nlp模型中的编码语言知识
人气:0This article is authored by Keyur Faldu and Dr. Amit Sheth
本文由 Keyur Faldu 和 Amit Sheth博士 撰写
Modern NLP models (BERT, GPT, etc) are typically trained in the end to end manner, carefully crafted feature engineering is now extinct, and complex architectures of these NLP models enable it to learn end-to-end tasks (e.g. sentiment classification, question answering, etc.) without specifying the features explicitly [2]. Linguistic features (like part-of-speech, co-reference, etc) have played a key role in the classical NLP. Hence, it is important to understand how modern NLP models are arriving at decisions by “probing” into what all they learn. Do these models learn linguistic features from unlabelled data automatically? How can we interpret the capabilities of modern NLP models? Lets probe.
现代的NLP模型(BERT,GPT等)通常以端到端的方式进行训练,现在精心制作的特征工程已经不存在了,这些NLP模型的复杂体系结构使它能够学习端到端的任务(例如情感分类,问题回答等),而无需明确指定功能[2]。 语言特征(如词性,共指等)在经典NLP中起着关键作用。 因此,重要的是要了解现代NLP模型如何通过“ 探究 ”他们所学的知识来做出决策。 这些模型是否自动从未标记的数据中学习语言功能? 我们如何解释现代NLP模型的功能? 让我们探讨一下 。
语言学:背景 (Linguistics: The Background)
Linguistic knowledge is an essential aspect of natural language processing. We can think of it in the following dimensions,
语言知识是自然语言处理的重要方面。 我们可以从以下几个方面来思考:
Syntax: analyzing the structure of sentences and the way words are connected.
语法 :分析句子的结构和单词的连接方式。
Morphology: deals with the inner structure of individual words and how new words are formed from morphs of these base words.
形态 :处理单个单词的内部结构以及这些基本单词的变体如何形成新单词。
Phonology: the study of the system of sounds comprising speech, that constitute fundamental components of language.
语音学 :对构成语音的声音系统的研究,语音构成语言的基本组成部分。
Semantics: deals with the meaning of individual words and entire texts.
语义 :处理单个单词和整个文本的含义。
In statistical methods and classical machine learning, solving any problem related to natural language processing involves deriving linguistic knowledge described above. Thus, the research community gave attention to numerous tasks related to linguistic knowledge. We can see a few examples as below:
在统计方法和经典机器学习中,解决与自然语言处理有关的任何问题都涉及派生上述语言知识。 因此,研究界对与语言知识有关的许多任务给予了关注。 我们可以看到一些示例,如下所示:
Part-of-speech: Syntactic category of words, i.e., noun, verb, adjective, pronoun, etc.
词性 :词的句法类别,即名词,动词,形容词,代词等。
Constituency Trees (or phrase structure grammar): Phrase structure rules consider that sentence structure is constituency-based, and a parse tree arranges these constituents in a tree structure with constituency relation.
选区树 (或短语结构语法):短语结构规则认为句子结构是基于选区的,而解析树将这些组成部分安排在具有选区关系的树结构中。
Dependency Trees (or dependency grammars): Dependency grammar rules consider that sentence structure is dependency-based, and the dependency parse tree arranges words in a tree structure with dependency relation.
依赖关系树 (或依赖关系语法):依赖关系语法规则认为句子结构是基于依赖关系的,并且依赖关系分析树以具有依赖关系的树结构排列单词。
Coreference: Relationship between two words or phrases with the common referent.
共指 :两个词或短语与一般所指的关系。
Lemmatization: Deriving base lemma word after removing prefixes or suffixes using morphological analysis.
词形还原 :使用形态学分析去除前缀或后缀之后推导基引理字。
Above are a few examples of important tasks related to linguistic knowledge, where part-of-speech mainly deals with syntactic knowledge, dependency trees, and co-references are important to further understand semantics, and lemmatization is an example of morphology.
上面是与语言知识有关的重要任务的一些示例,其中词性主要处理语法知识,依存关系树和共指对进一步理解语义很重要,而词形化是形态的一个示例。
Numerous other tasks further analyze the linguistic properties of a sentence, like semantic roles, semantic proto-roles, relation classification (lexical and semantic), subject noun, main auxiliary verb, subject-verb agreement, etc.
