Python机器学习笔记:SVM(1)——SVM概述
战争热诚 人气:1前言
整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思路混乱。所以我对SVM的整理会分为四篇(暂定为四篇)学习,不足之处,请多多指导。
四篇分别为:
Python机器学习笔记:SVM(1)——SVM概述
Python机器学习笔记:SVM(2)——SVM核函数
Python机器学习笔记:SVM(3)——证明SVM
Python机器学习笔记:SVM(4)——sklearn实现
在整理笔记的时候,参考了不少的资料,不少网络写的优秀论文,博客,回答等。于是我在学习了SVM之后,加入了自己的理解,结合网友的笔记整理了自己能理解的SVM,于此写下自己的学习笔记。本着取之于网络,还之于网络的想法,最后将博客公开,最后申明一下,参考的博客,知乎等地址,我均会附于文章后面,不喜勿喷,谢谢。
下面言归正传,开始学习SVM。
1,SVM的基本思想
支持向量机,因为英文名为 support vector machine,故一般简称为SVM。他是一种常用的判别方法,在机器学习领域是一个有监督的学习模式,通常用来进行模型识别,分类,回归分析以及异常值检测。
通俗的讲:支持向量机是一种两类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略(分割原则)便是间隔最大化,最终可转换为一个凸二次规划问题的求解。
支持向量机是许多大佬在多年研究统计学习理论基础上对线性分类器提出的另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去。
支持向量机的提出有很深的理论背景,这个我们后面再学习,下面先说一下SVM的基本思想,SVM的主要思想可以概括为两点:
1 它是针对线性可分情况进行分析,对于线性不可分情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
2 它是基于结果风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
支持向量机的线性分类:是给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于他们落在间隔的哪一侧来预测所属类别。
支持向量机的非线性分类:除了进行线性分类之外,SVM还可以使用所谓的核技巧有效的进行非线性分类,将其输入隐式映射到高维特征空间中。当数据未被标记时,不能进行监督式学习,需要用非监督式学习,它会尝试找出数据到簇的自然聚类,并将新数据映射到这些已形成的簇。将支持向量机改进的聚类算法被称为支持向量聚类,当数据未被标记或者仅一些数据被标记时,支持向量聚类经常在工业应用中用作分类步骤的预处理。
SVM(Support Vector Machines)——支持向量机是在所有知名的数据挖掘算法中最健壮,最准确的方法之一,它属于二分类算法,可以支持线性和非线性的分类。发展到今天,SVM已经可以支持多分类了。
首先,我们看一个例子:
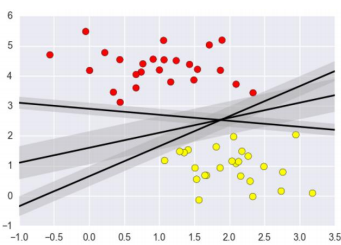
比如上图中,我们用一条直线将两类数据分开了,但是我画了三条线,而且这三条都能分开,但是这三条线那条更好呢?用SVM的思想来说,就是什么样的决策边界才是最好的呢?更进一步,当数据特征更加复杂,本身如果很难分,怎么办呢?那特征复杂后,计算复杂度如何呢?那SVM能实际应用吗?
让我们带着这些问题来学习SVM,而理解SVM,我们先得明白一个概念:线性分类器。
2,分类标准的起源:Logistic回归
之前整理的Logistic回归博文地址:
Python机器学习笔记:Logistic Regression
我们从最起源说起,虽然说之前博文已经学习过Logistic 回归了,不懂的可以去看看,有详细的笔记。但是这里我还是简单的再学习一边别人理解的Logistic回归笔记,温故而知新。
给定一些数据点,他们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。如果用 x 表示数据点,用 y表示类别(y可以取1或者-1,代表两个不同的类),一个线性分类器的学习目标便是要在 n 维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为(其中WT中的T表示转置):

Logistic回归的目的是从特征学习出一个 0/1 分类模型,而这个模型是将特征的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用Logistic函数(或者也称为Sigmoid函数)将自变量映射到(0, 1)上,映射后的值被认为是属于 y=1 的概率。
我们假设函数如下:

其中 x 是 n 维特征向量,函数 g 就是Logistic函数,我们令 z = ΘTx ,则 g(z)为:
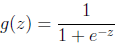
其图像为:
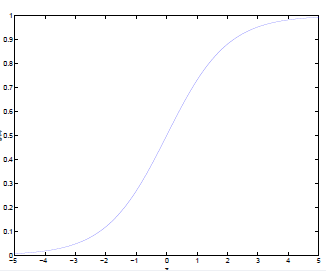
可以看到,将无穷映射到了(0, 1),而我们假设的 hΘx 就是特征属于 y=1的概率:

从而,当我们要判别一个新来的特征属于那个类的时候,只需要求出 hΘx 即可,若 hΘx 大于 0.5就是 y=1的类,反之属于 y=0 的类。
此外,hΘx 只和 θTx有关, θTx >0 ,那么 hΘx >0.5,而 g(z) 只是用来映射,真实的类别决定权还是在于 θTx 。再者,当 θTx >> 0 时,hΘx = 1,反之 hΘx = 0。如果我们只从 θTx 出发,希望模型达到的目标就是让训练数据中 y=1 的特征 θTx >> 0,而 y=0 的特征 θTx << 0。Logistic回归就是要学习得到 θ,使得正例的特征远大于0,负例的特征远小于0,而且要在全部训练实例上达到这个目标。
接下来,尝试把 Logistic 回归做个变形。首先,将使用的结果标签 y=0 和 y=1 替换为 y = -1, y=1,然后将下面公式的 θ0 替换为 b。
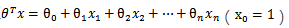
最后将后面的 一串替换为 WTx,即下面一串被替换:
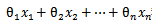
如此,则有了:
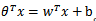
也就是说除了将 y由 y=0 变为 y=-1外,线性分类函数跟 logistic回归的形式化g表示函数没有区别,下面是Logistic回归的形式化表示函数:
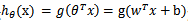
对于逻辑回归我们先说到这里,下面看线性分类和逻辑回归的比较。
SVM和Logistic虽然说都是寻找一个线性分类界限,但出发点不同。SVM是以训练集两个类的边界(支持向量)来考虑划分,而Logistic是从训练集的全局来考虑划分。这也就是为什么Logistic受噪声和离群点的影响比较大。当出现一个离群点时,Logistic划定的边界很有可能会改变。而SVM这边划分的边界却可能丝毫不动(因为离群点并不影响我支持向量)。
3,线性分类的一个例子
3.1 线性可分的二分类模型
什么是线性可分呢?如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?在二维空间中就是一条直线,在三维空间中就是一个平面,依次类推,如果不考虑空位维度,这样的线性函数就统称为超平面。我们一般所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。
定理1:线性二分类模型的目标就是找到一组合适的参数(w, b),使得:

即:线性二分类模型希望在特征空间找到一个划分超平面,将属于不同标记的样本分开。
我们下面举个简单的例子。如下图所示,现在有一个二维平面,平面上有两种不同的数据,分别用圈和叉表示。由于这些数据是线性可分的,所以可以用一条直线将这两类数据分开,这条直线就相当于一个超平面,超平面一边的数据点所对应的 y 全是 -1 ,另一边所对应的 y 全是1。
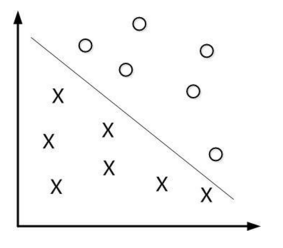
上面的超平面可以用分类函数 f(x) 表示,f(x)如下:

当 f(x)=0 的时候,x便是位于超平面上的点,而 f(x) > 0的点对应 y=1 的数据点,f(x) < 0 的点对应 y = -1的点,如下图所示:
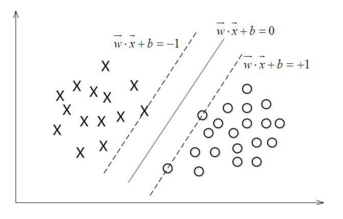
换言之,在进行分类的时候,遇到一个新的数据点 x,将 x 代入 f(x) 中,如果 f(x) 小于0,则将 x 的类别赋予 -1,称 xi 为正例;如果 f(x) 大于 0,则将 x 的类别赋予 1,称xi为负例。
所以接下来的问题是,如何确定这个超平面呢?从直观上而言,这个超平面应该是最适合分类两类数据的直线。而判定“最适合”的标准就是这条直线离直线两边的数据的间隔最大。所以,得寻找有着c最大间隔的超平面。这个问题,我们先搁置一下,下面说一下线性可分支持向量机。
3.2 线性可分支持向量机
线性可分支持向量机(SVM)也是一种线性二分类模型,也需要找到满足 定理1 约束的划分超平面,即(w, b),由于能将样本分开的超平面可能有很多,SVM进一步希望找到离个样本都比较远的划分超平面。
当面对样本的随机扰动时,离每个样本都比较远的划分超平面对扰动的容忍能力比较强,即不容易因为样本的随机扰动使得样本穿越到划分超平面的另外一侧而产生分类错误。因此这样的划分超平面对样本比较稳健,不容易过拟合。另一方面,离各样本都比较远的划分超平面不仅可以把正负样本都分开,还可以比较大的确信度将所有样本分开,包括难分的样本,即离划分超平面近的样本。
分类学习最基本的思想就是基于训练集 D 在样本空间中找到一个划分超平面,将不同类别的样本分开,但是能将训练样本分开的划分超平面可能有很多,所有我们应该去找位于两类训练样本“正中间”的划分超平面。因为该划分超平面对训练样本局部扰动的“容忍”性最好,例如,由于训练集的局限性或者噪声的因素,训练集外的样本可能比正中间的训练样本更接近于两个类的分割界,这将使得许多划分超平面出现错误。而正中间的超平面影响最小,所以这个划分超平面所产生的结果是鲁棒的。
所以问题就变为哪一个分类超平面是最优的?而要算最优超平面,肯定先算出间隔,只有间隔最大化,才能找出最优超平面,所以下面学习函数间隔。
4,函数间隔 functional margin 与几何间隔 geometrical margin
间隔(margin):每个训练观测点到超平面距离中的最小值。
上面也提到了,我们的划分超平面可以用如下线性方程来描述:
其中W为法向量,决定了超平面的方向,b为位移量,决定了超平面与原点的距离。
假设超平面能将训练样本正确的分类,即对训练样本(xi, yi),满足以下公式:
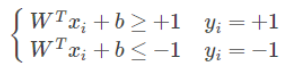
该公式称为最大间隔假设,yi = +1 表示样本为正样本,yi = -1 表示样本为负样本,式子前面选择大于等于 +1,小于等于 =1只是为了方便计算,原则上可是任意常数,但无论是多少,都可以通过对 w 的变换使其为 +1 和 -1,实际上公式等价于:

