【集合系列】- 初探java集合框架图
炸鸡可乐 人气:1一、集合类简介
Java集合就像一种容器,可以把多个对象(实际上是对象的引用,但习惯上都称对象)“丢进”该容器中。从Java 5 增加了泛型以后,Java集合可以记住容器中对象的数据类型,使得编码更加简洁、健壮。
Java集合大致可以分为两大体系,一个是Collection,另一个是Map
- Collection :主要由List、Set、Queue接口组成,List代表有序、重复的集合;其中Set代表无序、不可重复的集合;Java 5 又增加了Queue体系集合,代表一种队列集合实现。
- Map:则代表具有映射关系的键值对集合。
java.util.Collection下的接口和继承类关系简易结构图:
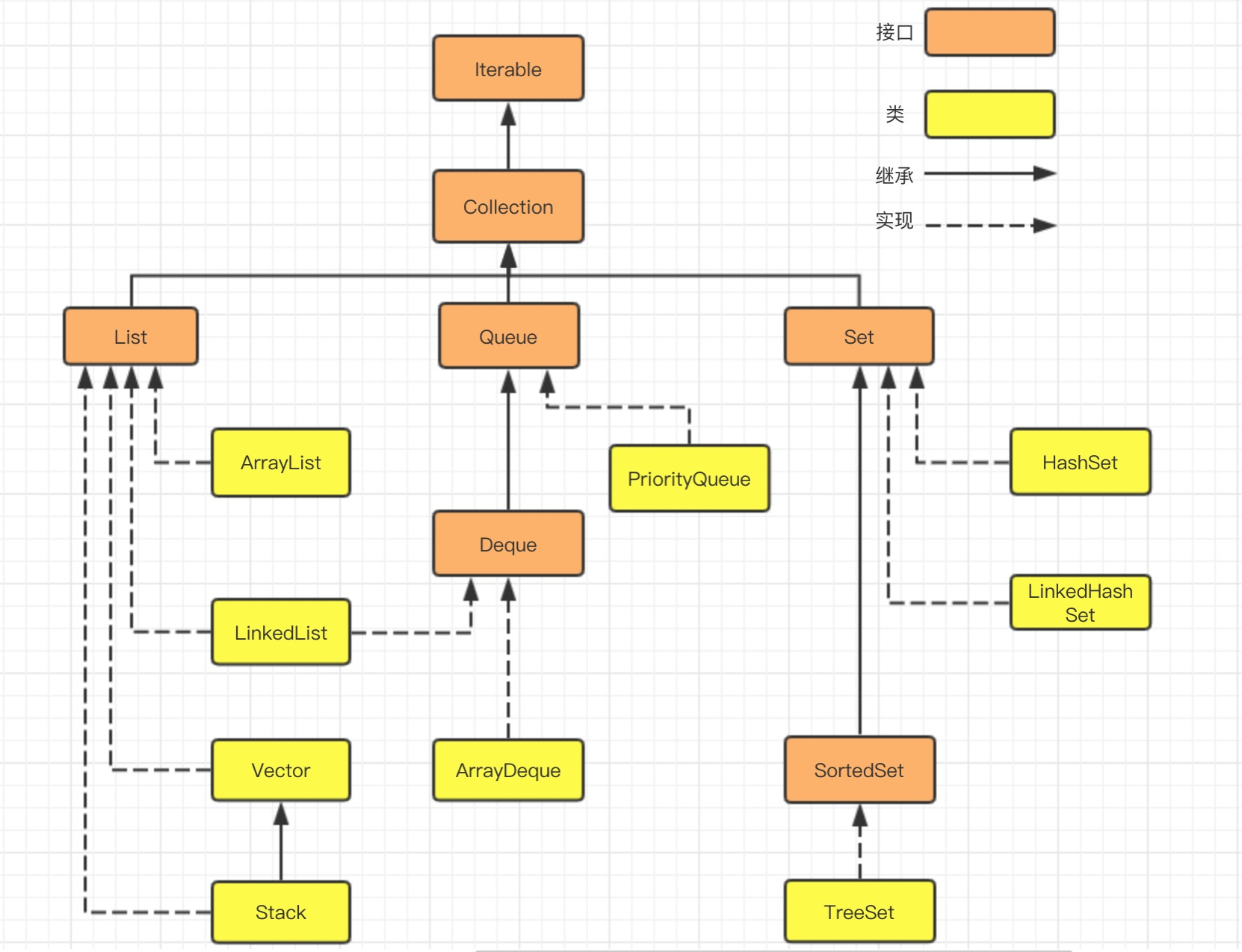
java.util.Map下的接口和继承类关系简易结构图:
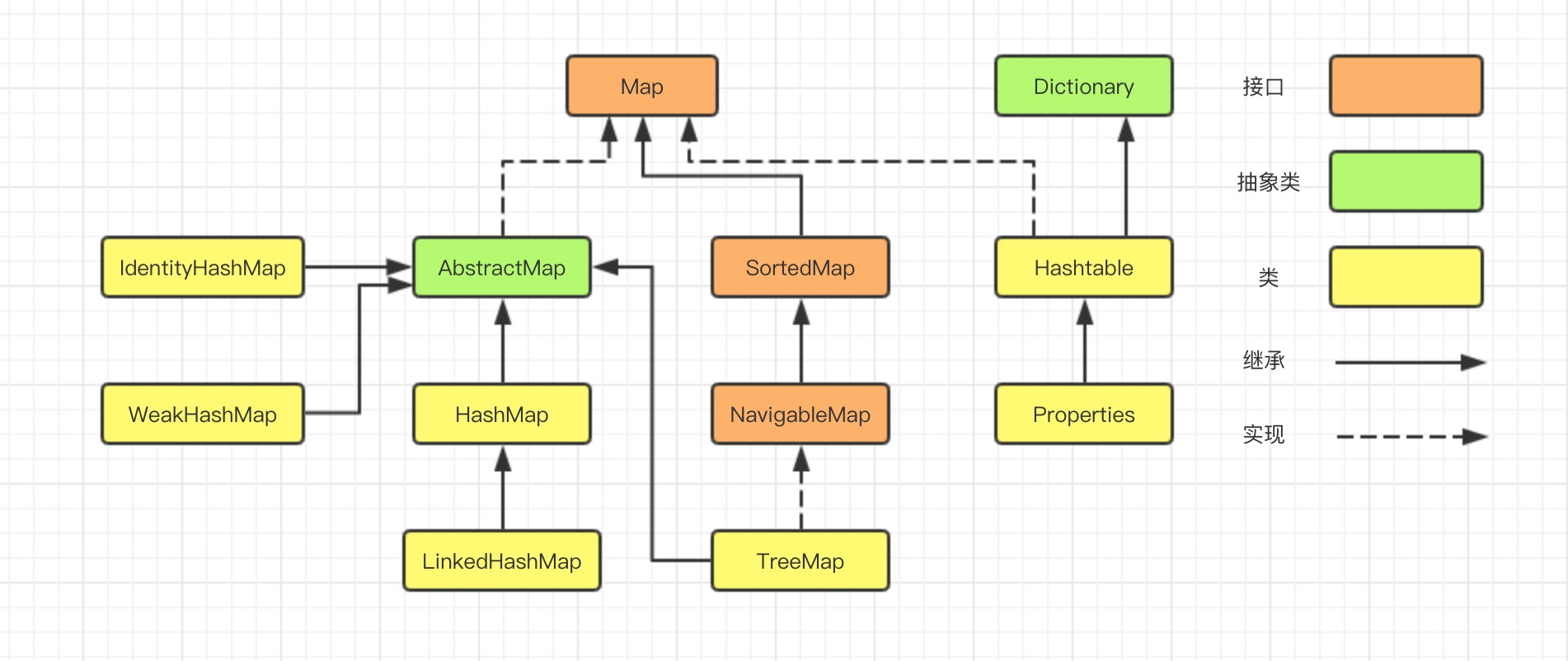
其中,Java 集合框架中主要封装的是典型的数据结构和算法,如动态数组、双向链表、队列、栈、Set、Map 等。
将集合框架挖掘处理,可以分为以下几个部分
1) 数据结构
List列表、Queue队列、Deque双端队列、Set集合、Map映射
2) 比较器
Comparator比较器、Comparable排序接口
3) 算法