许多其他任务进一步分析了句子的语言属性,例如语义角色,语义协议,关系分类(词汇和语义),主语名词,主要助动词,主语-动词一致等。
现代NLP模型 (Modern NLP Models)
Modern NLP models are either LSTM based or transformer based. ELMO and ULMFIT are examples of LSTM architecture based language models. In contrast, BERT [1] and GPT are examples of transformers architecture based language models. For the rest of the study, let’s take an example of “BERT” as a reference.
现代的NLP模型基于LSTM或基于变压器。 ELMO和ULMFIT是基于LSTM体系结构的语言模型的示例。 相反,BERT [1]和GPT是基于变压器体系结构的语言模型的示例。 在其余的研究中,我们以“ BERT”为例进行参考。
- The BERT model is pre-trained with an objective of masked word prediction, and next sentence prediction on massive unlabeled data. 对BERT模型进行预训练,其目标是对大量未标记数据进行掩盖字词预测和下一句话预测。
- The pre-trained BERT model is fine-tuned by extending it with the task-specific layers for tasks like ‘sentiment analysis,’ ‘text classification,’ or ‘question answering’ with limited labeled data. 预训练的BERT模型可以通过在特定任务层上扩展以适应诸如有限的标记数据的“情感分析”,“文本分类”或“问题回答”等任务来进行微调。
Representations produced by the pre-trained BERT models encode relevant information, which enables task-specific fine-tuning with very limited labeled data. The question is,
预训练的BERT模型产生的表示对相关信息进行编码,从而可以使用非常有限的标记数据进行特定于任务的微调。 问题是,
BERT编码什么语言知识? (What Linguistic Knowledge is Encoded in BERT?)

As a result, a flurry of research sought to understand what kind of linguistic information is captured in neural networks. The most common theme across different approaches can be grouped as “probes” (or probing classifiers, diagnostic classifiers, auxiliary prediction tasks), which probes how internal mechanisms of neural networks can classify (or perform on) auxiliary linguistic tasks (or probe tasks).
结果,一系列的研究试图了解在神经网络中捕获了哪种语言信息。 跨不同方法的最常见主题可以归为“探针 ”(或探针分类器,诊断分类器,辅助预测任务),该探针探讨神经网络的内部机制如何对辅助语言任务(或探针任务)进行分类(或执行) 。
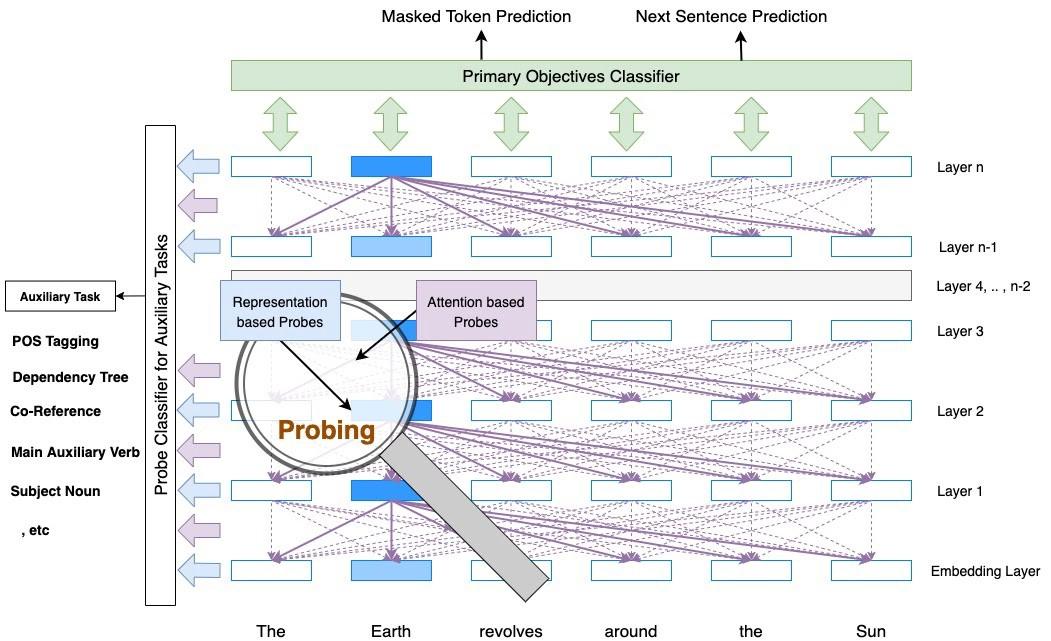
“探针”如何工作? (How do “Probes” work?)
