我眼中的华为公有云AI平台--ModelArts
华为云开发者社区 人气:1前言
AWS Sagemaker has been a great deal for most data scientists who would want to accomplish a truly end-to-end ML solution——by John Moolayil
这是数据科学在线网站“towards data science”一篇文章中的一段话。时常有人问我,“为什么会有ModelArts存在”,这是一个很有价值的问题,结合国外专家对AWS Sagemaker的评价,我决定写一篇文章,讲讲我对华为云ModelArts全流程AI平台的理解。
ModelArts平台的初心
为什么不能仅仅使用开源软件构建AI训练和推理过程?答案是,可以的,但是不能用于大规模生产环境下,至于为什么我这么说,让我们先谈谈人工智能产品。我认为,如果要将人工智能技术集成到各个行业,需要有一套完整的软硬件平台支撑。
人工智能平台大致的分层架构如下图所示:
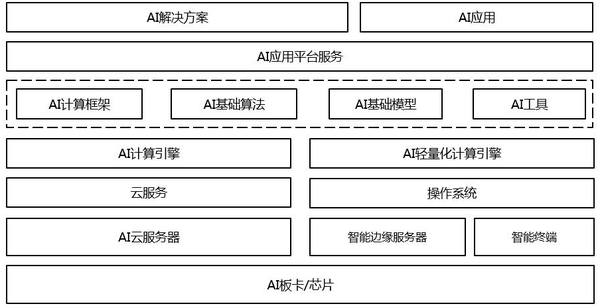
完整的人工智能平台,水平方向上支持端、边、云三种场景,每个场景均涵盖了从底层硬件至上层应用。
最底层是芯片层(例如华为的昇腾芯片、Google的TPU芯片、NVIDIA的GPU卡),再往上是适用于端边云的硬件系统(包括服务器和终端设备等)及其基础软件环境(如云服务、操作系统)。
位于这三层之上的是AI计算引擎层,AI计算引擎可以借助计算资源,完成AI模型的训练和推理。当模型训练后之后,需要部署进行推理,推理模块由于计算资源消耗较少,更容易覆盖端、边、云三个场景。
在AI计算引擎之上,人工智能平台提供了常用的AI框架、算法、模型及其其他工具方便用户进行AI业务的开展。常用的AI工具包括但不限于:数据的格式转换、预处理、模型保存、模型评估、模型压缩等等。AI框架、算法、模型和工具是解决常用AI问题时必备的组件。这些可以大大降低AI应用开发的门槛,简化开发AI应用所需的代码量。在此之上,AI应用平台服务提供AI应用的开发和部署服务,支持一次开发、任意部署(含云、边、端)。
再往上是AI应用平台服务,它提供端到端的AI应用开发和部署服务。
最顶层是基于AI应用平台服务开发出的AI解决方案和AI应用,可用于解决业务问题。
自下向上的每一层,我们可以看出,AI平台需要提供从硬件到软件、算法工具再到云服务的全栈优化,才能够真正提升AI应用开发的效率,进而使能行业AI。
