python使用requests库爬取拉勾网招聘信息的实现
周少钦 人气:0按F12打开开发者工具抓包,可以定位到招聘信息的接口
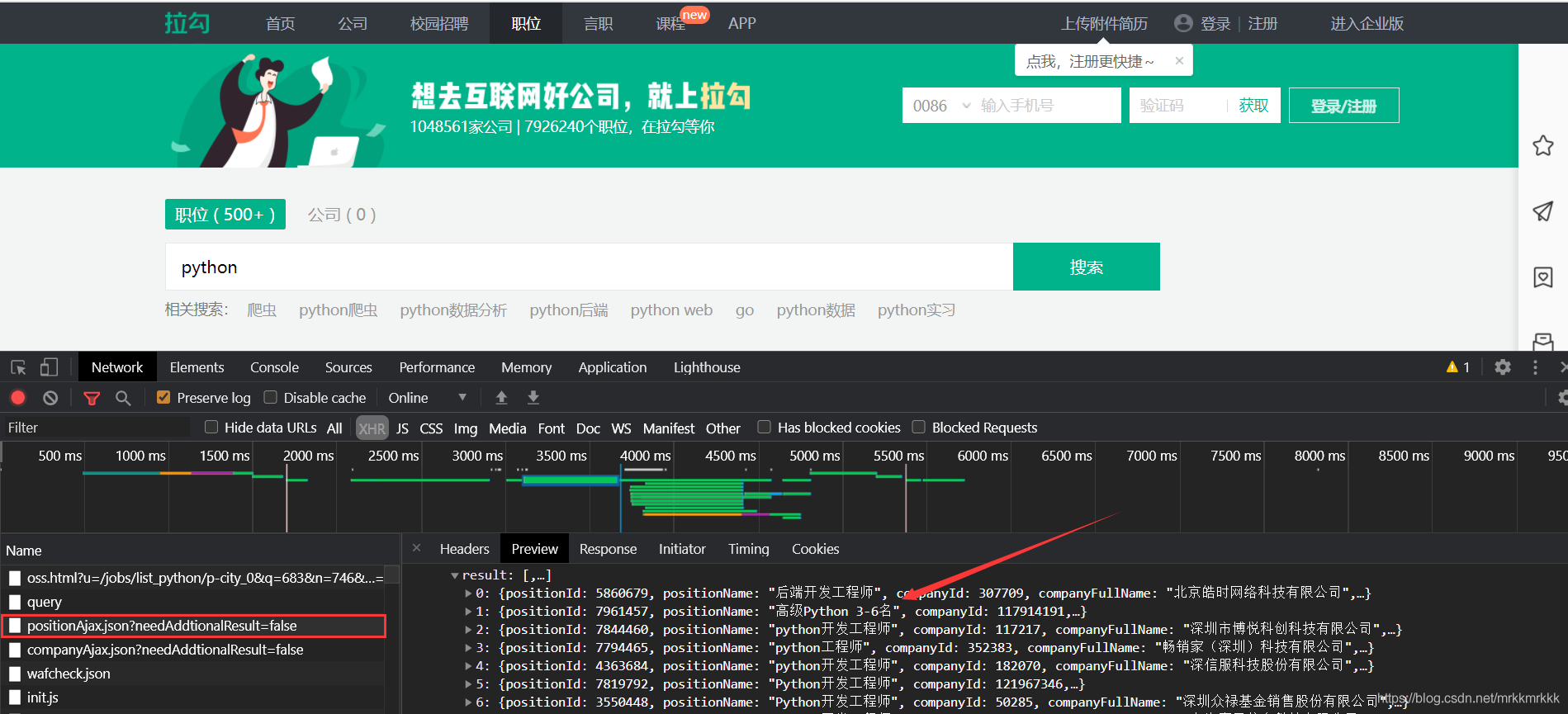
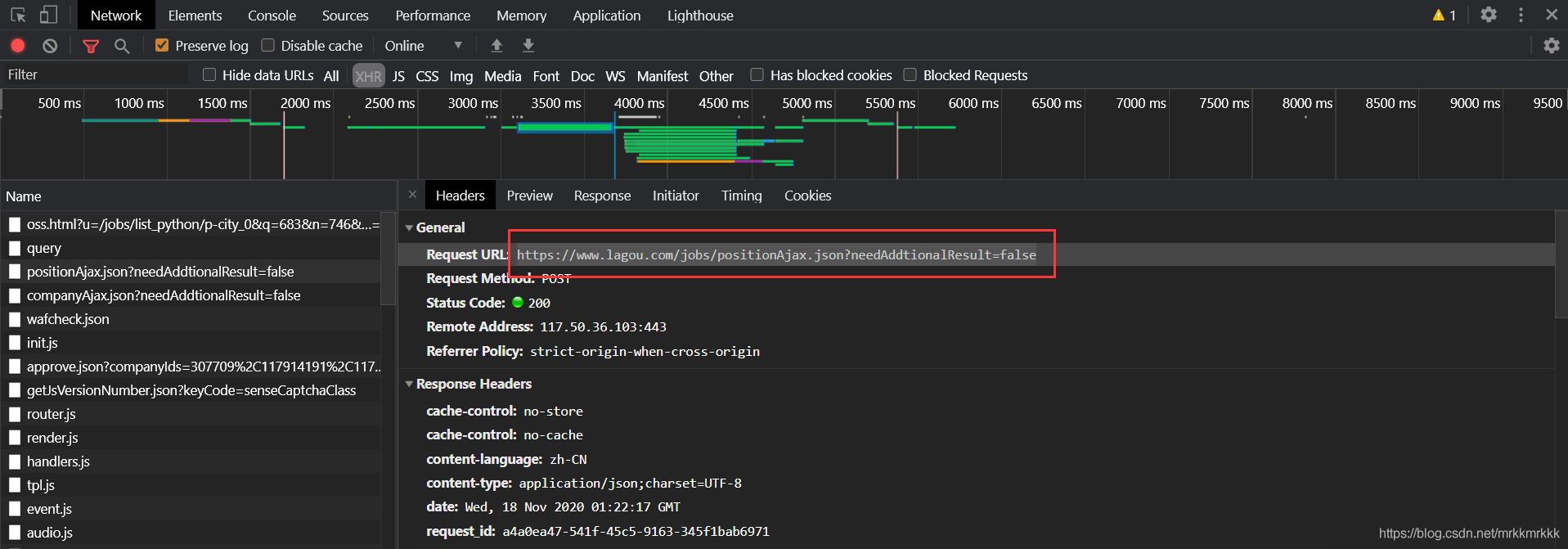
在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字
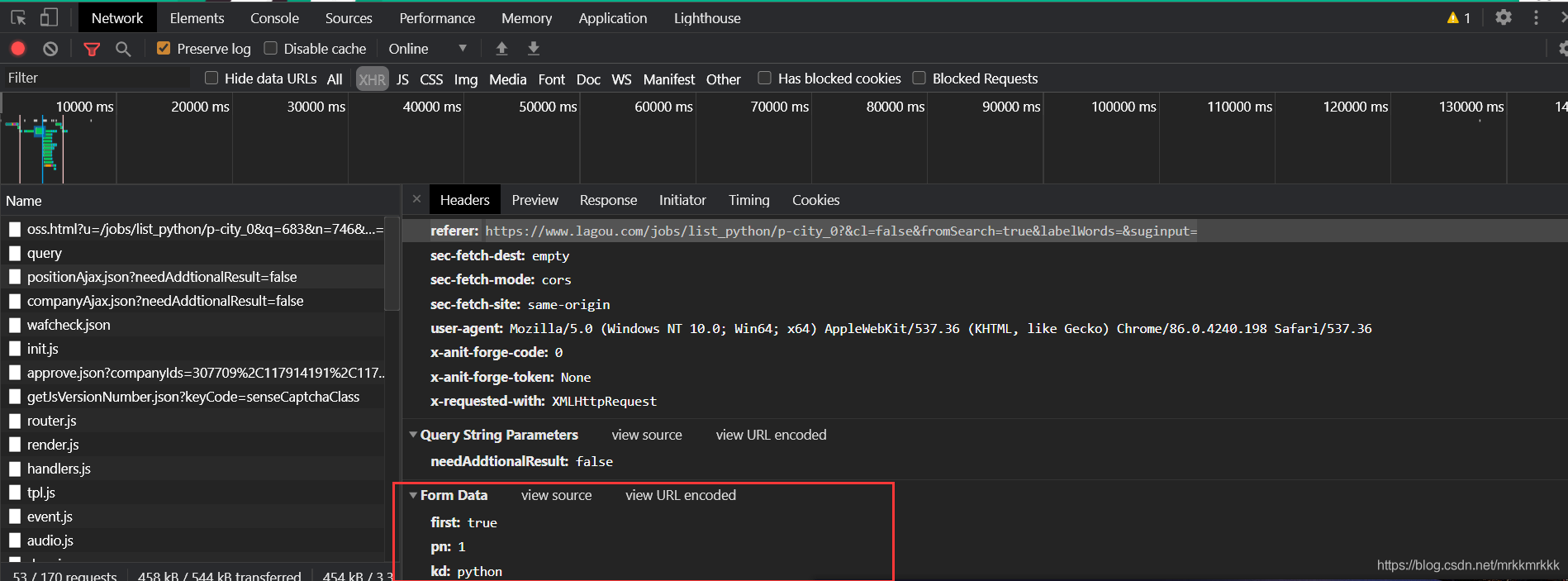
使用python构建post请求
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers)
print(res.text)
发现没有从接口获取到数据

换了个网络后接口还是会返回操作频繁的错误信息,仔细检查后发现这个接口需要一个动态的cookies不然会一值返回错误频繁
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
#头部中必须有user-agent和referer不然不会返回cookies
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#通过访问主页获取cookies
r1= requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='",headers=headers)
#再post请求中传入cookies
r2 = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers, cookies=r2.cookies)
print(r2.text)
注意!每请求十次接口cookies也会刷新一次,下面贴上完整爬虫代码
import json
import logging
import requests
#获取cookie
def getCookie():
res = requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=",
headers=headers)
return res.cookies
#获取json数据
def getPage(i, cookies, kw):
data = {
'first': 'true',
'pn': i,
'kd': kw
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,
headers=headers, cookies=cookies)
return json.loads(res.text)
#合并列表
def reduceList(l):
text = ""
for i in l:
text += i + " "
return text.strip()
#提取字段并保存到文件中
def saveInCsv(f, data):
js = data["content"]["positionResult"]["result"]
for node in js:
# 对空值进行处理
district = node["district"]
if district != None:
district = "-" + district
else:
district = ""
f.write(
node["positionName"] + "·" + node["city"] + district + "·" + node[
"salary"] + "·" +
node["workYear"] + "·" + node["education"] + "·" + reduceList(node["skillLables"]) + "·" +
node["companyShortName"] + "·" + node["companySize"] + "·" + node["positionAdvantage"] + "\n")
if __name__ == '__main__':
#定义头部
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#初始化cookie
cookies = getCookie()
with open("file.csv", "w", encoding="utf-8") as f:
for i in range(1, 31):
#每十个请求重新获取cookie
if (i % 10 == 0):
cookies = getCookie()
#解析字段并存储
data = getPage(i, cookies, "python")
saveInCsv(f, data)
加载全部内容