Collections常用算法类、Arrays静态数组的排序、查找算法
4) 迭代器
Iterator通用迭代器、ListIterator针对 List 特化的迭代器
二、有序列表(List)
List集合的特点就是存取有序,可以存储重复的元素,可以用下标进行元素的操作
List主要实现类:ArrayList、LinkedList、Vector、Stack。
2.1、ArrayList
ArrayList是一个动态数组结构,支持随机存取,尾部插入删除方便,内部插入删除效率低(因为要移动数组元素);如果内部数组容量不足则自动扩容,因此当数组很大时,效率较低。
2.2、LinkedList
LinkedList是一个双向链表结构,在任意位置插入删除都很方便,但是不支持随机取值,每次都只能从一端开始遍历,直到找到查询的对象,然后返回;不过,它不像 ArrayList 那样需要进行内存拷贝,因此相对来说效率较高,但是因为存在额外的前驱和后继节点指针,因此占用的内存比 ArrayList 多一些。
2.3、Vector
Vector也是一个动态数组结构,一个元老级别的类,早在jdk1.1就引入进来类,之后在jdk1.2里引进ArrayList,ArrayList大部分的方法和Vector比较相似,两者是不同的,Vector是允许同步访问的,Vector中的操作是线程安全的,但是效率低,而ArrayList所有的操作都是异步的,执行效率高,但不安全!
