python调用有道智云API实现文件批量翻译
程序媛Danny 人气:0最近工作过程中,需要对一批文件进行汉译英的翻译,对单个文档手工复制、粘贴的翻译方式过于繁琐,考虑到工作的重复性和本人追求提高效率、少动手(懒),想通过调用已有的接口的方法,自己实现一个批量翻译工具,一劳永逸。在网上找了几款翻译API,通过对比翻译的结果和学习成本,选择了有道智云的服务,自己开发了一个批量翻译的小软件。详细记录一下使用和开发过程,后面的小伙伴们有相关需求,可以参考。
批量文档翻译工具的使用
我这里开发批量文档翻译工具使用python作为开发工具,功能如下:
1)通过文件夹选择多个文档;
2)可以将多个文档的翻译结果存到目标文件夹下。
话不多说,看图↓↓↓↓↓

部分翻译结果展示(涉及工作内容的保密性,这里用荷塘月色作为样例):

开发过程
下面开始详细介绍调用有道智云API接口的步骤和软件开发的过程:
1、个人开发者账号注册
首先,需要注册个人的开发者账号。
在官网点击注册,然后填写个人资料。即可完成注册,官网地址:http://ai.youdao.com/gw.s
2、 创建应用和实例
注册成功并登录后个人中心页面如下图,有道智云提供了自然语言翻译、文字识别、语音合成、语音测评等服务接口。 这些服务接口都是通过以实例的方式运行的,通过应用进行管理的。需要分别创建实例、创建应用,通过应用获取应用ID和应用密钥等信息。
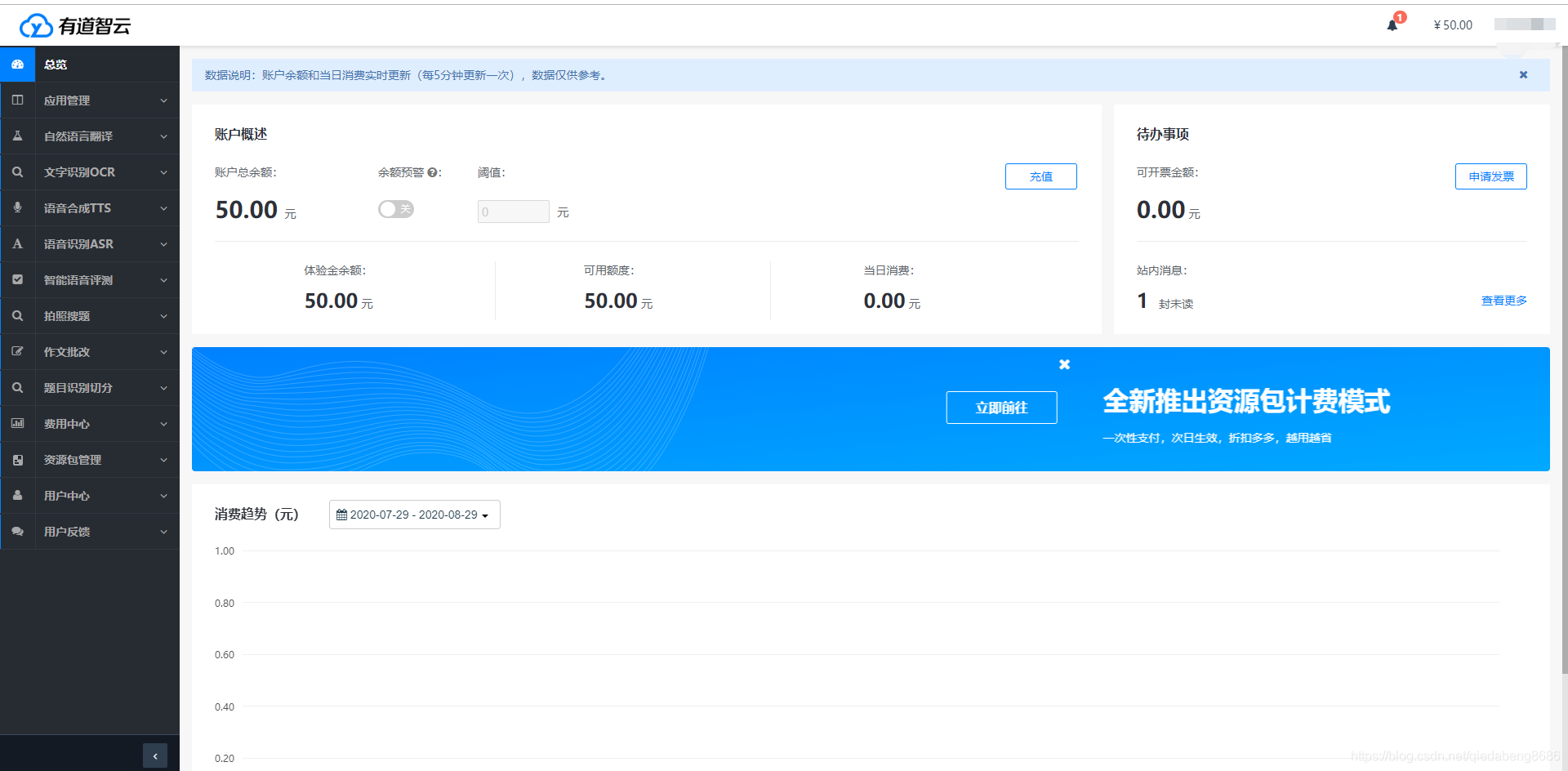
我这里用到的是自然语言翻译服务,首先,需要分别创建一个应用、创建一个自然语音翻译的实例;其次,需要将实例绑定到应用上。最后,就可以通过应用的应用ID、应用密钥调用自然语音翻译api接口了。有道平台会对不同的实例、应用的使用情况进行记录、分析、收费。刚刚注册的体验者会有免费体验字数和50元的体验金哦(加客服貌似还会有额外的50元的)。