Probing is an approach to investigate how a model (and its components) trained on the primary objective performs on some different auxiliary tasks. Typically, a model is extended with a classifier layer to transform its representations according to auxiliary task output space. Probing facilitates a better understanding of encoded representations.
探测被调查的模型(及其组件)如何在训练的主要目标进行了一些不同的辅助任务的方法。 通常,模型通过分类器层进行扩展,以根据辅助任务输出空间来转换其表示。 探测有助于更好地理解编码表示。
- Let say, we want to investigate if encoded representations from the BERT model capture linguistic information, like “if a verb is an auxiliary verb” or “if a phrase is a subject noun”. Auxiliary verbs are the helping verbs, and subject nouns are noun phrases that act as a subject. These tasks can be framed as “auxiliary tasks” for probes. 假设我们要研究的是BERT模型的编码表示形式是否捕获语言信息,例如“如果动词是辅助动词”或“如果短语是主语名词”。 辅助动词是帮助动词,主语名词是充当主语的名词短语。 这些任务可以被构造为探针的“辅助任务”。
For example, in the sentence “Kids are playing cricket all day,” — “are” is an auxiliary verb, “playing” is the main verb, “Kids” is the subject noun, and “Cricket” is an object noun
例如,在“孩子们整天都在打板球”的句子中,“- ” 是辅助动词,“ playing ”是主要动词,“ Kids ”是主名词,“ Cricket ”是宾语。
- Probing classifiers can be attached to models at different layers. That would give insights about what layers of the BERT model capture how much information being sought as an auxiliary task. 探测分类器可以附加到不同层的模型。 这将提供有关BERT模型的哪些层捕获作为辅助任务正在寻求多少信息的见解。
- If a probe classifier is not able to do well on auxiliary task for linguistic information, that means such information is not encoded in internal representations of a model, also possible because it might not be needed to solve primary objectives of the model. 如果探针分类器不能很好地完成语言信息的辅助任务,则意味着此类信息未编码在模型的内部表示中,这也是可能的,因为可能不需要解决模型的主要目标。
“探针”与微调或多任务学习有何不同? (How are “Probes” different from Fine-Tuning or Multi-Task Learning?)
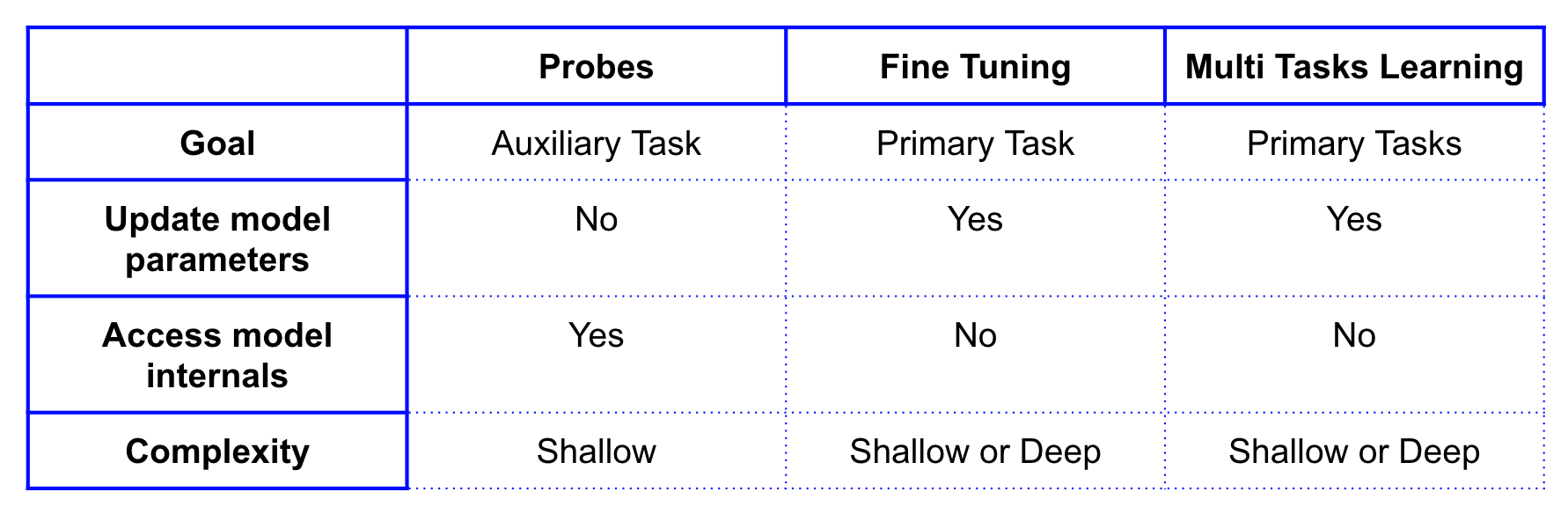
“Probes” are not related to fine-tuning for downstream tasks neither in its goal nor in approach.