ModelArts平台的初心,除了降低以上所说的各层的复杂性之外,更是为了便于用户创造AI应用。为什么AI应用有别于传统软件应用?因为目前常用的人工智能算法,大多基于概率统计,所以具有一定的不确定性和概率性。例如在图像分类场景下,任何AI模型都不可能实现100%的分类准确率。当AI模型预测一张图像类别时必须伴随着一定的概率值,这个概率值不可能达到100%,只能无限接近。而传统AI软件基本都在执行确定性的操作,不会出现概率性。这就是AI应用和传统软件应用最大的区别。
如下表所示,从产品设计、方案设计、开发、测试、上线再到运维的全生命周期的每个阶段中,传统软件应用开发和AI应用开发都有很大的区别。

初识ModelArts
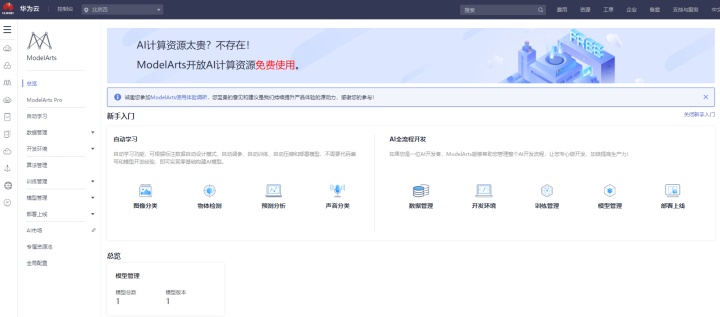
这是ModelArts的首页,有人会说为什么这么杂乱,很多功能都被平铺在了首页上?如果你换位思考,ModelArts是面向2C用户的AI平台,从完全不懂编程的小白,到精通AI开发全流程的工程师,我们要让更多人享受到AI带来的红利,我们自然需要覆盖更广的用户技能范围,所以,你看到了自动学习、AI全流程开发,这两个不同方向并排在了首页。普惠,了然于心。
进一步剖析ModelArts
了解一下AI全流程开发,如下图所示:
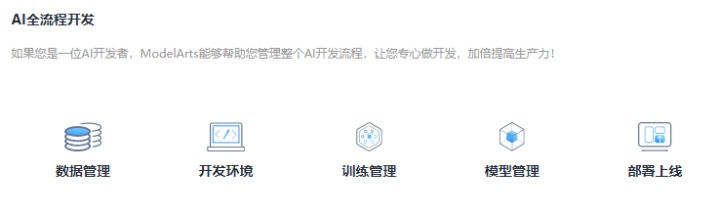
对于数据管理的理解
AI应用开发的全流程是对数据源不断地进行处理,并得到最终期望结果的过程。这个过程的每个步骤,都会基于一定的处理逻辑对输入数据进行处理,并得到输出数据,同时也可能会产生一个或多个模型,以及一些可能的元信息文件(如配置项文件等)。
在处理的过程中,可能会接受外部输入(例如用户的输入、配置、其他外部环境的输入等)。每个处理步骤的处理逻辑可以是平台内置的处理逻辑,也可以是开发者自定义的处理逻辑(例如开发者利用平台的开发调试环境开发的一套代码)。当数据源经过一系列处理之后,我们会得到最终的结果数据(例如图像识别精度等报表数据)。在这一系列的处理步骤中,可能会出现反复,例如当我们对某个处理步骤输出的数据不满意时,可以重新修正输入数据或者处理逻辑,重新进行处理,也可以跳到其他处理步骤进行进一步处理。
当前,大部分人工智能是围绕数据为中心进行开发,其中涉及到的算法往往以概率统计为基础,这些算法往往对其输入数据有非常强的先验假设(例如独立同分布等),我们需要将原始数据转换为满足这些假设的数据才能用来训练模型。
学术界对于一些常见的我们通常专注于算法的创新设计和开发,而较少地去做数据的采集、清洗、处理等工作。工业界情况恰好相反,我们需要在数据方面做非常多的工作,例如当我们需要采用机器学习分类算法解决一个具体业务问题时,数据来源可能是多方面的,可能是在本地存储的某些文件,也可能是业务系统的数据库,也可能是一些纸质文档。