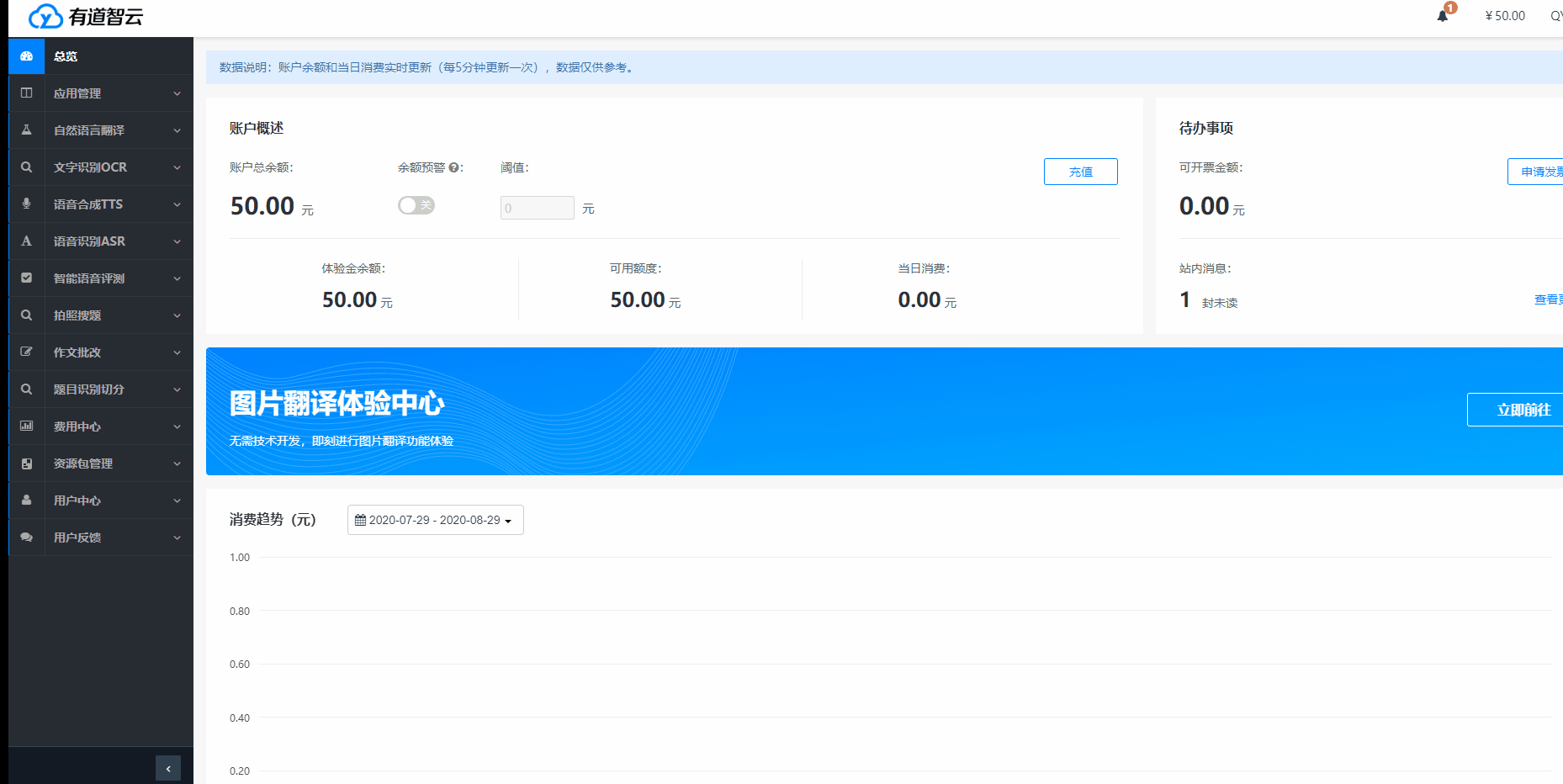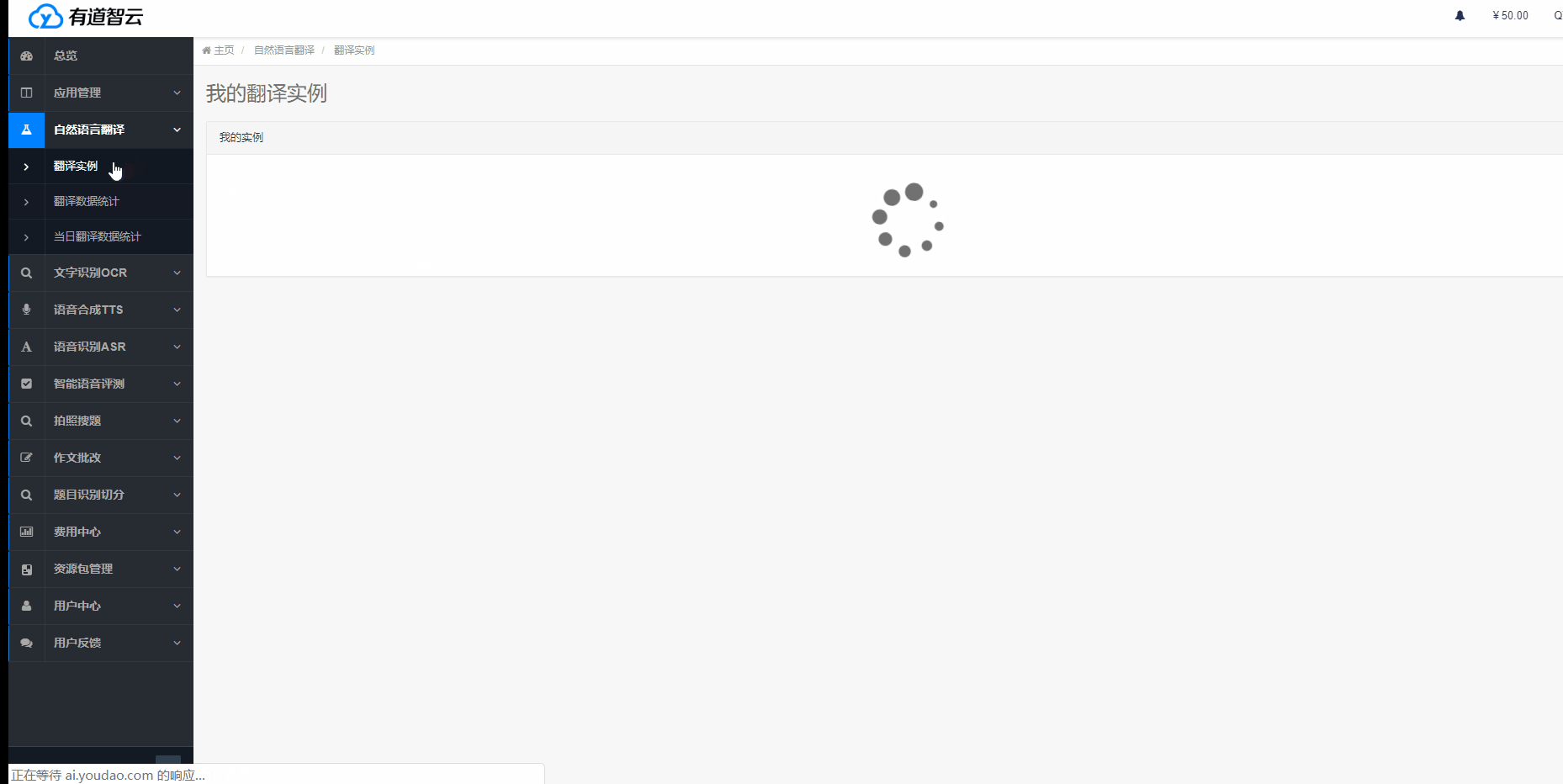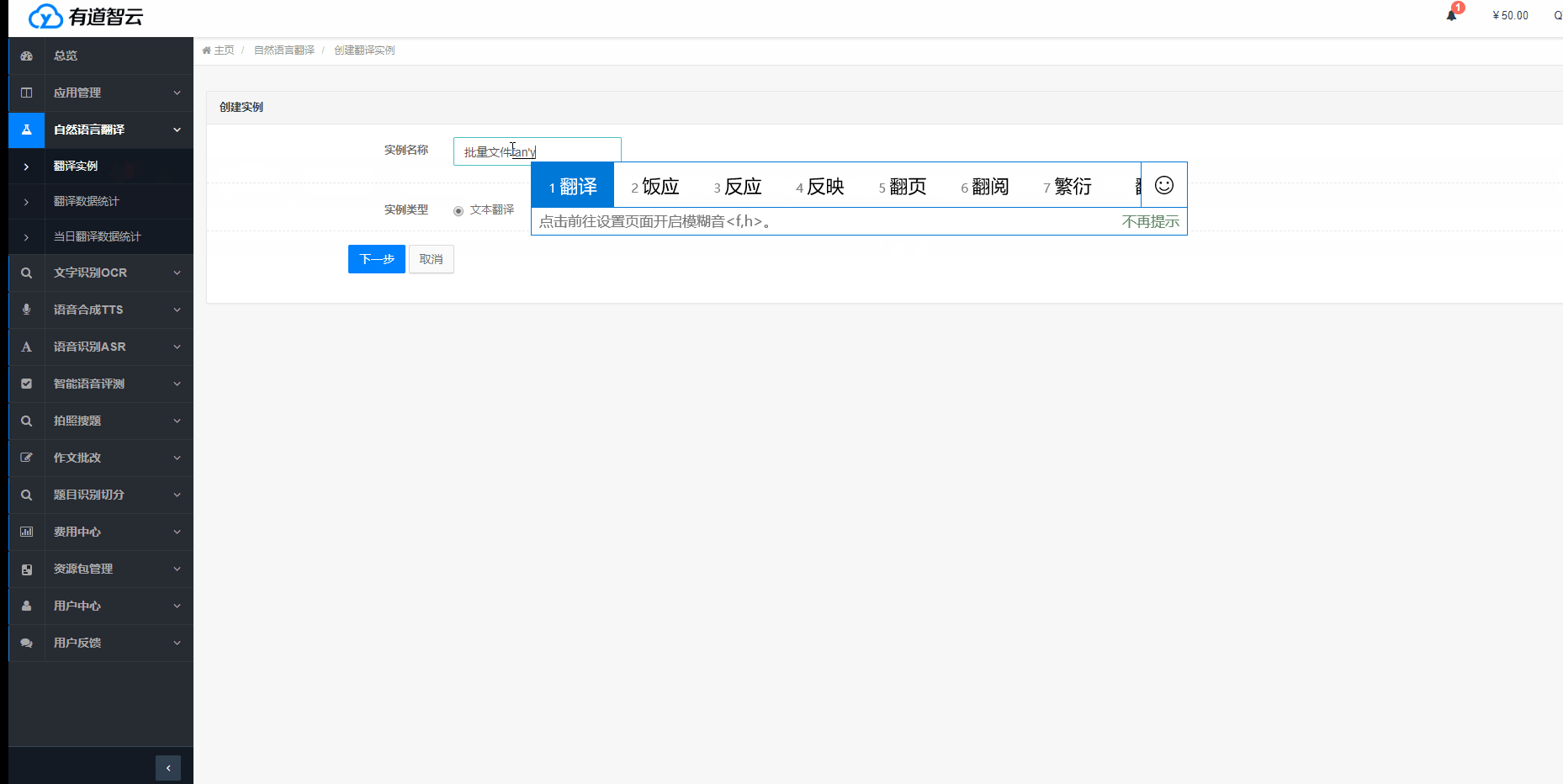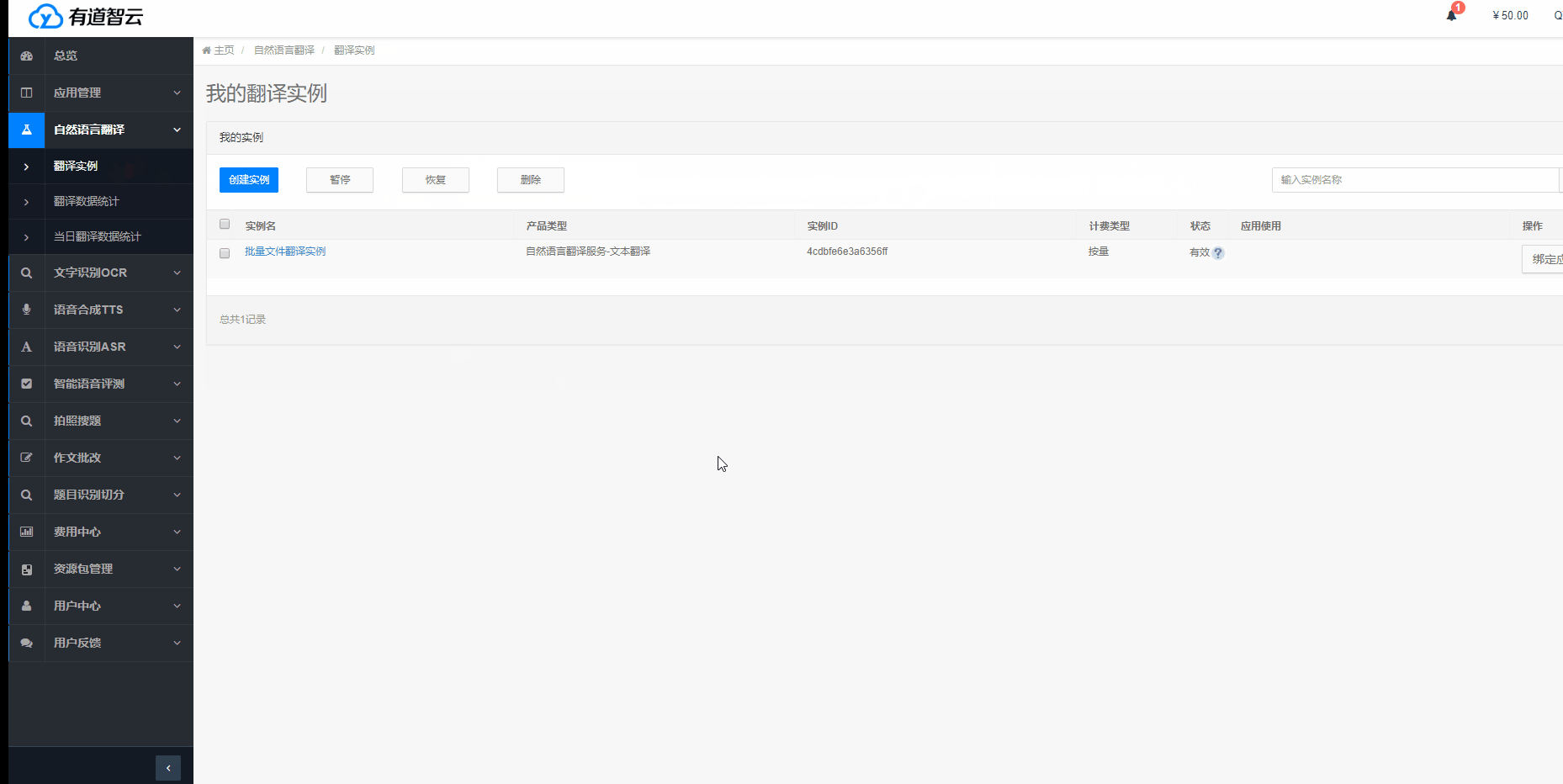
创建实例的步骤:
根据使用需求,选择对应服务(“自然语言翻译”/“文字识别OCR”/“语音合成TTS”/“语音识别ASR”/“智能语音评测”/“多平台编辑器”)->“创建实例”,按步骤完成实例创建。
创建应用并绑定实例(应用接口分为三种:API、安卓、ios接口):
点击“应用管理”->“我的应用”->“创建应用”,填写应用名称等相关信息,选择接入方式,并绑定我们所创建的实例,完成应用创建。我们这里用到的是API方式接入,安卓、ios接口需要根据提示填写相应的信息,详见官网新手指南。

应用创建成功后,可获取应用ID(appKey)和应用密钥等信息,这些信息是调用API接口必不可少的参数。
3、接口调用及代码实现
1)API接口介绍
下面介绍API接口的调用方法
文本翻译API HTTPS地址:https://openapi.youdao.com/api
调用规则:在调用集成文本翻译API时,需遵循以下规则。
| 规则 | 描述 |
|---|---|
| 传输方式 | HTTPS |
| 请求方式 | GET/POST |
| 字符编码 | 统一使用UTF-8 编码 |
| 请求格式 | 表单 |
| 响应格式 | JSON |
调用传参:调用API需要向接口发送以下字段来访问服务。
| 字段名 | 类型 | 含义 | 必填 | 备注 |
|---|---|---|---|---|
| q | text | 待翻译文本 | True | 必须是UTF-8编码 |