“探头” 不相关的微调下游任务既不是其目标也不是办法。
- Table 1 shows the comparative landscape. 表1显示了比较情况。
- “Probes” are to discover encoded linguistic knowledge, whereas fine-tuning and multi-tasks learning trains the model on one or multiple primary tasks. “探针”用于发现编码的语言知识,而微调和多任务学习则可以在一个或多个主要任务上训练模型。
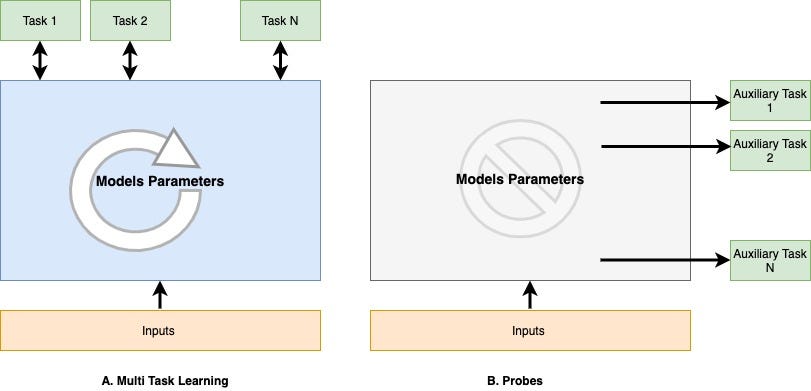
- As illustrated in figure 4, “Probes” can access model internals but can not update model parameters, on the other hand, fine-tuning and multi-tasks learning does not access model internals, but they can update model parameters. 如图4所示,“ Probes”可以访问模型内部,但不能更新模型参数,另一方面,微调和多任务学习不能访问模型内部,但是它们可以更新模型参数。
- “Probes” should be shallow in terms of complexity, (i.e. a single layer classifier on top of the model), whereas fine-tuning and multi-task learning can stack up deep layers depending upon the downstream tasks complexity [7][8]. 就复杂性而言,“探针”应该浅一些(即,模型顶部的单层分类器),而微调和多任务学习则可以根据下游任务的复杂性堆叠更深的层次[7] [8]。 。
什么是“探针”的不同类型? (What are Different Types of “Probes”?)
These probing classifiers can be categorized based on what neural network mechanisms they are leveraging to probe for the linguistic knowledge. These are mainly
这些探测分类器可以基于它们利用何种神经网络机制来探究语言知识进行分类。 这些主要是
Internal Representations: A small probe classifier is built on top of internal representations from different layers to analyze what linguistic information is encoded at different layers.
内部表示:一个小型探针分类器建立在来自不同层的内部表示之上,以分析在不同层上编码的语言信息。
Attention weights: Probe classifiers are built on top of attention weights to discover if there is an underlying linguistic phenomenon in attention weights patterns.
注意权重:探针分类器建立在注意权重之上,以发现注意权重模式中是否存在潜在的语言现象。
(A)基于“代表”的内部表示: ((A) Internal Representations based “Probes”:)
Quite a few techniques are probing how much linguistic knowledge is encoded in internal representation at different layers of models like BERT. Let’s take a look at a couple of examples.