因此,我们需要统一的数据源接入层完成数据采集。在这些数据采集过程中,可能还会涉及到模型的训练和推理。例如,可以调用一个现有的OCR模型用来识别纸质文档上的关键数据,用于电子化归档并做进一步处理。除了数据采集之外,我们还需要进行一系列的数据预处理(例如脱敏、去燥、校验、条件筛选等等)。由于目前人工智能算法大部分都是基于监督学习的方法,所以数据标注十分必要。另外,实际的数据经常会面临很多问题,比如数据质量较差、数据冗余性较多、数据规律发现难等。因此数据需要额外的调优工作。数据经过一系列采集、处理、标注、调优之后还需要进行半自动、自动化审核验证。例如在经过标注之后,我们需要能够及时评估标注质量。最后,为了方便管理数据,我们需要数据管理来实现数据的存储对接、数据权限控制、数据版本控制、数据元信息管理、数据集切分等。
数据获取:数据源接入模块能够保证ModelArts方便地读取各类数据,例如存储在数据库、本地文件系统、对象存储系统等上的离线数据,也可以是来自于实时流系统的数据流、消息等。另外,为了应对数据获取难的问题,ModelArts服务提供了数据检索和数据扩增的能力。
数据预处理:提供一系列的预处理算法和工具包,例如针对于非结构化数据的格式合法性校验、数据脱敏,以及针对于结构化(表格类)数据的特征清洗(异常样本去除、采样等,还有一些针对单个特征的缺失值补充、归一化、统计变换、离散化等)。
数据标注:针对于非结构化数据(例如图像、视频、文本、音频等)通常,提供一系列的智能化标注能力和团队标注能力。
数据调优:提供数据生成、数据迁移、数据选择、特征选择的能力,以及数据特征分析、标签分析、数据可视化的能力。
数据验证和平台:提供数据审核、标注审核的能力,使处理后的数据满足可信要求。
数据集管理:提供数据集存储管理(对接多类存储系统,如对象存储系统、本地文件系统等)、数据集版本管理、数据元信息管理、数据集切分和生成。
对于开发环境的理解
在AI研究探索场景中,Jupyter 作为一个特殊的存在迅速成长为AI探索类场景开发的首选,能够在其各个阶段满足开发者诉求并覆盖这些关键点,以及支持在浏览器中使用的特点。
Jupyter 起始于 IPython 项目,IPython 最初是专注于 Python 的项目,但随着项目发展壮大,已经不仅仅局限于 Python 这一种编程语言了。按照Jupyter创始人的想法,最初的目标是做一个能直接支持Julia(Ju),Python(Py)以及R三种科学运算语言的交互式计算工具平台,所以将他命名为Ju-Py-te-R,发展到现在Jupyter已经成为一个几乎支持所有语言,能够把代码、计算输出、解释文档,多媒体资源整合在一起的多功能科学运算平台。