| from | text | 源语言 | True | 参考下方 支持语言 (可设置为auto) |
| to | text | 目标语言 | True | 参考下方 支持语言 (可设置为auto) |
| appKey | text | 应用ID | True | 可在 应用管理 查看 |
| salt | text | UUID | True | UUID |
| sign | text | 签名 | True | sha256(应用ID+input+salt+curtime+应用密钥) |
| signType | text | 签名类型 | True | v3 |
| curtime | text | 当前UTC时间戳(秒) | true | TimeStamp |
| ext | text | 翻译结果音频格式,支持mp3 | false | mp3 |
| voice | text | 翻译结果发音选择 | false | 0为女声,1为男声。默认为女声 |
| strict | text | 是否严格按照指定from和to进行翻译:true/false | false | 如果为false,则会自动中译英,英译中。默认为false |
签名生成方法如下:
signType=v3;
sign=sha256(应用ID+input+salt+curtime+应用密钥);
其中,input的计算方式为:input=q前10个字符+q长度+q后10个字符(当q长度大于20)或input=q字符串(当q长度小于等于20);
返回结果格式:返回的结果是json格式,具体说明如下:
| 字段名 | 类型 | 含义 | 备注 |
|---|---|---|---|
| errorCode | text | 错误返回码 | 一定存在 |
| query | text | 源语言 | 查询正确时,一定存在 |