相当多的技术正在探索在不同模型(例如BERT)的内部表示形式中编码了多少语言知识。 让我们看几个例子。
(A.1) Edge Probing: A framework introduced by Tenney et al. [4][5] aims to probe linguistic knowledge encoded in contextualized representations of a model.
(A.1)边缘探测: Tenney等人介绍的框架。 [4] [5]旨在探究以模型的上下文表示形式编码的语言知识。
- For auxiliary tasks like Part-of-Speech, Constituents, Dependencies, Entities, Semantic Role Labelling, Semantic Proto Roles, and Coreference resolutions, it has compared the performance of contextualized representations of models like BERT, GPT, ELMO, and CoVe. 对于诸如词性,成分,依赖关系,实体,语义角色标签,语义原型角色和共指解析等辅助任务,它比较了诸如BERT,GPT,ELMO和CoVe等模型的上下文表示的性能。
- Edge probing decomposes structured-prediction tasks into a common format, where a probing classifier receives a text span (or two spans) from the sentence and must predict a label such as a constituent or relation type, etc. from per-token embeddings for tokens within those target spans. 边缘探测将结构化预测任务分解为一种通用格式,其中探测分类器从句子中接收一个文本跨度(或两个跨度),并且必须根据令牌的每个令牌嵌入来预测诸如构成或关系类型之类的标签在这些目标范围内。
The macro average of performance overall the auxiliary tasks for the BERT-Large model was 87.3, whereas the baseline probe using non-contextualized representations achieved 75.2. So, about 20% of additional linguistic knowledge was injected into as part of contextualization.
总体上,BERT-Large模型的辅助任务的总体性能宏平均值为87.3,而使用非上下文表示形式的基线探测则达到75.2 。 因此,作为语境化的一部分,大约有20%的额外语言知识被注入。
(A.2) BERT Rediscovers the Classical NLP Pipeline: Tenny et al. [3][9] further analyzed where linguistic knowledge comes from.
(A.2)BERT重新发现了经典的NLP管道 :Tenny等。 [3] [9]进一步分析了语言知识的来源。
Center of Gravity: Center of gravity reflects the average layer attended to compute scalar mixing (weighted pooling) of internal representations at different layers. For each task, intuitively, we can interpret a higher center of gravity means that the information needed for that task is captured by higher layers.
重心:重心反映了用于计算不同层内部表示的标量混合(加权池)的平均层。 对于每个任务,我们可以直观地解释更高的重心,这意味着该任务所需的信息被更高的层捕获。
Expected layer: Probe classifier is trained with the scalar mixing of internal representations of different layers. Contribution (or differential score) of layer i is computed by taking the difference of “performance of probe trained with layers 0 to i” with “performance of probe trained with layer 0 to i-1”. The expected layer is the expectation of differential score over each layer.
预期层:探针分类器是通过不同层内部表示的标量混合进行训练的。 贡献(或差分得分)层的i由取的差来计算与“ 使用层0至i训练探针的性能 ”,“ 探针与层0的训练性能至i-1”。 预期层是每个层上差异分数的期望。
- In figure 5, row labels are auxiliary tasks for probing linguistic knowledge. F1 scores for probe classifiers for each task are mentioned in the first two columns, where l=0, indicates auxiliary tasks performance on non-contextual representations, and l=24 indicates auxiliary tasks performance by mixing contextual representations from all 24 layers of the BERT model. Expected layers are shown in purple color (and the center of gravity is shown in dark blue color). 在图5中,行标签是探测语言知识的辅助任务。 在前两列中提到了针对每个任务的探针分类器的F1分数,其中l = 0表示在非上下文表示中的辅助任务性能,l = 24通过混合BERT的所有24层的上下文表示来表示辅助任务性能模型。 预期的图层以紫色显示(重心以深蓝色显示)。
- The expected layer is where the maximum additional linguistic knowledge comes from. And, it can be seen that linguistic knowledge about syntactic tasks gets acquired in initial layers, and for semantic tasks gets acquired in later layers. 预期层是最大的额外语言知识所来自的地方。 并且,可以看出,关于语法任务的语言知识是在初始层中获得的,而关于语义任务的语言知识是在较后层中获得的。
(B)基于“探针”的注意力权重: ((B) Attention weights based “Probes”:)
“What Does BERT Look At? An Analysis of BERT’s Attention,” Clark et al. [2] probe attention weights for linguistic knowledge in BERT. It was intriguing to notice how specific attention heads are expressing linguistic phenomena, and attention heads combinations predict linguistic tasks such as dependency grammar that is comparable to the state of the art performance.