这里需要提到的另外一个概念就是“文学编程”,文学编程是一种由Donald Knuth提出的编程范式。这种范式提供了用自然语言来解释程序逻辑的机会。简单来说,文学编程的读者不是机器,而是人。 从写出让机器读懂的代码,过渡到向人们解说如何让机器实现我们的想法,其中除了代码,更多的是叙述性的文字、图表等内容。 文学编程中间穿插着宏片段和传统的源代码,从中可以生成可编译的源代码。
作为第一个贯穿整个科学计算研究的生命周期工具平台,可以将可以分解为,如果我们将科学计算研究全生命周期分解为,个人探索,协作与分享,生产化运行环境,发表与教学,Notebook都可以在这些阶段中满足科研工作的需求。

Jupyter有没有缺点?有的。如果你追求的是产品化代码开发,例如代码格式、依赖管理、产品打包、单元测试等等功能在IDE中是没有很好的支持,当前有一些插件可以做,但是相比重型IDE,功能还是比较弱。此外,Jupyter定义为研究类调试环境,一方面对于分布式的任务当前推荐都是通过单机多进程的方式进行模拟,真实到有多节点拓扑信息的部分在Jupyter中不容易实现,另外一方面,Jupyter的架构并不适合跑非常重量级的作业。对于真实软件产品开发的诉求,还是需要在IDE中进行工程化代码开发,并配搭测试逻辑,将任务部署在集群中进行运行。
所以,我们还是需要继续使用pyCharm开发程序,但是如何让本地的pyCharm与ModelArts结合在一起呢?放心,我们有pyCharm的ModelArts插件。

我们实际上使用一个PyCharm ToolKit工具来帮助建立从本地pyCharm IDE到ModelArts的连接通道,本案例我使用MXNet实现手写数字图像识别应用的示例,在本地快速完成代码编写,发布到ModelArts公有云完成模型的训练和模型生成。
安装toolkit前需要先安装2019.2版本(目前toolkit仅适配该版本)的pycharm,下载地址是:https:/https://img.qb5200.com/download-x/developer.huaweicloud.com/tools。
需要注意,如果已经安装了高版本的pyCharm,需要首先卸载(自动)已安装的pyCharm:
下载一个工具Pycharm-ToolKit-PC-2019.2-HEC-1.3.0.zip,连接本地IDE与云之间的链路:
https://www.jetbrains.com/pycharmhttps://img.qb5200.com/download-x/download/other.html
解压后看到一堆jar文件,

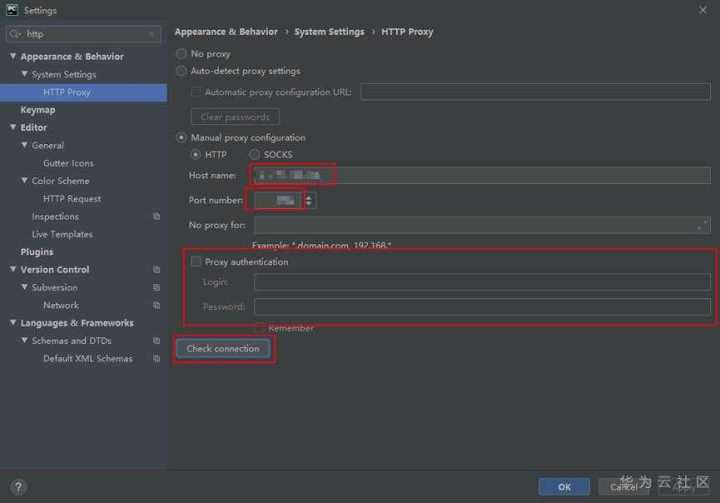
接着回到pyCharm IDE,打开Settings:
找到Plugins,选择一个插件:
点击RestartIDE:
重启后看到如下界面:
然后我们需要去ModelArts网站申明秘钥:
申请秘钥:
短信验证码注册成功后,请务必把csv文件保存到本机。
回到pyCharm IDE:
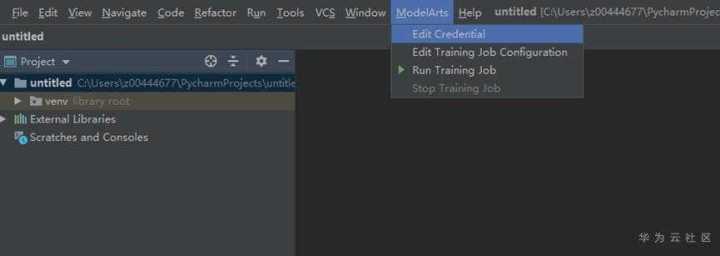
注意,如果填写秘钥键值对成功后,Edit Credential应该是要打钩的,如果没有,请查看网络连接是否存在问题,例如不允许连接外网,或是对访问外网有限制。
注意,需要你重新点击edit credential按钮,退出后就能看到打钩了。
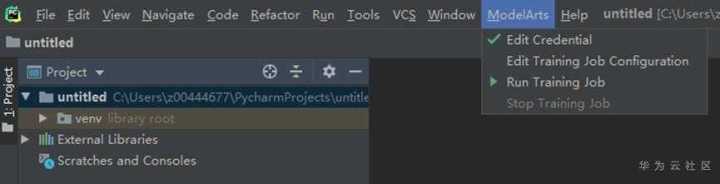
这样我们就完成了pyCharm IDE与ModelArts的对接工作,进入下一步,实际训练一个模型。
首先,下载手写字的数据集:https://modelarts-cnnorth1-market-dataset.obs.cn-north-1.myhuaweicloud.comhttps://img.qb5200.com/download-x/dataset-market/Mnist-Data-Set/archiver/Mnist-Data-Set.zip
登录华为云上传OBS:

创建两个文件夹,一个用于存放数据集,一个用于存放训练生成的日志(需要传回到pyCharm IDE并显示):
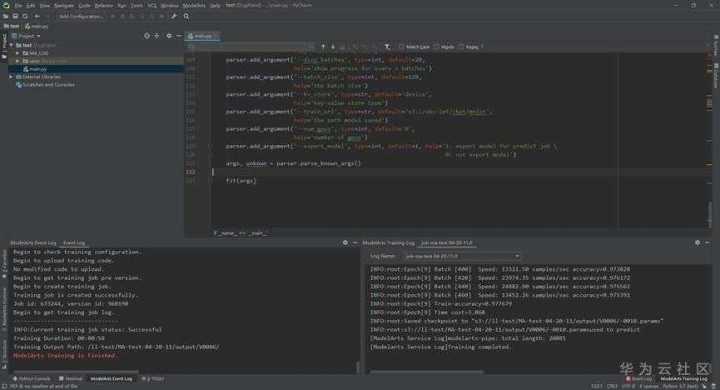
接着在pyCharm打开工程,点击“Run Training Job”:
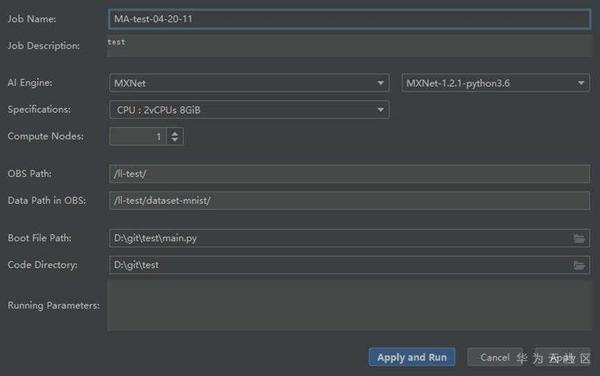
填写参数,可以参考ModelArts训练模型时填写的参数:
训练完成后,训练模型保存在OBS中 /工程名/output/V0006/。
自动学习
在典型的机器学习应用场景中,开发者还必须选择合适的数据预处理工具,特征提取和特征选择方法,从而使原始数据适合机器学习的输入。 在经过这些预处理步骤之后,开发者通常需要根据经验选择恰当的模型算法,以满足当前的场景需求。同时在做模型训练的时候,通常需要做大量的超参数优化,以获得比较优异的的机器学习模型的预测性能。
比如说深度学习在语音识别,图像识别等领域已经取得了令人瞩目的成就。AlexNet在2012年在ImageNet挑战中打败了所有其他传统模型之后,越来越多更加复杂的网络结构被提出来了,网络的层数越来越深,目前的网络已经从最初AlexNet的5个卷积层,增长到目前的上百层,其中涉及到的参数也超过了1亿个。而这些参数都是基于研究人员不断的试错以及调参经验所确定的。而这些通过人工调参得到的模型通常只能针对某一类问题(比如说图像分类)有突出的性能,在遇到新的需要AI建模的问题的时候,通常需要重新构建AI模型,所以在构建AI模型的时候,研究人员需要花费大量的时间和计算资源。