| translation | Array | 翻译结果 | 查询正确时,一定存在 |
| basic | text | 词义 | 基本词典,查词时才有 |
| web | Array | 词义 | 网络释义,该结果不一定存在 |
| l | text | 源语言和目标语言 | 一定存在 |
| dict | text | 词典deeplink | 查询语种为支持语言时,存在 |
| webdict | text | webdeeplink | 查询语种为支持语言时,存在 |
| tSpeakUrl | text | 翻译结果发音地址 | 翻译成功一定存在,需要应用绑定语音合成实例才能正常播放 否则返回110错误码 |
| speakUrl | text | 源语言发音地址 | 翻译成功一定存在,需要应用绑定语音合成实例才能正常播放 否则返回110错误码 |
| returnPhrase | Array | 单词校验后的结果 | 主要校验字母大小写、单词前含符号、中文简繁体 |
当返回的结果errorCode为 0 时说明调用成功,不为0时,则会出现不同含义的错误码。详细含义可查阅官方开发文档。
2)批量文档翻译开发
批量翻译demo使用python3实现,为了方便测试,我用tkinter做了简单的界面,用来读取待翻译文档,指定结果存储路径,为了最大化简化开发过程,降低测试的时间成本,目前只实现了读取.txt类型文件的方法。
整个demo分为三个文件,mainwindow.py,translate.py和translatetool.py,mainwindow为UI部分的代码,translate中实现了批量读取文档并翻译保存的逻辑,translatetool为根据示例代码改造后的翻译方法,需调用其他平台API时,亦可封装相应方法,增加了项目的扩展性。
mainwindow的元素如下:
root=tk.Tk()