关于Vector,现在用的很少了,因为里面的get、set、add等方法都加了synchronized,所以,执行效率会比较低,如果需要在多线程中使用,可以采用下面语句创建ArrayList对象
List<Object> list =Collections.synchronizedList(new ArrayList<Object>());也可以考虑使用复制容器 java.util.concurrent.CopyOnWriteArrayList进行操作,例如:
final CopyOnWriteArrayList<Object> cowList = new CopyOnWriteArrayList<String>(Object);2.4、Stack
Stack是Vector的一个子类,本质也是一个动态数组结构,不同的是,它的数据结构是先进后出,取名叫栈!
关于Stack,现在用的也很少,因为有个ArrayDeque双端队列,可以替代Stack所有的功能,并且执行效率比它高!
三、集(Set)
Set集合的特点:元素不重复,存取无序,无下标;
Set主要实现类:HashSet、LinkedHashSet和TreeSet。
3.1、HashSet
HashSet底层是基于 HashMap 的k实现的,元素不可重复,特性同 HashMap。
3.2、LinkedHashSet
LinkedHashSet底层也是基于 LinkedHashMap 的k实现的,一样元素不可重复,特性同 LinkedHashMap。
3.3、TreeSet
同样的,TreeSet也是基于 TreeMap 的k实现的,同样元素不可重复,特性同 TreeMap;
Set集合的实现,基本都是基于Map中的键做文章,使用Map中键不能重复、无序的特性;所以,我们只需要重点关注Map的实现即可!
四、队列(Queue)
Queue是一个队列集合,队列通常是指“先进先出”(FIFO)的容器。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素。
Queue主要实现类:ArrayDeque、LinkedList、PriorityQueue。
4.1、ArrayDeque
ArrayQueue是一个基于数组实现的双端队列,可以想象,在队列中存在两个指针,一个指向头部,一个指向尾部,因此它具有“FIFO队列”及“栈”的方法特性。
既然是双端队列,那么既可以先进先出,也可以先进后出,以下是测试例子!
先进先出
public static void main(String[] args) {
ArrayDeque<String> queue = new ArrayDeque<>();
//入队
queue.offer("AAA");
queue.offer("BBB");
queue.offer("CCC");
System.out.println(queue);
//获取但不出队
System.out.println(queue.peek());
System.out.println(queue);
//出队
System.out.println(queue.poll());
System.out.println(queue);
}输出结果:
[AAA, BBB, CCC]
AAA
[AAA, BBB, CCC]
AAA
[BBB, CCC]先进后出
public static void main(String[] args) {
ArrayDeque<String> stack = new ArrayDeque<>();
//压栈,此时AAA在最下,CCC在最外
stack.push("AAA");
stack.push("BBB");
stack.push("CCC");
System.out.println(stack);
//获取最后添加的元素,但不删除
System.out.println(stack.peek());
System.out.println(stack);
//弹出最后添加的元素
System.out.println(stack.pop());
System.out.println(stack);
}输出结果:
[CCC, BBB, AAA]
CCC
[CCC, BBB, AAA]
CCC
[BBB, AAA]4.2、LinkedList
LinkedList是List接口的实现类,也是Deque的实现类,底层是一种双向链表的数据结构,在上面咱们也有所介绍,LinkedList可以根据索引来获取元素,增加或删除元素的效率较高,如果查找的话需要遍历整合集合,效率较低,LinkedList同时实现了stack、Queue、PriorityQueue的所有功能。
例子