为了降低模型构建的成本,提升AI建模的效率,研究人员提出了自动机器学习(AutoML)的概念,针对特定的机器学习任务,AutoML能够端到端的完成数据处理,特征提取,模型选择以及模型评估。
谈一个ModelArts的自动学习案例-心脏病预测。
我们已经了解了机器学习预测模型的实现原理,本文我们并不会自己动手从头实现,因为当前预测算法已经非常成熟,我们完全可以利用一些公有云大厂提供的自动学习技术,实现模型的快速训练及预测。本案例我们采用的是华为云的公有云AI平台ModelArts,数据来源Kaggle网站。
Kaggle是一家在线AI竞赛网站,开源提供了针对各个行业的脱敏数据,用于支持学生训练对应的AI模型。
首先需要下载开源数据集,原始数据(已开源的脱敏数据)下载地址如下:
https://www.kaggle.com/johnsmith88/heart-disease-dataset
打开csv文件,你可以看到如下图所示:
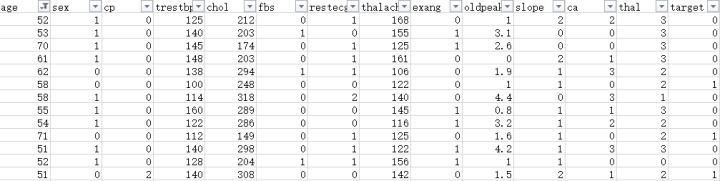
上图中的数据集截图中包括了14个字段,对这14个字段的含义做逐一解释:
- Age:年龄;
- Sex:性别;
- chest pain type (4 values):胸部疼痛类型;
- resting blood pressure:静息血压;
- serum cholestoral in mghttps://img.qb5200.com/download-x/dl:血浆胆固醇水平;
- fasting blood sugar > 120 mghttps://img.qb5200.com/download-x/dl:空腹血糖>120 mghttps://img.qb5200.com/download-x/dl;
- resting electrocardiographic results (values 0,1,2):静息心电图结果;
- maximum heart rate achieved:最大心率;
- exercise induced angina:与运动相关的心绞痛;
- oldpeak = ST depression induced by exercise relative to rest:与静息时比较,运动导致的ST段下移;
- the slope of the peak exercise ST segment:心电图ST segment的倾斜度;
- number of major vessels (0-3) colored by flourosopy:透视检查看到的血管数;