root.title("netease youdao translation test")
frm = tk.Frame(root)
frm.grid(padx='50', pady='50')
btn_get_file = tk.Button(frm, text='选择待翻译文件', command=get_files)
btn_get_file.grid(row=0, column=0, ipadx='3', ipady='3', padx='10', pady='20')
text1 = tk.Text(frm, width='40', height='10')
text1.grid(row=0, column=1)
btn_get_result_path=tk.Button(frm,text='选择翻译结果路径',command=set_result_path)
btn_get_result_path.grid(row=1,column=0)
text2=tk.Text(frm,width='40', height='2')
text2.grid(row=1,column=1)
btn_sure=tk.Button(frm,text="翻译",command=translate_files)
btn_sure.grid(row=2,column=1)
其中translate_files()方法最终调用了translate类的translate_files()方法:
def translate_files():
if translate.file_paths:
translate.translate_files()
tk.messagebox.showinfo("提示","搞定")
else :
tk.messagebox.showinfo("提示","无文件")
类translate定义如下:
import os from translatetool import connect class Translate(): def __init__(self,name,file_paths,result_root_path,trans_type): self.name=name self.file_paths=file_paths # 待翻译文件路径 self.result_root_path=result_root_path # 翻译结果存储路径 self.trans_type=trans_type # 翻译过程:读取文件-掉用有道api-解析返回信息-保存 def translate_files(self): for file_path in self.file_paths: file_name=os.path.basename(file_path) file_content=open(file_path,encoding='utf-8').read() trans_reult=self.translate_use_netease(file_content) resul_file=open(self.result_root_path+'/result_'+file_name,'w').write(trans_reult) def translate_use_netease(self,file_content): result=','.join(connect(file_content,'zh-CH','EN')) # 翻译API返回结果为一个数组 return result
调用有道API主要方法为connect(),根据API的签名信息等要求组成data并发送请求,解析返回的json:
# input输入待翻译字段,fromlanguage待翻译的语言,tolanguage翻译成的目标语言
# 返回翻译的字段
def connect(inputtext,fromlanguage,tolanguage):