public static void main(String[] args) {
LinkedList<String> ll = new LinkedList<>();
//入队
ll.offer("AAA");
//压栈
ll.push("BBB");
//双端的另一端入队
ll.addFirst("NNN");
ll.forEach(str -> System.out.println("遍历中:" + str));
//获取队头
System.out.println(ll.peekFirst());
//获取队尾
System.out.println(ll.peekLast());
//弹栈
System.out.println(ll.pop());
System.out.println(ll);
//双端的后端出列
System.out.println(ll.pollLast());
System.out.println(ll);
}输出结果:
遍历中:NNN
遍历中:BBB
遍历中:AAA
NNN
AAA
NNN
[BBB, AAA]
AAA
[BBB]4.3、PriorityQueue
PriorityQueue也是一个队列的实现类,此实现类中存储的元素排列并不是按照元素添加的顺序进行排列,而是内部会按元素的大小顺序进行排列,是一种能够自动排序的队列。
例子
public static void main(String[] args) {
PriorityQueue<Integer> queue1 = new PriorityQueue<>(10);
System.out.println("处理前的数据");
Random rand = new Random();
for (int i = 0; i < 10; i++) {
Integer num = rand.nextInt(90) + 10;
System.out.print(num + ", ");
queue1.offer(num); // 随机两位数
}
System.out.println("\n处理后的数据");
for (int i = 0; i < 10; i++) { // 默认是自然排序 [升序]
System.out.print(queue1.poll() + ", ");
}
}输出结果:
处理前的数据
36, 23, 24, 11, 12, 26, 79, 96, 14, 73,
处理后的数据
11, 12, 14, 23, 24, 26, 36, 73, 79, 96, 五、映射表(Map)
Map是一个双列集合,其中保存的是键值对,键要求保持唯一性,值可以重复。
Map 主要实现类:HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties。
5.1、HashMap
关于HashMap,相信大家都不陌生,继承自AbstractMap,key 不可重复,因为使用的是哈希表存储元素,所以输入的数据与输出的数据,顺序基本不一致,另外,HashMap最多只允许一条记录的 key 为 null。
5.2、LinkedHashMap
HashMap 的子类,内部使用链表数据结构来记录插入的顺序,使得输入的记录顺序和输出的记录顺序是相同的。LinkedHashMap与HashMap最大的不同处在于,LinkedHashMap输入的记录和输出的记录顺序是相同的!
5.3、TreeMap
能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历时,得到的记录是排过序的;如需使用排序的映射,建议使用 TreeMap。TreeMap实际使用的比较少!
5.4、IdentityHashMap
继承自AbstractMap,与HashMap有些不同,在获取元素的时候,通过==代替equals ()来进行判断,比较的是内存地址。
get方法源码部分
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
//用==比较k和元素是否相等
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}5.5、WeakHashMap
WeakHashMap继承自AbstractMap,被称为缓存Map,向WeakHashMap中添加元素,再次通过键调用方法获取元素方法时,不一定获取到元素值,因为WeakHashMap 中的 Entry 可能随时被 GC 回收。
5.6、Hashtable
Hashtable,一个元老级的类,键值不能为空,与HashMap不同的是,方法都加了synchronized同步锁,是线程安全的,但是效率上,没有HashMap快!