在超平面 w*x+b=0 确定的情况下, | w*x+b | 能够表示点 x 到距离超平面的远近,而通过观察 w*x+b 的符号与类标记 y 的符号是否一致可以判断分类是否正确,所以,可以用 (y * (w*x+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔(functional margin)的概念。
一般的,当样本点被分类正确时,定义函数间隔(用 γ hat 表示)为:
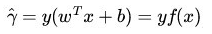
而超平面(w, b)关于 训练数据集T 中所有样本点(xi , yi)的函数间隔最小值(其中, x是特征, y是结果标签,i表示第 i 个样本),便为超平面(w, b)关于训练数据集T的函数间隔(即训练观测与超平面的间隔):

但这样定义的函数间隔有问题,即如果成比例的改变 w 和 b (假设将他们改为 2w 和 2b),则函数间隔的值 f(x) 却变成了原来的 2 倍(虽然此时超平面没有改变),所以引出真正定义点到超平面的距离——几何间距(geometrical margin)的概念。
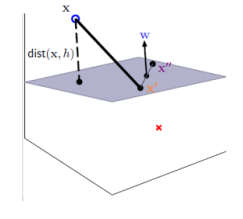
假定对于一个点 x,令其垂直投影到超平面上的对应点为 x0, w是垂直于超平面的一个向量,γ 为样本 x 到超平面的距离,如下图所示:
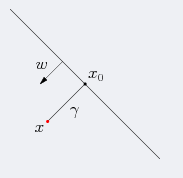
根据平面几何知识,有:

其中 ||w|| 为 w 的二阶范数(范数是一个类似于模的表示长度的概念),w / ||w|| 是单位向量(一个向量除以它的模称之为单位向量)。
又由于 x0 是超平面的点,满足 f(x0) = 0,代入超平面的方差 wTx+b=0 ,可得 wTx0+b=0,即 wTx0 = -b。
随即让上式(平面几何所得公式)的两边同时乘以 WT,然后根据 wTx0 = -b 和 wTw = ||w||2,即可算出 γ :
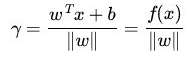
为了得到 γ 的绝对值,令 γ 乘上对应的类别 y,即可得出几何间隔 (用 γ hat 表示)的定义:
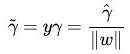
从上述函数间隔和几何间隔的定义可以看出:几何间隔就是函数间隔除以 ||w||,而且函数间隔 y * (w*x+b) = y * f(x) 实际上就是 | f(x) |,只是人为定义的一个间隔度量,而且几何间隔 | f(x) | / || w || 才是直观上的点到超平面的距离。
4.1 点到超平面的距离
这里补充一下点到超平面的距离的概念。设二维空间存在一个超平面实现二类可分如下图所示:

图中的斜线表示超平面 g(x) = w*x + b = 0,二维平面上一点 X 在超平面的距离投影为 X',则二者关系可表示为 X = X' + λ w(w 表示超平面的梯度向量),将 X 代入到 g(x)得:
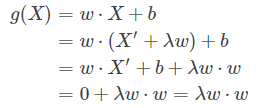
点到超平面的距离即是 X 与 X' 之间的距离:
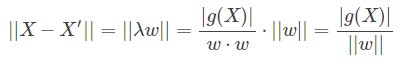
该公司为高等数学中点到平面的距离公式,只不过这里点和平面表达式的系数都用向量表示了。而我们上面却是使用函数间隔和几何间隔的角度引入距离的。所以注意区分。
我们使用PPT的内容表达如下:


5,最大间隔分类器 Maximum Margin Classifier 的定义
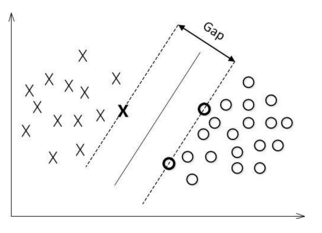
最大间隔超平面:间隔最大的超平面,即使得训练观测到分割超平面的间隔达到最大。
支持向量:样本点中与分离超平面距离最近的样本点的实例
最大间隔超平面的选取只与支持向量有关。
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下面的Gap的一半。
通过由前面的分析可知:函数间隔不适合用来最大化间隔值,因为在超平面固定以后,可以等比例地缩放 w 的长度和 b 的值,这样可以使得 f(x) = wTx + b 的值任意大,亦即函数间隔 γ hat 可以在超平面保持不变的情况下被取得任意大。但几何间隔因为除上了 ||w||,使得在缩放 w 和 b 的时候几何间隔 γ hat 的值是不会改变的,它只随着超平面的变动而变动。因此,这是更加合适的一个间隔。换言之,这里要找的最大间隔分类超平面中的“间隔”指的是几何间隔。
于是最大间隔分类器(maximum margin classifier)的目标函数可以定义为: max γ hat
同时需要满足一些条件,根据间隔的定义,有(下面两个式子是等价的):
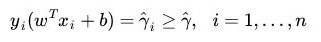
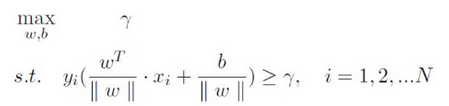
其中,s.t 即subject to,它导出的是约束条件。
即我们希望最大化超平面关于训练集的间隔 γ ,约束条件表示的是超平面关于每个训练样本点的间隔至少是 γ。
回归一下几何间隔的定义:
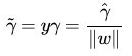
可知:如果令函数间隔 γ hat 等于1(之所以令 γ hat =1,是为了方便推导和优化,且这样做对目标函数的优化没有影响)则有 γ hat = 1 / || w || 且:

从而上述目标函数转换成了(即线性可分支持向量机模型的最优化问题):

相当于在相应的约束条件下(约束条件为上上式子),最大化这个 1 / ||w|| 值,而 1 / ||w|| 便是几何间隔 γ hat 。
如下图所示,中间的实线便是寻找到的最优超平面(optimal Hyper Plane),其到两条虚线边界的距离相等,这个距离便是几何间隔 γ hat ,两条虚线间隔边界之间的距离等于 2*γ hat ,而虚线间隔边界上的点则是支持向量。由于这些支持向量刚好在虚线间隔边界上,所以他们满足 y( wTx + b) = 1(还记得我们把functional margin 定位1了吗?上面我们方便推导和优化的目的,我们可以令 γ hat = 1),而对于所有不是支持向量的点,则显然有 y( wTx + b) > 1。
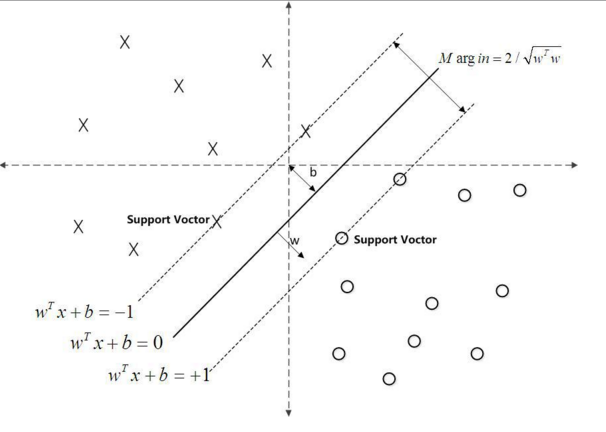
所以线性可分支持向量机模型的最优化问题:

这是一个凸二次规划问题,若能求出(1)~(2)的解 w*, b*,那么就可以得到最大间隔超平面 w*Tx + b = 0 t及分类决函数 f(x)
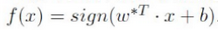
其实到目前为止,对于只关心如何使用SVM的盆友便足够了。可以不用深究其更深的原理了。而需要深究的话,那就接着来。
6,从线性可分到线性不可分
支持向量机是一种二分类模型,他的目的是寻找一个超平面对样本进行分割,分割的原则是间隔最大化,最终转换为一个凸二次规划问题来求解,而由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机
说这个的目的是什么呢?就是我们上面一堆例子,通过线性可分的例子说明了支持向量机,要深入学习支持向量机,我们第一步肯定是从训练样本线性可分过渡到线性不可分。
那我们接着从之前的目标函数说:
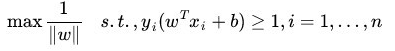
由于求 1 / ||w|| 的最大值相当于求 1 /2 ||w||2 的最小值,所以上述目标函数等价于(w 由分母变为分子,从而也由原来的 max 问题变为 min 问题,很明显,两者问题等价):
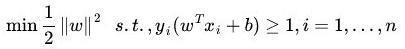
因为现在的目标函数是二次的,约束条件是线性的,所以它是一个凸二次规划问题(这些我们上面均提到了)。那么这个问题如何求解呢?
可以用线程的QP(Quadratic Programming)优化包进行求解。简单来说:就是在一定的约束条件下,目标最优,损失最小。
此外,由于这个问题的特殊结构,还可以通过拉格朗日对偶性(Lagrange Duality)变换到对偶变量(dual variable)的优化问题,即通过求解与原问题等价的对偶问题(dual problem)得到原始问题的最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
6.1整理一下我们的思绪
这里使用老师的PPT,整理一下我们对SVM的理解。
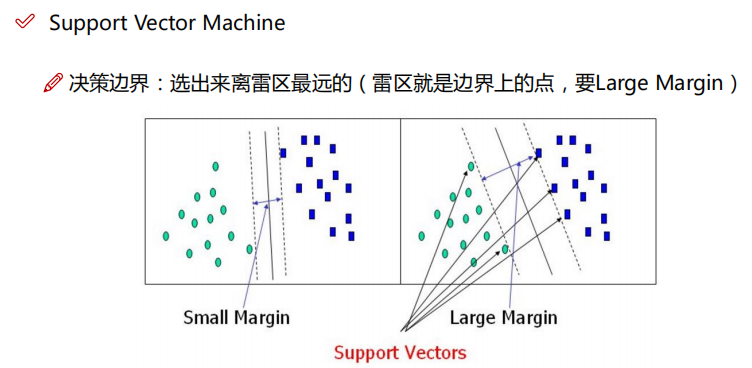




6.2 从原始问题到对偶问题的求解
那么什么是拉格朗日对偶性呢?简单来说,通过对每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier)α,然后定义出拉格朗日函数(通过拉格朗日函数将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题):

然后令:
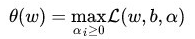
而当所有约束条件都满足时,则最优值为:

上式最优值即最初要最小化的量,所以在要求约束条件得到满足的情况下最小化 1 /2 ||w||2 ,实际上等价于直接最小化 Θ(w) (当然,这里也有约束条件(即KKT条件的约束),就是 αi >= 0, i=1,....n),容易验证,当某个约束条件不满足时,例如 yi * (w*xi + b) < 1,那么显然有 Θ(w) = ∞(只要令 αi = ∞ 即可)。
具体写出来,目标函数变成了:

这里用 P* 表示这个问题的最优解,且和最初的问题是等价的。如果直接求解,那么一上来便得面对 w 和 b 这两个参数,而 αi 又是不等式约束,这个求解过程不好做。不妨把最小和最大的位置交换一下,变成:

交换以后的新问题是原始问题的对偶问题,这个新问题的最优值用 d* 来表示。而且有 d* <= p*,在满足某些条件的情况下,这二者等价,这时候就可以通过求解对偶问题来间接地求解原始问题。
换言之,之所以从 min max 的原始问题 p*,转换为 max min 的对偶问题 d*,一者是因为 d* 是 p* 的近似解,二者转换为对偶问题后,更容易求解。
所以下面可以先求 L 对w, b的极小,再求 L 对 α 的极大。
上面提到了 d* <= p* 在满足某些条件的情况下,二者等价,而要让两者等价需满足 strong duality(强对偶),而后有学者在强对偶下提出了KKT条件,且KKT条件的成立要满足 constraint qualifications,而 constraint qualifications 之一就是 Slater条件。所谓的Slater条件,即指:凸优化问题,如果存在一个点 x,使得所有等式约束都成立,并且所有不等式约束都严格成立(即取严格不等号,而非等号),则满足Slater条件。对于此处,Slater条件成立,所以 d* <= p* 可以取等号。
一般的,一个最优化数学模型能够表示成下列标准形式:
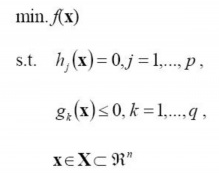
其中f(x)是需要最小化的函数,h(x)是等式约束,g(x)是不等式约束,p和q分别为等式约束和不等式约束的数量。
同时,得明白以下两点:

而KKT的条件就是指上面最优化数学模型的标准形式中的最小点 x* 必须满足下面的条件:

经过论证,我们这里的问题是满足KKT条件的(首先已经满足Slater条件,再者 f 和 gi 也都是可微的,即 L 对 w 和 b 都可导),因此现在我们便转换为求解第二个问题。
也就是说原始问题通过满足KKT条件,已经转换成了对偶问题。而求解这个对偶学习问题,分为三个步骤:
- 1,要让 L(w, b, a) 关于 w 和 b 最小化,
- 2,求 对 α 的极大
- 3,利用SMO算法求解对偶问题中的拉格朗日乘子
6.3 对偶问题求解的三个步骤
根据拉格朗日的对偶性,原始问题的对偶问题是极大极小问题,所以我们求解对偶问题的步骤如下:
(1)首先固定 α,要让 L 关于 w 和 b 最小化,我们分别对 w, b 求偏导数,即令 ∂L / ∂w 和 ∂L / ∂b 等于零:
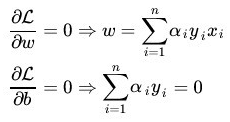
将求偏导数的结果,代入下式:
得到:
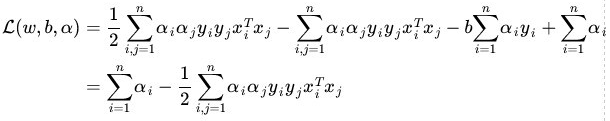
推导过程如下:

最后,得到:
上面推导过程中,“倒数第4步” 推导到 “倒数第3步” 使用了线性代数的转置运算,由于 ai 和 yi 都是实数,因此转置后与自身一样。“倒数第3步” 推导到“倒数第2步” 使用了(a + b + c + ...)(a + b + c + ...) = aa + ab + ac +ba +bb + bc + ... 的乘法法则。最后一步是上一步的顺序调整。
从上面的最后一个式子,我们可以看出,此时的拉格朗日函数只包含一个变量,那就是 αi 便能求出 w 和 b,由此可见,上面提出来的核心问题:分类函数 f(x) = wTx + b 也可以轻而易举的求出来。
(2)对 α 的极大,即是关于对偶问题的最优化问题。经过上面第一个步骤的求 w 和 b,得到的拉格朗日函数式子已经没有变量 w, b ,只有 α 。从上面的式子得到:

这样,求出了 αi ,根据上面对 w 求偏导的式子,我们可以求出 w。然后通过下面式子,可以求出b,最终得到分离超平面和分类决策函数:
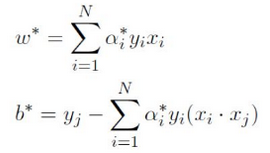

(3)在求得 L(w, b, a) 关于 w 和 b 最小化,以及对 α 的极大值后,最后一步则可以利用 SMO 算法求解对偶问题中的拉格朗日乘子 α。
我们需要构造并求解对偶约束最优化问题

上述式子要解决的是在参数 {α1, α2, α3,.....αn} 上求最大值 W的问题,至于 x(i) 和 y(i) 都是已知数。要了解这个SMO算法如何推导,后面继续学。
6.4 拉格朗日乘子法求解SVM
这里继续使用老师的PPT对SVM的推导做一个梳理,其实就是整理上面6.2 6.3 小节的内容。



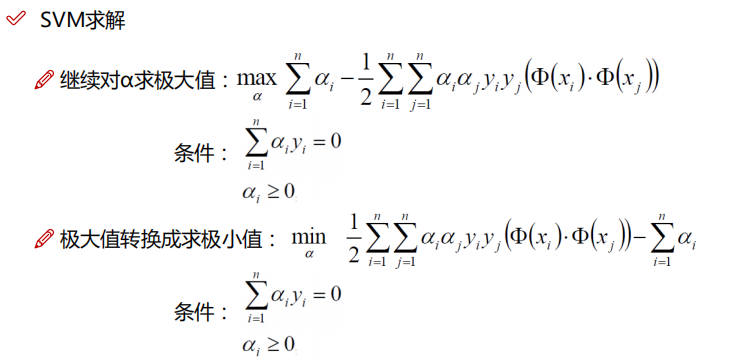
7,从线性不可分到非线性问题
为了过渡到非线性分类情况,我们先看看上述推导过程中得到的一些有趣的形式。
首先就是关于我们的 hyper plane,对于一个数据点 x 进行分类,实际上是通过把 x 代入到 f(x) = wTx + b 算出结果然后根据其正负号来进行类别划分的。而前面的推导,我们得出:
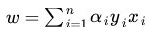
因此分类函数为:

这里的形式的有趣之处在于,对于新点 x 的预测,只需要计算它与训练数据点的内积即可( < ·, ·>表示向量内积),这一点直观重要,是之后使用Kernel进行非线性推广的基本前提。此外,所谓 Supporting Vector 也在这里显示出来——事实上,所谓非 Supporting Vector所对应的系数 α 都是等于零的,因此对于新点的内积计算实际上只需要针对少量的“支持向量” 而不是所有的训练数据即可。
为什么非支持向量对应的 α 等于零呢?直观上来看理解的话,就是这些“后方”的点——正如我们之前分析过一样,对超平面是没有影响的,由于分类完全由超平面决定,所以这些无关的点并不会参与分类问题的计算,因而也就不会产生任何影响了。
首先,我们看看通过Lagrange multiplier 得到的目标函数:
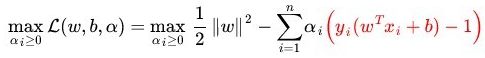
注意到如果 xi 是支持向量的话,上式中红颜色的部分是等于0 的(因为支持向量的 functional margin 等于1),而对非支持向量来说,functional margin 会大于 1,因此红颜色部分是大于零的,而 αi 又是非负的,为了满足最大化, αi 必须等于0。这也就是这些非 supporting vector 的局限性。
至此,我们便得到了一个 maximum margin hyper plane classifier,这就是所谓的支持向量机(Support Vector Machine)。当然,,到目前为止,我们的SVM还比较弱,只能处理线性的情况,不过,在得到了对偶 dual 形式之后,通过 Kernel推广到非线性的情况就变成了一件非常容易的事情了(我们之前说过:通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题)。
8,从线性不可分到特征空间映射与核函数问题——线性不可分支持向量机
8.1 线性不可分
线性不可分定义如下图:
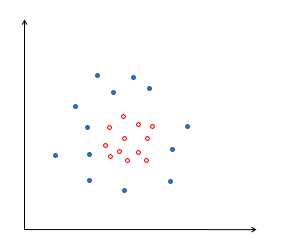
对于上图的二分类数据点,普通线性分类器不行,最大间隔超平面和软间隔超平面也无能为力。面对这样的线性不可分问题,通常的思路是找一个非线性分类边界(比如组合分类器)来实现分类,而SVM则另辟蹊径,将数据点从原始空间映射到特征空间,而数据在特征空间往往就能实现线性可分。
8.2 特征空间映射
对于非线性问题,线性可分支持向量机并不能有效解决,要使用非线性模型才能很好的分类。
- 一维空间向二维空间映射
下面我们考虑一维空间的二分类问题:

我们将它进行一个二次变换,换到二维空间,这里的变换为 x -> x2。

从上面的例子,我们知道变换的核心思想就是:将原始输入空间的数据集映射到高维特征空间中,从而使得数据集可分。
- 二维空间向二维特征空间映射
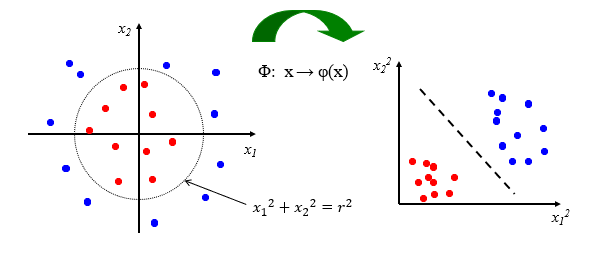
上图中二维空间不可分,但是变换一下坐标空间,也能实现线性可分。
- 二维空间向三维空间的映射
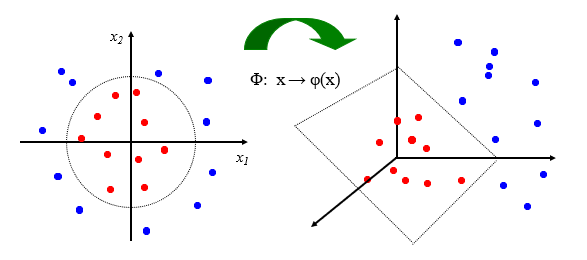
二维空间的数据点不仅可以映射到二维空间,同样也可以映射到三维,如上所示,所以同样可以找到一个超平面能够实现在三维空间的线性可分。
首先将原始的输入特征通过函数 h(xi) 映射到高维空间,拉格朗日对偶有如下形式:

决策函数为:
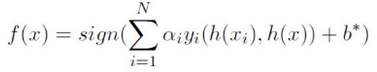
8.3 核函数
原始空间向特征空间的映射需要借助映射函数 Ψ(x)。例如对于数据点 xi,映射到特征空间就变成了Ψ(xi)。而SVM的一大巧妙之处就是映射后的特征空间数据点内积的计算等价于低维空间数据点在映射函数对应的核函数中计算。这大大降低了运算量,因为有的时候高维空间的计算很复杂,下图是一个将 m 维度向量的映射到特征空间的映射函数的例子:

映射后的维度大概是 m^2 / 2 维,则计算映射后的数据内积 Ψ(xi)T*Ψ(xj) 的时间复杂度为 O(n^2)。而如果使用核函数,则计算复杂度会降低为 O(n),例如:
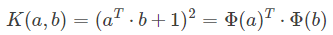
其中 a,b为 m维的向量,Ψ(a) 为 a 经过上面的映射函数后的 m^2 / 2维向量,可以看出核函数 K(a, b) = (aT*b + 1)2 计算的时间复杂度为 O(n)。
核函数是指:设从输入空间 Χ 到特征空间 H的一个映射 h,对任意 x, z 属于 X,函数 K(x, z) 满足 K(x, z) = (h(x), h(z)),则称 K 为核函数。
具体的核函数,我们下一节完整介绍,这里不再赘述。
核技巧:在学习与预测中只定义核函数,而不显示的定义映射函数 h。