q=inputtext
data = {}
data['from'] = fromlang
data['to'] = tolang
data['signType'] = 'v3'
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['q'] = q
data['salt'] = salt
data['sign'] = sign
print(data)
response = do_request(data)
print(response.content)
j = json.loads(str(response.content, encoding="utf-8"))["translation"]
return j
完整demo代码地址:https://github.com/LemonQH/BatchFileTraslationProgram/tree/master
得益于API的学习成本之低,接口调用部分的开发过程十分顺利,仅有一个小插曲,最开始调用API总是返回错误码206(即时间戳错误),最后发现是我的系统时间比标准时间慢了十分钟 - - #
总结
对于我此次的需要翻译的文档需求来说,有道智云赠送的字数和账户额度,已经够用了,但是如果想长期的使用下去,还是要付费的。最后发现,有道智云在个人主页中还提供了按小时统计当日实例调用次数和查询字符数和按天统计历史天数内实例的调用次数和字符数,对有需求的小伙伴,还可以记录查看自己接口的翻译量、实时调用量等状态。
如上是我整个demo的开发过程。整体来说从注册到调用有道智云API的过程还是比较顺利的,而且每一步都有官方的详细文档可以参照。以至于主要开发时间都分配给了tkinter排版(顺便吐槽下tkinter的“好用” :p)。
加载全部内容