同时,HashMap 是 HashTable 的轻量级实现,他们都完成了Map 接口,区别在于 HashMap 允许K和V为空,而HashTable不允许K和V为空,由于非线程安全,效率上可能高于 Hashtable。
如果需要在多线程环境下使用HashMap,可以使用如下的同步器来实现或者使用并发工具包中的ConcurrentHashMap类
Map<String, Object> map =Collections.synchronizedMap(new HashMap<>());5.7、Properties
Properties继承自HashTable,Properties新增了load()和和store()方法,可以直接导入或者将映射写入文件,另外,Properties的键和值都是String类型。
六、比较器
Comparable和Comparator接口都是用来比较大小的,一般在TreeSet、TreeMap接口中使用的比较多,主要用于解决排序问题。
6.1、Comparable
Comparable:对实现它的每个类的对象进行整体排序
package java.lang;
import java.util.*;
public interface Comparable<T> {
public int compareTo(T o);
}若一个类实现了Comparable 接口,实现 Comparable 接口的类的对象的 List 列表 ( 或数组)可以通过 Collections.sort(或 Arrays.sort)进行排序。
此外,实现 Comparable 接口的类的对象 可以用作 “有序映射 ( 如 TreeMap)” 中的键或 “有序集合 (TreeSet)” 中的元素,而不需要指定比较器。
使用例子:
/**
* 实体类Person实现Comparable接口
*/
public class Person implements Comparable<Person>{
private int age;
private String name;
public Person(String name, int age){
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o){
return this.age-o.age;
}
@Override
public String toString(){
return name+":"+age;
}
}测试
public static void main(String[] args) {
Person person1 = new Person("张三",18);
Person person2 = new Person("李四",17);
Person person3 = new Person("王五",19);
List<Person> list = new ArrayList<>();
list.add(person1);
list.add(person2);
list.add(person3);
System.out.println(list);
Collections.sort(list);
System.out.println(list);
}输出:
[张三:18, 李四:17, 王五:19]
[李四:17, 张三:18, 王五:19]6.2、Comparator
Comparator:也是对实现它的每个类的对象进行排序
package java.util;
import ***;
public interface Comparator<T> {
int compare(T o1, T o2);
......
}如果我们的这个类Person无法修改或者没有继承Comparable接口,我们又要对其进行排序,Comparator就可以派上用场了。
将类Person实现的Comparable接口去掉
/**
* 实体类Person
*/
public class Person {
private int age;
private String name;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name+":"+age;
}
}测试类:
public static void main(String[] args) {
Person person1 = new Person("张三",18);
Person person2 = new Person("李四",17);
Person person3 = new Person("王五",19);
List<Person> list = new ArrayList<>();
list.add(person1);
list.add(person2);
list.add(person3);
System.out.println(list);
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if(o1 == null || o2 == null){
return 0;
}
//o1比o2小,返回负数
//o1等于o2,等于0
//o1大于o2,返回正数
return o1.getAge()-o2.getAge();
}
});
System.out.println(list);
}输出:
[张三:18, 李四:17, 王五:19]
[李四:17, 张三:18, 王五:19]七、常用工具类
7.1、Collections类
java.util.Collections工具类为集合框架提供了很多有用的方法,这些方法都是静态的,在编程中可以直接调用。整个Collections工具类源码差不多有4000行,这里只针对一些典型的方法进行阐述。
7.1.1、addAll
addAll:向指定的集合c中加入特定的一些元素elements
public static <T> boolean addAll(Collection<? super T> c, T… elements)7.1.2、binarySearch
binarySearch:利用二分法在指定的集合中查找元素
#集合元素T实现Comparable接口的方式,进行查询
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key)
#元素以外部实现Comparator接口的方式,进行查询
public static <T> int binarySearch(List<? extends T> list, T key, Comparator<? super T> c)7.1.3、sort
#集合元素T实现Comparable接口的方式,进行排序
public static <T extends Comparable<? super T>> void sort(List<T> list)
#元素以外部实现Comparator接口的方式,进行排序
public static <T> void sort(List<T> list, Comparator<? super T> c)7.1.4、shuffle
shuffle:混排,随机打乱原来的顺序,它打乱在一个List中可能有的任何排列的踪迹。
#方法一
public static void shuffle(List<?> list)
#方法二,指定随机数访问
public static void shuffle(List<?> list, Random rnd)7.1.5、reverse
reverse:集合排列反转
#直接反转集合的元素
public static void reverse(List<?> list)
#返回可以使集合反转的比较器Comparator
public static <T> Comparator<T> reverseOrder()
#集合的反转的反转,如果cmp不为null,返回cmp的反转的比较器,如果cmp为null,效果等同于第二个方法.