- thal: 1 = normal; 2 = fixed defect; 3 = reversable defect:检测方式;
- target:0和1。
根据医学杂志上查到的信息,一般认为,胆固醇介于200-300之间发病率高;心率异常易导致发病,最大心率在150到175间发病率高;最大心跳在150到175间发病率高;血压在120到140时发病率高。
下载数据之后,我们接下来做的是上传数据到华为云。华为云提供了OBS桶用于存放文件,本文所涉及的csv文件可以作为对象上传。上传文件截图如下图所示:
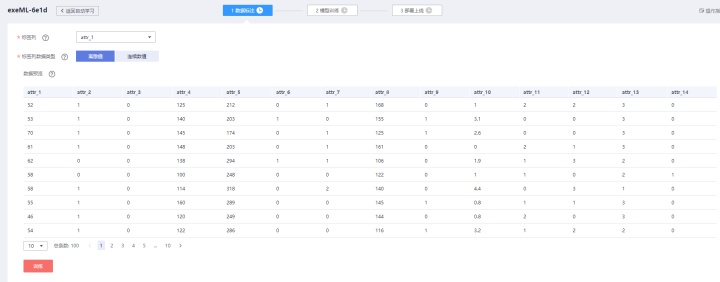
注意,上传文件前请删除表头字段名,否则训练过程中会报错。此外,数据集不用自己划分为训练集和测试集,AI平台会自动按照7:3的比例进行切分。数据预览如下图所示:
接下来就可以进行模型训练了。首先登陆网站https://console.huaweicloud.com/modelarts/,首页如下图所示:
有没有看到屏幕中间的“自动学习”按钮?后续我会写一篇文章系统性介绍什么是自动学习,这里先略过。我们本案例要做的是预测,也就是“预测分析”按钮,点击该按钮。
点击“创建项目”按钮:
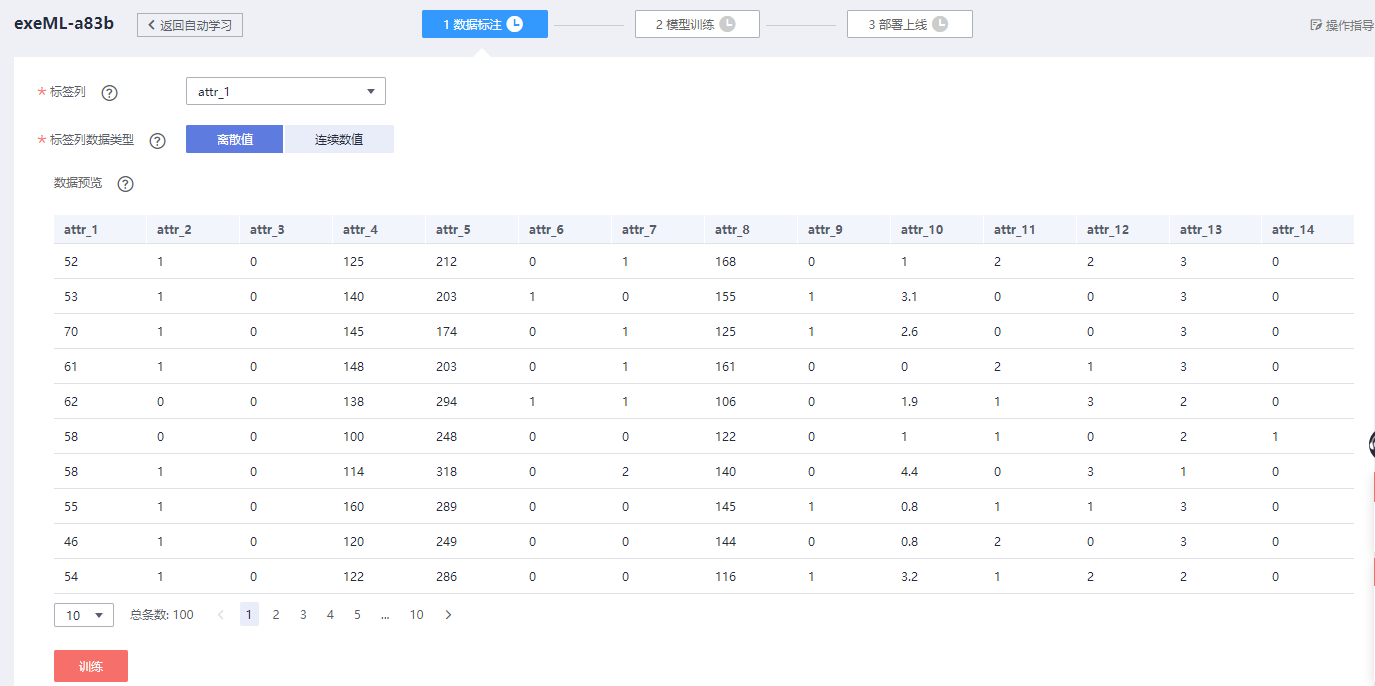
接着选定数据集后,你会看到如下图所示的步骤,分为数据标注、魔性训练,以及部署上线。
点击训练按钮,开始模型训练,由于是机器学习算法,只需要采用CPU资源即可。
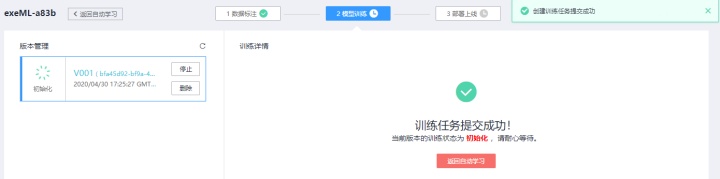
训练任务完成后,你可以点击进去查看模型的准确度预测(默认7:3比例已经预留了测试集,可以用来生成测试报告),如下图所示:
AI市场
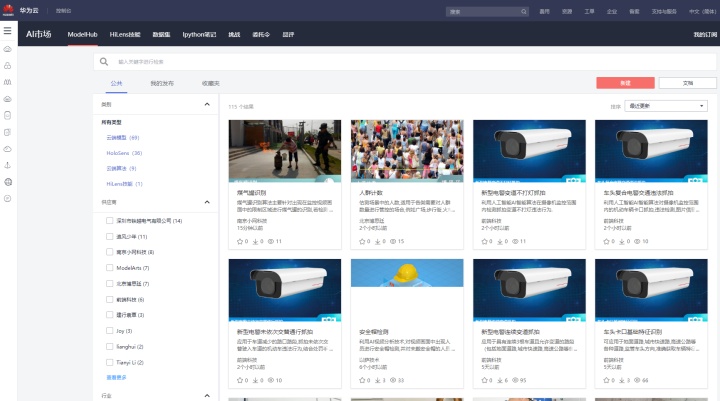
AI市场是一个面向一站式AI开发平台,它提供AI数字资产(包括AI开发工作流和开箱即用的数据集、算法、模型等)的托管式存储仓库。AI市场提供细粒度权限控制的共享,使得个人或企业开发者,能够以公开、私密的方式托管AI数字资产,从而促进开发人员、数据科学家和机器学习工程师使用相应数字资产进行协同工作。随着AI市场测试版的不断改进,后续将支持更多的用法和内容类型,从而进一步简化 AI 的学习、实验、开发和在生产环境中的部署与迭代。
AI市场售卖的由第三方发布的人工智能领域相关AI数字资产本质上属于软件服务,可分为算法类和模型类两种形态。算法类软件目前仅包含云端算法(Cloud Algorithm)。模型类的软件进一步根据不同的支持平台,又细分为云端模型(Cloud Model)、慧眼技能(HiLens skill),以及HoloSens三种。
后记