“ BERT看什么? BERT的注意力分析”,Clark等。 [2]探讨BERT中语言知识的注意力权重。 有趣的是,特定的关注头是如何表达语言现象的,而关注头的组合预测的语言任务(例如依存语法)可与最新的技术水平相提并论。
(B.1) Specific Attention Heads
(B.1)具体的注意头
- As can be seen in figure 6, specific attention heads in BERT express specific linguistic phenomena, where a token attends other tokens depending on the linguistic relation expressed by the attention head. 如图6所示,BERT中的特定注意头表示特定的语言现象,其中一个标记与其他标记相关,取决于该注意头表示的语言关系。
- Visualizations of six different attention heads are shown above. The BERT base model has 12 layers, and each layer has 12 attention heads. The top-left plot in figure 5 represents the 10th attention head in the 8th layer. And the patterns where objects are attending to their nouns are evident. Similarly, in the 11th attention head of the 8-th layer, noun modifiers (determiners, etc.) are attending to their nouns. Similarly, we can notice how attention heads in other plots are expressing linguistic knowledge. 上面显示了六个不同的关注头的可视化。 BERT基本模型有12层,每层有12个关注头。 图5的左上图表示第8层中的第10个关注头。 而且对象在其名词上的出现方式也很明显。 同样,在第8层的第11注意头中,名词修饰语(确定符等)也伴随着它们的名词。 同样,我们可以注意到其他情节中的关注头如何表达语言知识。
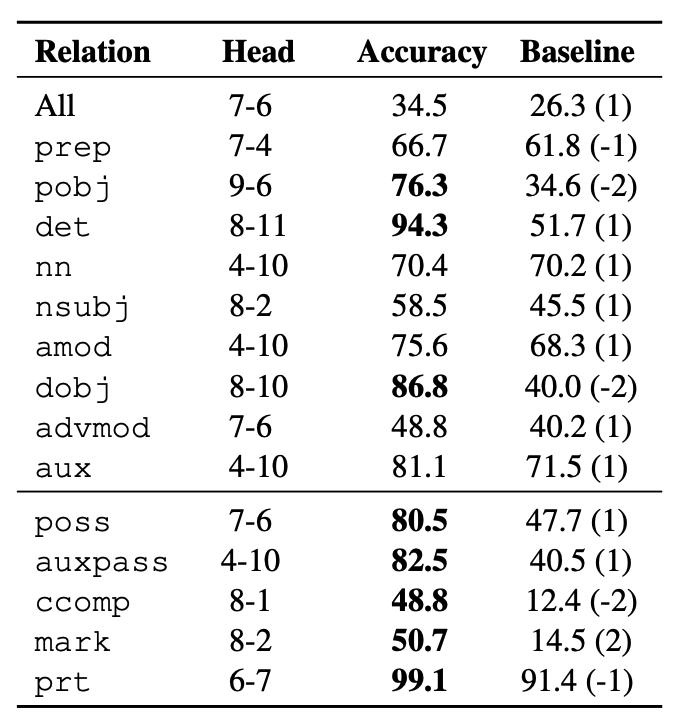
- It is really surprising to notice how attention heads perform as readily available probe classifiers. 真是令人惊讶地注意到,关注头作为随时可用的探针分类器的性能如何。
A figure, shows for each dependency relationship, how a specific attention head achieves classification performance of predicting dependent token. For cases like determinant (det), direct object (dobj), possessive word (poss), passive auxiliary (auxpass), etc performance gain was huge compared to the baseline model (predicting a token at the best fixed offset).
