable; never nil.
server *Server
// cancelCtx cancels the connection-level context.
cancelCtx context.CancelFunc
}func (c *conn) serve(ctx context.Context) {
// HTTP/1.x from here on.
ctx, cancelCtx := context.WithCancel(ctx)
c.cancelCtx = cancelCtx
defer cancelCtx()
c.r = &connReader{conn: c}
c.bufr = newBufioReader(c.r)
c.bufw = newBufioWriterSize(checkConnErrorWriter{c}, 4<<10)
for {
w, err := c.readRequest(ctx)
if !w.conn.server.doKeepAlives() {
// We're in shutdown mode. We might've replied
// to the user without "Connection: close" and
// they might think they can send another
// request, but such is life with HTTP/1.1.
return
}
if d := c.server.idleTimeout(); d != 0 {
c.rwc.SetReadDeadline(time.Now().Add(d))
if _, err := c.bufr.Peek(4); err != nil {
return
}
}
c.rwc.SetReadDeadline(time.Time{})
}
}// handleReadError is called whenever a Read from the client returns a
// non-nil error.
//
// The provided non-nil err is almost always io.EOF or a "use of
// closed network connection". In any case, the error is not
// particularly interesting, except perhaps for debugging during
// development. Any error means the connection is dead and we should
// down its context.
//
// It may be called from multiple goroutines.
func (cr *connReader) handleReadError(_ error) {
cr.conn.cancelCtx()
cr.closeNotify()
}
// checkConnErrorWriter writes to c.rwc and records any write errors to c.werr.
// It only contains one field (and a pointer field at that), so it
// fits in an interface value without an extra allocation.
type checkConnErrorWriter struct {
c *conn
}
func (w checkConnErrorWriter) Write(p []byte) (n int, err error) {
n, err = w.c.rwc.Write(p)
if err != nil && w.c.werr == nil {
w.c.werr = err
w.c.cancelCtx()
}
return
}其实tcp的状态不是通过主动事件触发告诉上层http的,而是每当http主动去发现。
read时使用connReader来感知tcp状态,writer时使用checkConnErrorWriter对象来感知tcp状态,然后通过server.conn对象中的cancelCtx来递归传递。
type conn struct {
// server is the server on which the connection arrived.
// Immutable; never nil.
server *Server
// cancelCtx cancels the connection-level context.
cancelCtx context.CancelFunc
}总结
此次故障排查了整整两天半,很多点是需要去反思和优化的。
1.所有的网络调用没有抛出最原始error信息。(经过加工之后的日志会严重误导人。)
2.超时时间的设置未能起到作用,未经过完整的压测和故障演练,所以超时时间很容易无效。
3.内外网域名没有隔离,需要区分内外网调用,做好环境隔离。
4.http服务器本身的超时没有设置,如果程序内部出现问题导致处理超时,并发会把服务器拖垮。
5.对云上的调用链路和网络架构需要非常熟悉,这样才能快速定位问题。
其实系统一旦上云之后整个网络架构变得复杂,干扰因素太多,排查也会面临比较大的依赖,监控告警覆盖面和基数也比较大很难察觉到个别业务线。(其实有些问题根本找不到答案。)
所有无法复现的故障是最难排查的,因为只能事后靠证据一环环解释,涉及到网络问题情况就更加复杂。
作者:王清培(趣头条 Tech Leader)
加载全部内容