论文浏览(49) Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos
人气:00. 前言
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:时空行为检测
- 作者单位:Google
- 发表时间:ECCV 2020
1. 要解决什么问题
- 视频分类的进展十分迅速,但时空行为检测的进展却比较一般
- 作者认为其中一个主要原因是:时空行为检测的数据标注困难较高,需要标注视频中的每一帧图像。
2. 用了什么方法
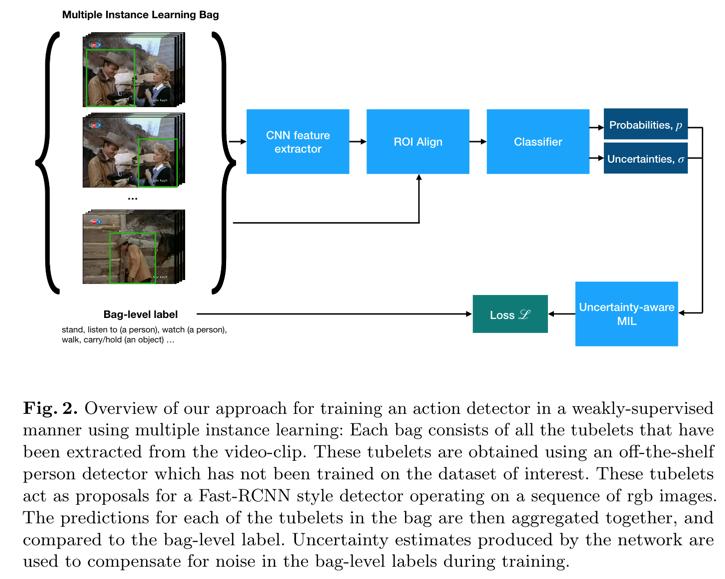
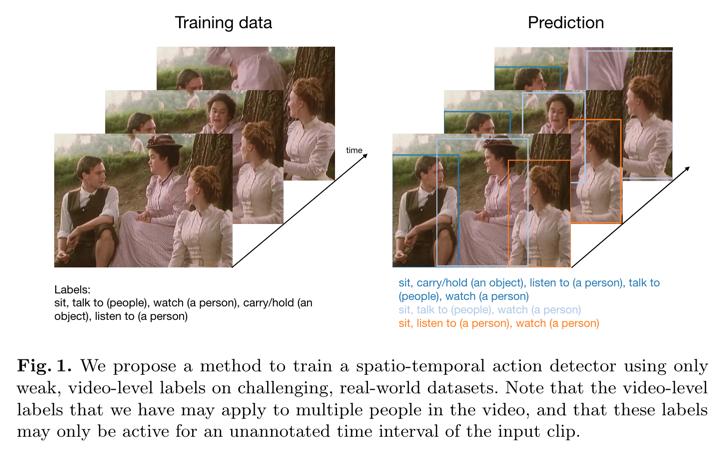
- 目标:只是用 clip-level 的标签训练时空行为检测模型。具体目标如下图:
- 使用弱监督学习的方法训练时空行为检测模型
- 主要思想是引入了 Multiple Instance Learning。
- 除了 MIL 外,其他部分的实现差不多都引用了之前的工作,比如tubelet间的link等。
- Multiple Instance Learning 的基本概念
- 假设一个bag中有多个instances,MIL的作用就是:训练时只知道bag的标签,不知道每个instance的标签,但训练结果是能够知道每个instance的标签。
- 在时空行为检测中,bag只得就是一个clip视频,instance值得就是tubelet。
- MIL的思路就是利用概率论中的方法:
- 我们要计算的是 instance level 的概率 p i j p_{ij} pij,即第i个clip中第j个instance的对于某一类别的概率。
- 这个概率值可通过神经网络获取。
- 通过 instance level 的概率可以得到 clip-level 的概率,即
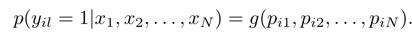
- 其中,g函数就是聚合函数,即如何从instance level的概率转换为clip level的概率,文中有一些介绍,但经过试验,起始max pool的性能是最好的。
- 得到了 clip-level 的概率后,就能通过普通的多分类来训练了。
- 为了处理 MIL 中的一些特殊情况,引入了 uncertainty loss,具体没细看。
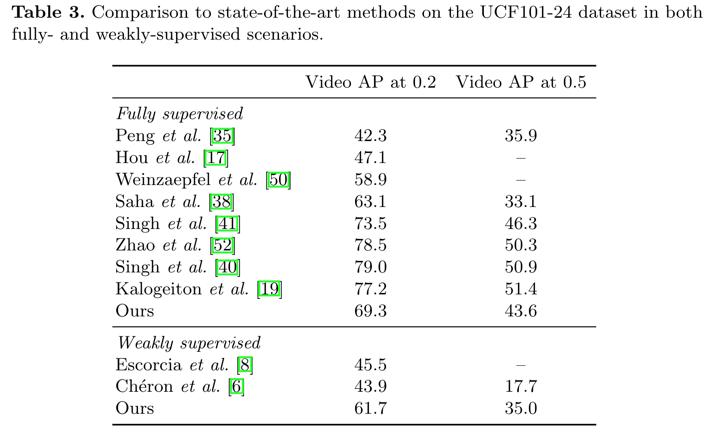
3. 效果如何
- 用弱监督学习效果都不错

4. 还存在什么问题&有什么可以借鉴
-
因为不能用于实时,所以很多问题都没有细看,比如tubelet生成是否是detector+tracker,uncertainty的实现细节是啥。
-
如果在有 clip-level 的标注结果时,可以关注这一篇。
加载全部内容
- 猜你喜欢
- 用户评论