一张图显示了每个依赖关系,特定的关注头如何实现预测依赖标记的分类性能。 对于行列式(det),直接对象(dobj),所有格词(poss),被动辅助(auxpass)等情况,与基线模型相比,性能增益是巨大的(预测最佳固定偏移量的令牌)。
(B.2) Attention Head Combinations
(B.2)注意头组合

- Probe classifiers trained on directly taking linear combinations of attention weights, and attention weights with non-contextual embeddings like GloVe, gave a comparable performance to relatively complex models depending on internal contextual representations for dependency parsing tasks. 经过训练的探针分类器直接采用注意力权重的线性组合以及具有非上下文嵌入的注意力权重(例如GloVe),根据依赖项解析任务的内部上下文表示,其性能可与相对复杂的模型相媲美。
- Similarly, experiments on coreference, resolution tasks also suggested similar potential. That said, we can conclude that attention mechanisms in BERT also encode and express linguistic phenomena. 同样,关于共指,解决任务的实验也表明了类似的潜力。 就是说,我们可以得出结论,BERT中的注意力机制也可以编码和表达语言现象。
探索“探针” (Probing the “Probes”)
Now that we got introduced to representation based probes and attention weights based probes to discover the encoded linguistic knowledge using auxiliary tasks, it would be interesting to ask deeper questions:
既然我们已经介绍了基于表示的探针和基于注意力权重的探针,以使用辅助任务发现编码的语言知识,那么提出更深层次的问题将很有趣:
Are bigger models better to encode linguistic knowledge?
更大的模型更好地编码语言知识吗?
How to check for the generalization ability of a model to encode linguistic knowledge?
如何检查模型对语言知识进行编码的泛化能力?
Can we decode linguistic knowledge instead of relying on shallow probe classifier labels?
我们可以解码语言知识,而不是依赖浅层探针分类器标签吗?
What are the limitations of probes, and how to draw conclusions?
探究的局限性是什么,如何得出结论?
Can we infuse linguistic knowledge?
我们可以注入语言知识吗?
Does encoded linguistic knowledge capture meaning?
编码语言知识是否捕获含义?
Is encoded linguistic knowledge good enough for natural language understanding?
编码的语言知识是否足以使自然语言理解?
Lets elaborate further on the above questions in the next article “Analysing Encoded Linguistic Capabilities of NLP Models & Beyond”. (coming soon)
在下一篇文章“分析NLP模型的编码语言能力及以后”中,让我们进一步详细说明上述问题。 (快来了)
- Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. NAACL 2019. Devlin等。 “ BERT:为理解语言而对深度双向变压器进行的预训练”。 NAACL 2019。
Belinkov et al. “Analysis Methods in Neural Language Processing: A Survey”, ACL 2019
Belinkov等。 《神经语言处理中的分析方法:调查》 ,ACL 2019
Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning, “What Does BERT Look At? An Analysis of BERT’s Attention”, 2019
凯文·克拉克,瓦什Khandelwal,奥马尔·利维,克里斯托弗·D·曼宁, “这是什么BERT参考吗? BERT的注意力分析” ,2019年
Ian Tenney, Dipanjan Das, Ellie Pavlick, “BERT Rediscovers the Classical NLP Pipeline”, 2019
Ian Tenney,Dipanjan Das,Ellie Pavlick, “ BERT Rediscovers the Classical NLP Pipeline” ,2019年
Tenney et al. “WHAT DO YOU LEARN FROM CONTEXT? PROBING FOR SENTENCE STRUCTURE IN CONTEXTUALIZED WORD REPRESENTATIONS”, ICLR 2019
Tenney等。 “您从上下文中学到了什么? 语境化语言表达中的句子结构探究” ,ICLR 2019
Adi et al. “FINE-GRAINED ANALYSIS OF SENTENCE EMBEDDINGS USING AUXILIARY PREDICTION TASKS”, ICLR 2017
Adi等。 “使用辅助预测任务对句子嵌入进行细粒度分析” ,ICLR,2017年
Stickland et al. “BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning”, ICML 2019
Stickland等。 “ BERT和PAL:在多任务学习中有效适应的预计注意力层” ,ICML 2019
Zhou et al. “LIMIT-BERT : Linguistic Informed Multi-Task BERT”, 2019
周等。 “ LIMIT-BERT:语言告知的多任务BERT” ,2019年
翻译自: https://towardsdatascience.com/encoded-linguistic-knowledge-in-nlp-models-b9558ba90943
加载全部内容