ModelArts 是可以让开发者上手更快、训练更快、部署更快的全流程平台。它可以为企业带来更多价值:
1、数据标准与准备效率百倍提升
在数据标注与准备阶段,调查发现:数据标注与准备非常耗时费力,约占整体开发时间50%,所以有大家常说的“没有人工就没有智能”。 ModelArts内置AI数据框架,以AI的机制来治理数据,用迭代训练来解决标注的数据量问题。尤其适合数据量很大的场景,数据标注与准备效率百倍提升。
2、模型训练耗时降一半
在模型训练阶段,针对模型训练耗时长的挑战,ModelArts通过各类优化技术,尤其,我们的级联式混合并行技术,在同样的模型、数据集和同等硬件资源情况下,模型训练耗时降低一半。
3、模型一键部署到云、边、端
在模型部署阶段,AI规模化落地,模型部署会非常复杂。例如智慧交通,就有一个常见场景:即更新后的模型,需要一次性同时部署到各种不同规格、不同厂商的摄像头上,是一项非常耗时、费力的巨大工程。而ModelArts已实现一键推送模型到所有边缘、端的设备上,云上的部署还支持 在线和批量推理,满足大并发和分布式等多种场景需求。
4、用AI的机制加速AI开发过程,降低开发门槛
解决了标注、训练、部署之后,ModelArts还能帮助开发者提升开发的效率。AI要规模化走进各行各业,必须要变成一种易掌握的基本技能。ModelArts的自动学习功能,包括模型的自动设计与自动调参等,目的是让每个开发者,都可以快速上手。
ModelArts实现在AI开发全生命周期中,从原始数据、标注数据、训练作业、算法、模型、推理服务等,提供全流程可视化管理。实现千万级模型、数据集以及服务等对象的管理,无需人工干预,自动生成溯源图,选择任一模型,就可以找到对应的数据集、参数、模型部署在哪里。尤其是训练断点接续和训练结果比对,这些很实用的功能很受华为内部开发者欢迎。
5、ModelArts帮助开发者构建自己的生态
ModelArts为开发者提供了支持数据、模型和API的共享管理平台。
对内,可以内部实现数据、模型的共享,帮助企业提升AI开发效率,构建企业自己的AI能力,同时全方位的保障企业AI信息资产的安全。
对外,通过模型仓库,实现开放、健康的生态,帮助AI开发者实现知识到价值的变现,帮开发者构建自己的影响力和生态。
正如本文开篇的引用,Sagemaker是我们强有力的友商AWS的产品,做得很不错,我们始终要满怀着尊敬之心,从友商身上学习精髓,我们始终要以客户为中心,为他们提供各种各样的服务,让中国的用户可以享受安全、可信的公有云服务,可以基于公有云服务享受AI带来的红利。
点击关注,第一时间了解华为云新鲜技术~

加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说