transformer模型简介
sunshine丶23 人气:1Transformer模型由《Attention is All You Need》提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成。论文地址:https://arxiv.org/abs/1706.03762。
其整体结构如图所示:
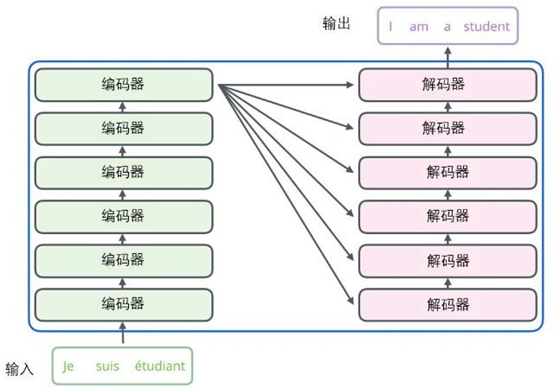
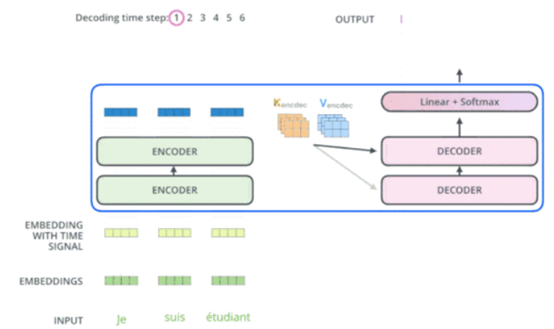
模型分为编码器(Encoder)和解码器(Decoder)两部分,包含内部结构的总体结构如下图所示:
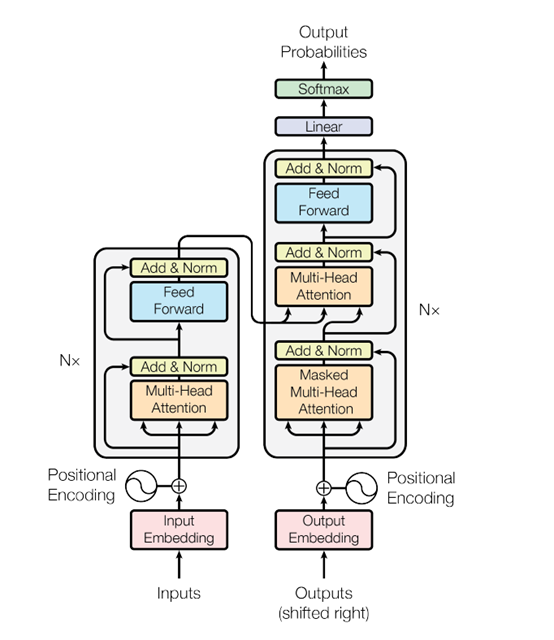
图二
在论文中编码器部分由6个相同编码器叠在一起,解码器部分也是由6个相同解码器叠在一起,编码器之间不共享参数。(这里不一定要是6个)
在将词向量表示送入编码器、解码器之前,先做positional encoding,下面依次对positional encoding、encoding、decoding进行介绍:
1、positional encoding
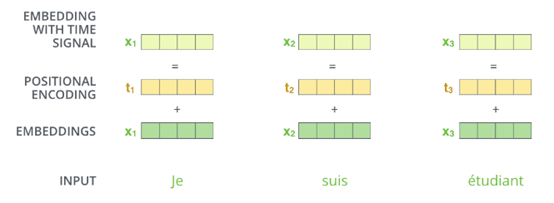
如图所示,由于attention机制不包含位置信息,因此句子首先进行embedding得到词向量表示,同时为了增加位置信息,根据句子中词的位置信息给词嵌入添加位置编码向量,论文中添加位置编码的方法是:构造一个跟输入embedding维度一样的矩阵,然后跟输入embedding相加得到multi-head attention 的输入。
作者使用的positional encoding如下:
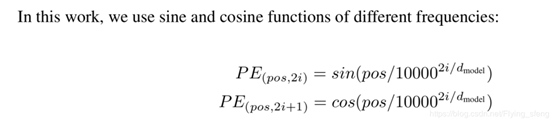
其中,PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;表示词向量的维度;i表示词向量的位置。因此,上述公式表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此来填满整个PE矩阵,然后加到input embedding中去,这样便完成位置编码的引入了。
2、encoding
