MapReduce任务提交源码分析
菜菜菜鸡 人气:0为了测试MapReduce提交的详细流程。需要在提交这一步打上断点:
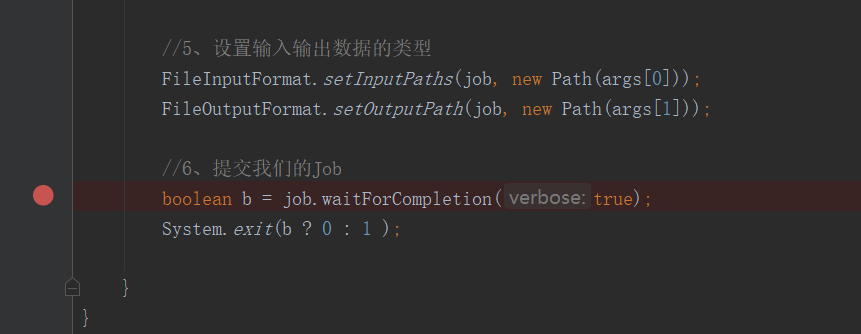
F7进入方法:
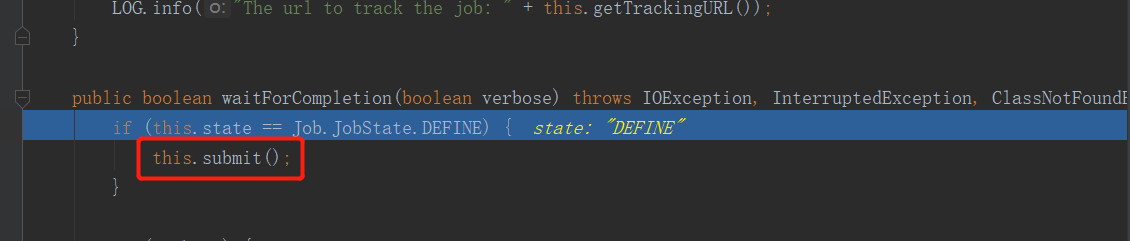
进入submit方法:
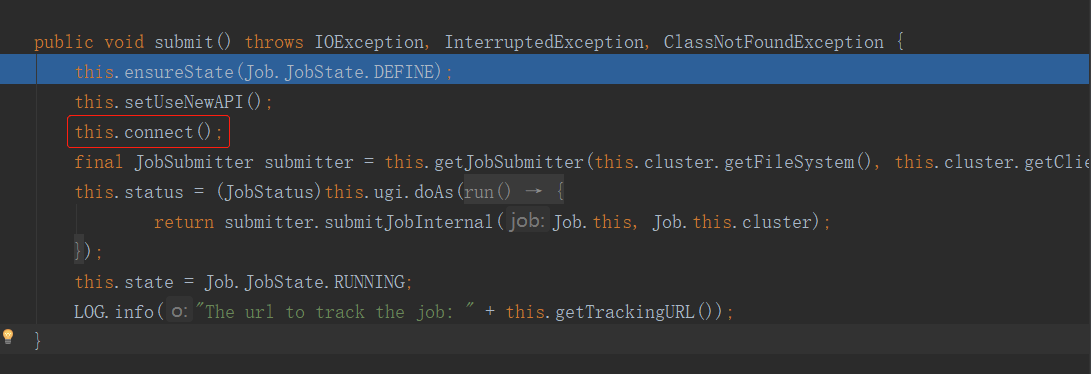
注意这个connect方法,它在连接谁呢?我们知道,Driver是作为客户端存在的,那么客户端连接的应该就是Yarn集群,但是在这个简单的WordCount案例中,并没有将任务提交到Yarn集群,而是在本机中执行的。座椅这里连接的自然就是本机。
进入这个connect方法,然后在里面的Cluster方法上打上断点:


很明显,这是一个构造器,他把集群抽象成了一个对象。进入此方法:
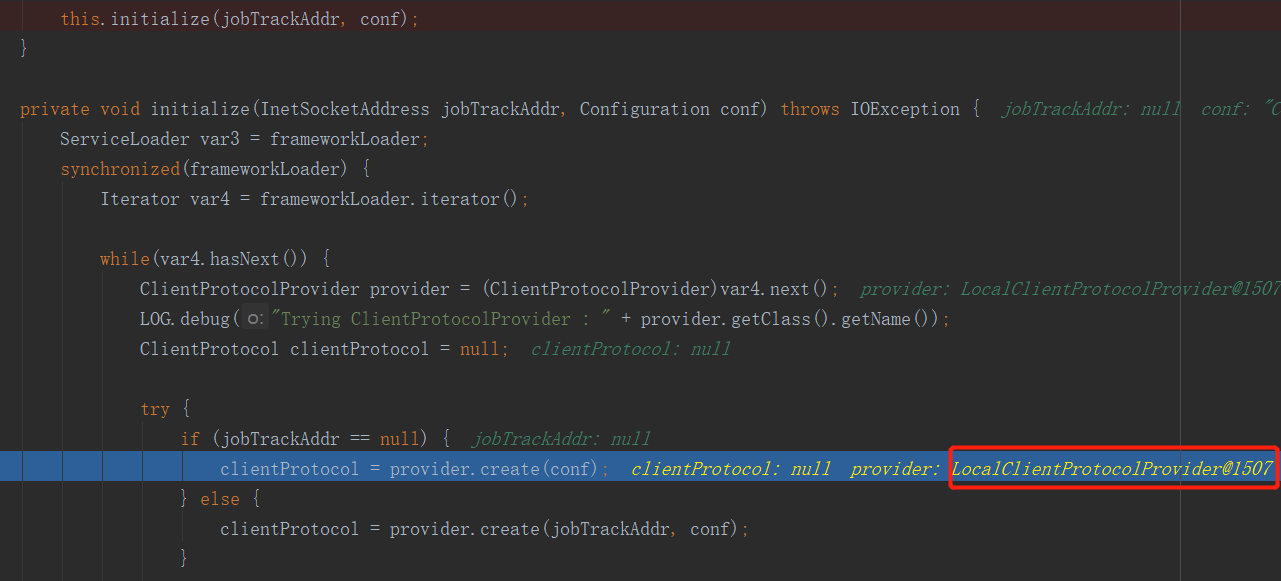
初始化了一个客户端协议,进入这个create方法,看看他是如何初始化客户端协议的:
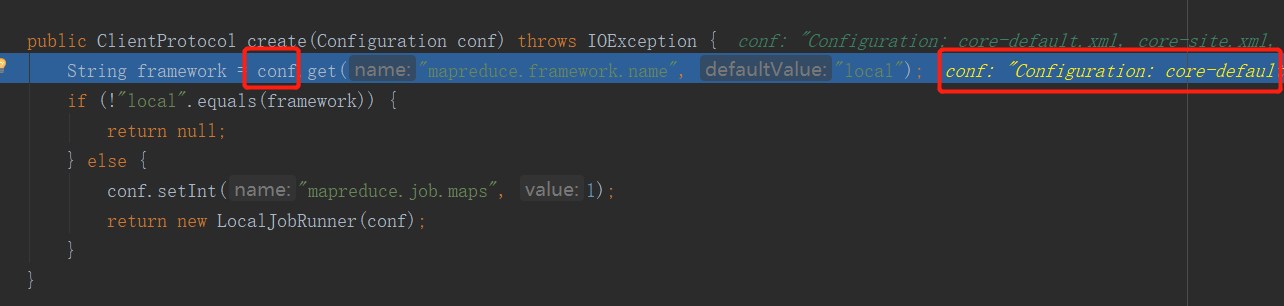
注意这个mapreduce.framework.name,他就是mapred-site.xml文件中的mapreduce.framework.name项的值,由于我并没有提交到集群上,而是在本机,所以他会加载本机的mapred-site.xml文件,但是我本机下的该文件并没有像集群上那样配置了mapred-site.xml文件,只有一份mapred-site.xml.template文件,更没有mapreduce.framework.name这一项,所以上面代码中的值就默认为local了。
本机上的配置:

集群上的配置:

create方法最终反回了一个LocalJobRunner对象,如果上面的值是yarn,返回的则是YarnJobRunner。继续往下:
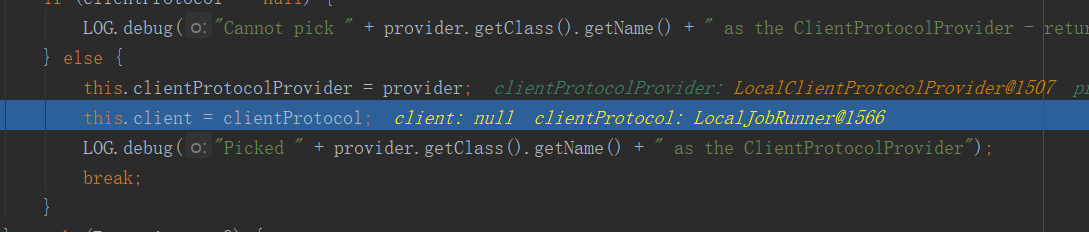
会发现这个LocalJobRunner就是客户端。然后一直往下,直到完成connect方法,会发现整个过程中在connect方法中创建了一个Cluster对象,然后在Cluster对象里面获取到了客户端。
紧接着,由于connect方法初始化了cluster对象,所以接下来创建了submitter对象,用于提交任务。进入submitJobInternal方法打上断点


这个checkSpecs方法就是用来检查路径的,当输入路径不存在或输出路径已存在时会报错。进入此方法后再进入内部方法就一目了然了:
继续往下执行,完成checkSpecs方法后完初始化一个路径:

打开此路径,此时还是空的文件夹:
继续往下,随后做了一些获取IP和往配置文件中设置IP和hostname的操作:

继续往下,随后又在上面的路径下随机创建了一个目录:

继续往下,见到copyAndConfigureFiles时,进入此方法,然后在进入内部方法uploadFiles():

在uploadFiles方法中有,执行后的效果:

这个文件夹暂时不知道干嘛的,只知道copyAndConfigureFiles方法创建了这个路径。此方法执行完后,执行到writeSplits进入此方法:

这个方法是重点:切片是怎么切的呢?
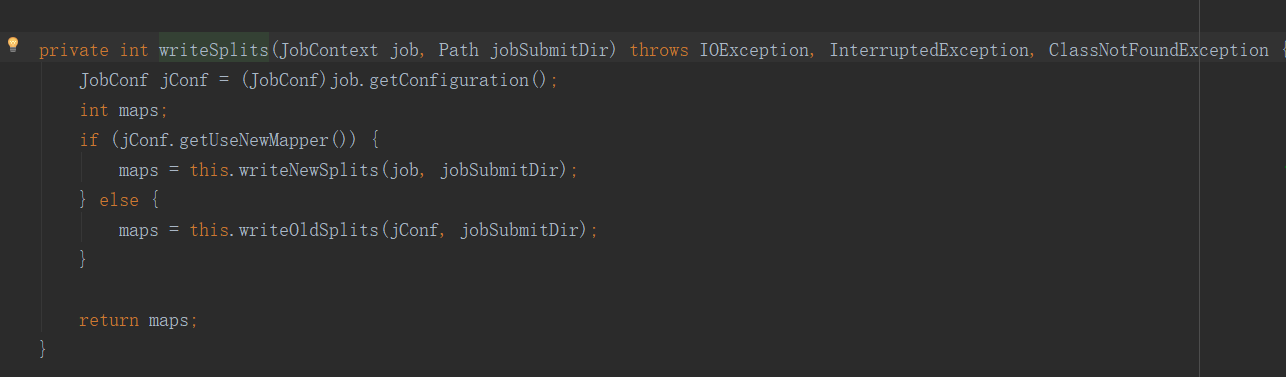
maps是int型,这表示这启动的maptask的数量也该和切片的数量保持一致。而具体切成多少片呢?
上面的方法多态调用到子类的方法writeNewSplits,然后调用getSplits方法:

getSplits方法中有这样一段:
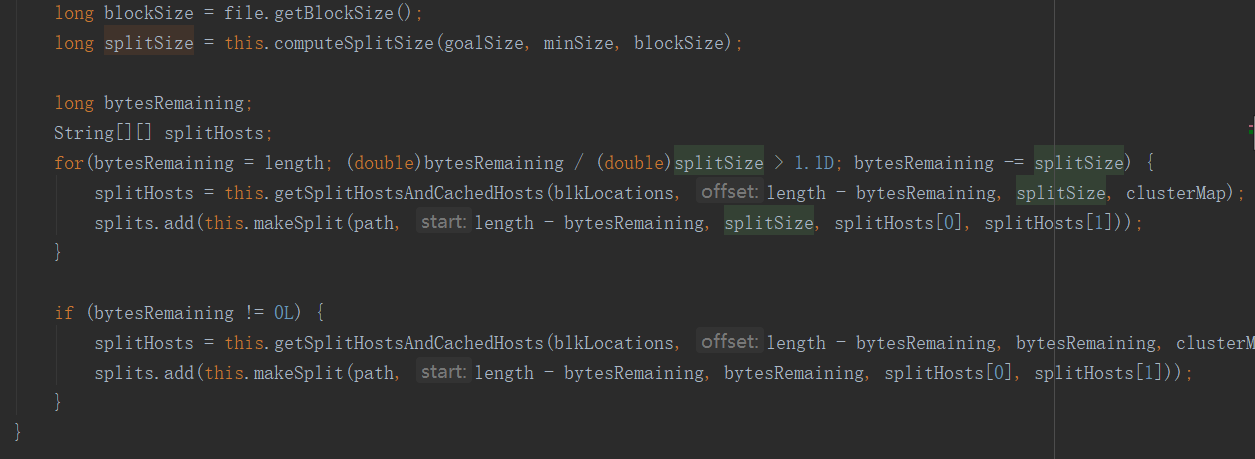
也就是说:当剩余长度比切片尺寸大于1.1时,就会产生新的切片,比如说文件65m,splitSize为32m,第一片切到32m,剩余33m,由于33/32<1.1,所以就不再切片,65m被切成两片,0~32、32~65,而不是0~32 、 32~64 、 64~65三片。
当执行完writeSplits方法后,会在上面创建的目录下生成几个文件:
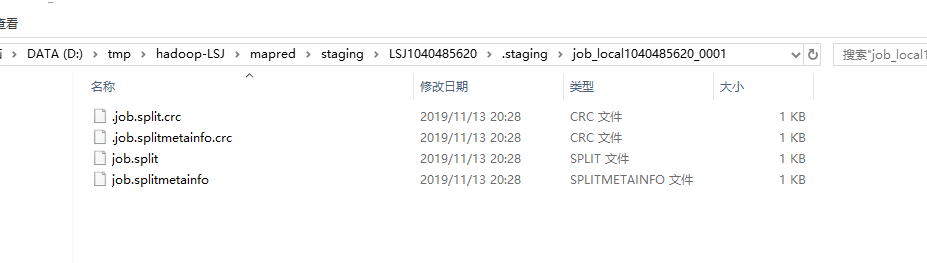
上面生成的文件中保存了“切片的规划信息”。继续往下,当执行到writeConf方法后,会继续在上面的目录下生成与此Job相关的配置文件:
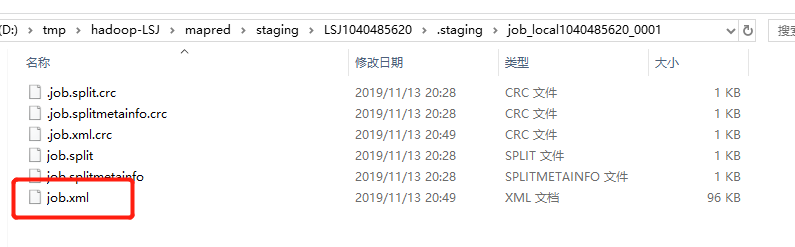
继续执行,当执行完submitJob方法后,job本身(即WordCount程序本身会被打成jar包被提交)就被提交了:
但是由于我是直接在本地执行的,直接从main方法进来执行的,没必要再打成jar包再从main方法进入,所以并不用提交,但是如果是是在yarn 上执行的时候,会把程序打成jar包放在上面的目录下。
当任务执行完毕后,上面的目录会被清空:
至此,整个任务的提交执行完成,试想一下,如果这个任务在Yarn上执行是什么样子呢?期待吗逻辑不会变:
首先,还是执行connect方法,初始化到Cluster对象,然后创建JobRunner,不过在Yarn上执行的JobRunner就不是LocalJobRunner了,而是YarnJobRunner。执行完connect方法后会在HDFS文件系统创建一个路径,其作用与上面创建的路径相同,用于保存切片方案信息和配置文件信息,同时会将任务本身的jar包放入其中,最后任务执行完,这些内容又将被销毁。
加载全部内容