public static <T> Comparator<T> reverseOrder(Comparator<T> cmp)7.1.6、synchronized系列
synchronized系列:确保所封装的集合线程安全(强同步)
#同步Collection接口下的实现类
public static <T> Collection<T> synchronizedCollection(Collection<T> c)
#同步SortedSet接口下的实现类
public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s)
#同步List接口下的实现类
public static <T> List<T> synchronizedList(List<T> list)
#同步Map接口下的实现类
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
#同步SortedMap接口下的实现类
public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m)7.2、Arrays类
java.util.Arrays工具类也为集合框架提供了很多有用的方法,这些方法都是静态的,在编程中可以直接调用。整个Arrays工具类源码有3000多行,这里只针对一些典型的方法进行阐述。
7.2.1、asList
asList:将一个数组转变成一个List,准确来说是ArrayList
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}注意:这个List是定长的,企图添加或者删除数据都会报错java.lang.UnsupportedOperationException
7.2.2、sort
sort:对数组进行排序,适合byte,char,double,float,int,long,short等基本类型,还有Object类型
#基本数据类型,例子int类型数组
public static void sort(int[] a)
#Object类型数组
#如果使用Comparable进行排序,Object需要实现Comparable
#如果使用Comparator进行排序,可以使用外部比较方法实现
public static void sort(Object[] a)7.2.3、binarySearch
binarySearch:通过二分查找法对已排序的数组进行查找。如果数组没有经过Arrays.sort排序,那么检索结果未知。
适合byte,char,double,float,int,long,short等基本类型,还有Object类型和泛型。
#基本数据类型,例子int类型数组,key为要查询的参数
public static int binarySearch(int[] a, int key)
#Object类型数组,key为要查询的参数
#如果使用Comparable进行排序,Object需要实现Comparable
#如果使用Comparator进行排序,可以使用外部比较方法实现
public static int binarySearch(Object[] a, Object key)7.2.4、copyOf
copyOf:数组拷贝,底层采用System.arrayCopy(native方法)实现。
适合byte,char,double,float,int,long,short等基本类型,还有泛型数组。
#基本数据类型,例子int类型数组,newLength新数组长度
public static int[] copyOf(int[] original, int newLength)
#T为泛型数组,newLength新数组长度
public static <T> T[] copyOf(T[] original, int newLength)7.2.5、copyOfRange
copyOfRange:数组拷贝,指定一定的范围,底层采用System.arrayCopy(native方法)实现。
适合byte,char,double,float,int,long,short等基本类型,还有泛型数组。
#基本数据类型,例子int类型数组,from:开始位置,to:结束位置
public static int[] copyOfRange(int[] original, int from, int to)
#T为泛型数组,from:开始位置,to:结束位置
public static <T> T[] copyOfRange(T[] original, int from, int to)7.2.6、equals和deepEquals
equals:判断两个数组的每一个对应的元素是否相等(equals, 对于两个数组的元素a和a2有a==null ? a2==null : a.equals(a2))
#基本数据类型,例子int类型数组,a为原数组,a2为目标数组
public static boolean equals(int[] a, int[] a2)
#Object数组,a为原数组,a2为目标数组
public static boolean equals(Object[] a, Object[] a2)deepEquals:主要针对一个数组中的元素还是数组的情况(多维数组比较)
#Object数组,a1为原数组,a2为目标数组
public static boolean deepEquals(Object[] a1, Object[] a2)7.2.7、toString和deepToString
toString:将数组转换成字符串,中间用逗号隔开
#基本数据类型,例子int类型数组,a为数组
public static String toString(int[] a)
#Object数组,a为数组
public static String toString(Object[] a)deepToString:当数组中又包含数组,就不能单纯的利用Arrays.toString()了,使用此方法将数组转换成字符串
#Object数组,a为数组
public static String deepToString(Object[] a)八、迭代器
JCF的迭代器(Iterator)为我们提供了遍历容器中元素的方法。只有容器本身清楚容器里元素的组织方式,因此迭代器只能通过容器本身得到。每个容器都会通过内部类的形式实现自己的迭代器。
ArrayList<String> list = new ArrayList<String>();
list.add(new String("a1"));
list.add(new String("a2"));
list.add(new String("a3"));
Iterator<String> it = list.iterator();//得到迭代器
while(it.hasNext()){
String obj = it.next();//访问元素
System.out.println(obj);
}JDK 1.5 引入了增强的for循环,简化了迭代容器时的写法
//使用增强for迭代
ArrayList<String> list = new ArrayList<String>();
list.add(new String("a1"));
list.add(new String("a2"));
list.add(new String("a3"));
for(String obj : list){
//enhanced for statement
System.out.println(obj);
}九、总结
以上,主要是对java集合的整体架构进行简单的介绍,如果有理解不当之处,欢迎指正。
十、参考
1、JDK1.7&JDK1.8 源码
2、Otokaze's Blog - Java Collection框架
3、CSDN - 朱小厮 - Comparable与Comparator浅析
作者:炸鸡可乐
原文出处:www.pzblog.cn
加载全部内容