如图二左边结构所示,编码器主要由前馈神经网络层与多头自注意力层构成,值得注意的是,在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。这里先介绍attention机制,还是举个栗子:
假设我们想要翻译这个句子:
“The animal didn't cross the street because it was too tired”
那么it在这句话中是是指animal还是street,人类好理解这句话,但是对机器来说就很困难了。当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。如下图。

当我们在编码器#5(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。
接下来介绍attention实现的思想。
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。在论文中这三个向量的维度比词嵌入向量要低,实际中维度更低不是必须的,只是架构上的选择,可以使多头注意力的大部分计算保持不变。
计算自注意力的第二步是计算得分。假设我们需要对第一个词’Thinking’计算自注意力向量那么需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。
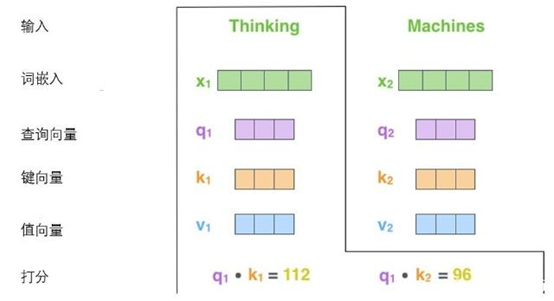
第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
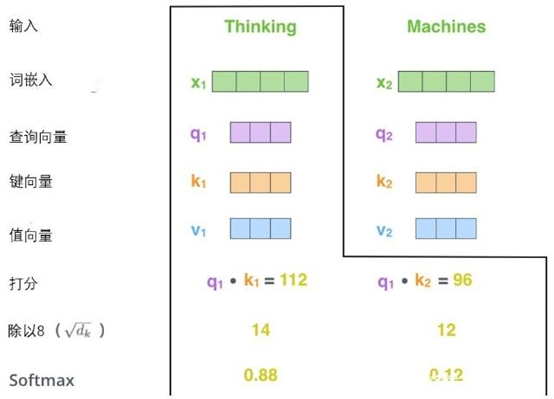
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步是将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词。
第六步是对加权值向量求和,然后即得到自注意力层在该位置的输出。
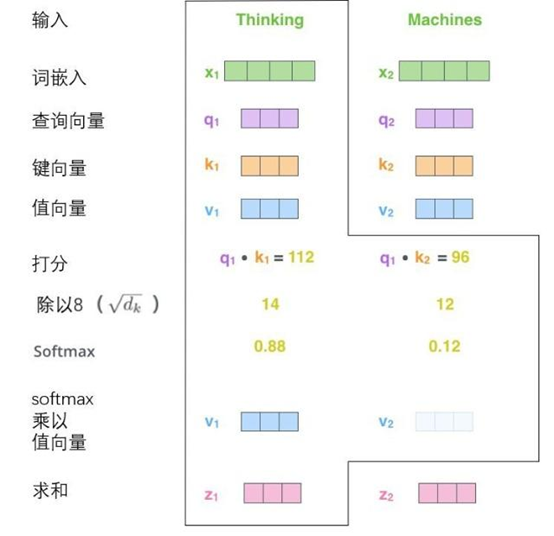
这样自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。
在现实中自注意力机制是通过矩阵来实现的,与上面思路一样:
第一步是计算查询矩阵、键矩阵和值矩阵,如下图所示:
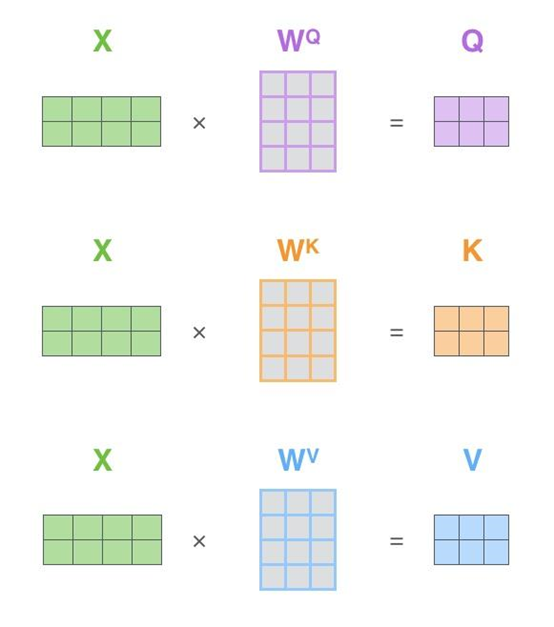
将前面的计算步骤可以合并成:
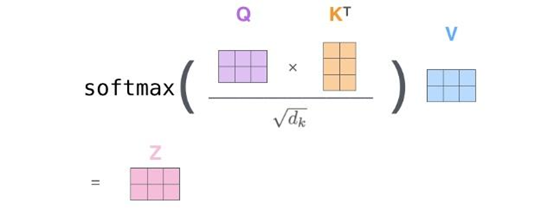
介绍完自注意力机制后,介绍在论文中使用的多头自注意力机制“multi-headed” attention。
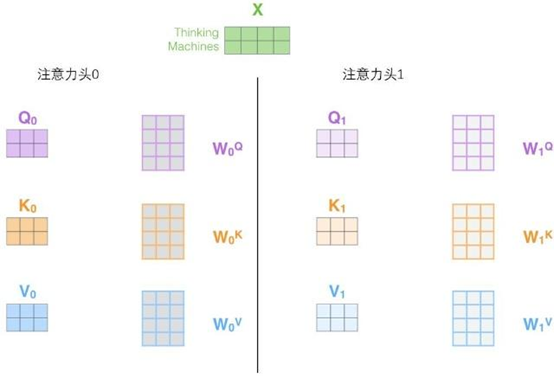
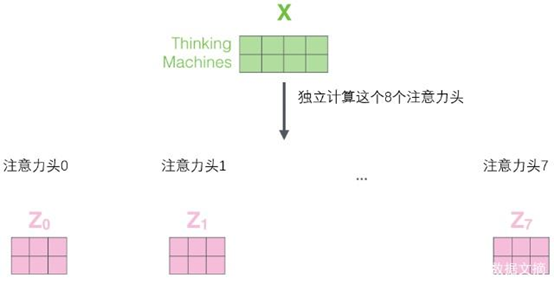
每个头都是独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。在论文中采用的是8头,那么经过8次不同权重矩阵运算,我们会得到8个不同的Z矩阵。
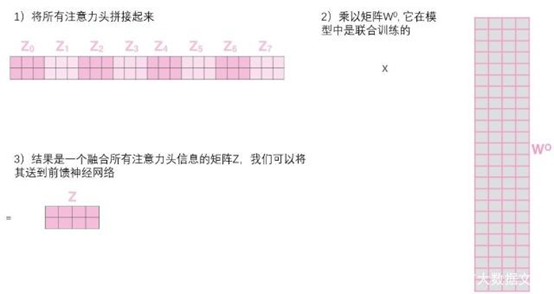
然后我们将这8个矩阵压缩成一个矩阵,实现原理是将这8个矩阵拼接在一起,然后再用一个权重矩阵与之相乘,得到一个融合所有注意力头信息的矩阵Z,再将其求和与归一化后传给前馈层。
Decoding(解码器):
解码器内部组件与编码器大同小异,需要注意的是,解码器的第一个注意力层被称作MaskedMulti-Head Attention,通过加入了MASK操作,使得我们只被允许处理输出序列中更靠前的那些位置,即我们只能attend到前面已经处理过的语句。第二个注意力层被称作encoder-decoder attention layer,由图二可知,它的query来自前一级的decoder层的输出,key、value来自encoder的输出,encoder的输出可以帮助解码器关注输入序列哪些位置合适。接下来送入前馈层,然后重复这些步骤,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
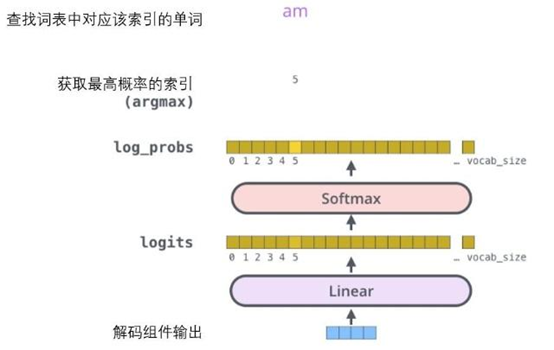
在解码完成后会输出一个实数向量,经过一个简单的全连接神经网络(线性变换层)映射到一个被称作对数几率(logits)的向量里,假设从训练集中学习一万个单词,那么对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
参考:attention is all you need
BERT大火却不懂Transformer?读这一篇就够了
transformer中的positional encoding(位置编码)
(完)
加载全部内容