通常,直接计算 K(x, z)比较容易,而通过 h(x) 和 h(z) 计算 K(x, z)并不容易。
而成为核函数的充要条件:设 K 是对称函数,则 K(x, z)为核函数的充要条件是对输入空间中任意xi,i=1,2,....m,Gram矩阵K = [K(xi, xj)] m * m 是半正定矩阵。
对偶问题的目标函数:
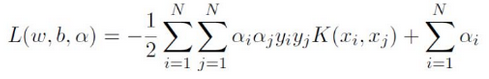
决策函数的形式:

对SVM从简到难的介绍就到这里,然后下一篇文章主要学习核函数的问题,下下一篇对使用Sklearn实现SVM进行了解,最后我们证明一下SVM。这个系列就算结束。可能这一个多月的整理,我不是百分百理解它,但是我相信这是我理解它的开始。
9,从线性不可分到软间隔问题——使用松弛变量处理 outliers(软间隔支持向量机)
软间隔(soft-margin):有时候数据中有一些噪音点,如果我们考虑他们,那么我们的分割超平面就不太好了。
在之前讨论支持向量机的时候,我们就假定,数据是线性可分的,即我们可以找到一个可行的超平面将数据完全分开。后来为了处理非线性数据,在下文使用 Kernel 方法对原来的线性 SVM 进行了推广,使得非线性的情况也能处理。虽然通过映射 Φ(•) 将原始数据映射到高维空间之后,能够线性分隔的概率大大增加,但是对于某些情况还是很难处理。
例如可能并不是因为数据本身是非线性结构的,而只是因为数据有噪音。对于这种偏离正常位置很远的数据点,我们称之为 outlier,在我们原来的SVM模型里,outlier的存在有可能造成很大的影响,因为超平面本身就是只有少数几个 support vector 组成的,如果这些 support vector里又存在 outliers 的话,其影响就很大了。例如下图:
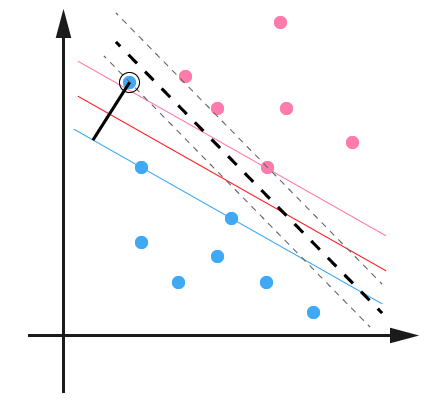
用黑圈圈起来的那个蓝点是一个 outlier,它偏离了自己原本应该在的那个半空间,如果直接忽略掉它的话,原来的分割超平面还是挺好的,但是由于这个 outlier 的出现,导致分割超平面不得不被挤歪了,变成途中黑色虚线所示(这只是一个示意图,并没有严格计算精确坐标),同时 margin 也相应变小了。当然,更严重的情况是,如果这个 outlier 再往右上移动一些距离的话,我们将无法构造出能将数据分开的超平面来。
为了处理这种情况,SVM 允许数据点在一定程度上偏离一下超平面。例如上图中,黑色实线所对应的距离,就是该 outlier 偏离的距离,如果把它移动回来,就刚好落在原来的超平面蓝色间隔边界上,而不会使得超平面发生变形了。
也就是说,在有松弛的情况下 outline 点也属于支持向量SV,同时,对于不同的支持向量,拉格朗日参数的值也不同,如此篇论文 《Large Scale Machine Learning》中的下图所示:
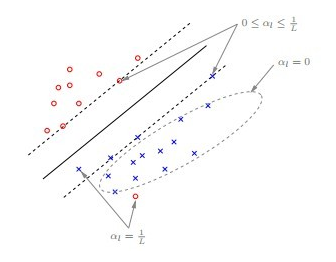
对于远离分类平面的点值为0;对于边缘上的点值在 [0, 1/L],其中,L为训练数据集个数,即数据集大小;对于 outline 数据和内部的数据值为 1/L。
OK,继续回到问题,我们原来的约束条件为:
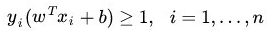
现在考虑到 outlier 问题,约束条件变成了:
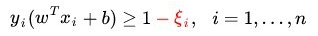
其中,ξi >= 0 称为松弛变量(slack variable),对应数据点 xi 允许偏离的 functional margin 的量。当然,如果我们运行 ξi 任意大的话,那任意的超平面都是符合条件的了。所以,我们在原来的目标函数后面加上一项,使得这些 ξi 的总和也要最小,即软间隔支持向量机的学习问题如下(原始问题):
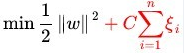
其中 C是惩罚系数,用于控制目标函数中两项(“寻找 margin 最大的超平面” 和 “保证数据点偏差量最小”)之间的权重。注意,其中 ξ 是需要优化的变量(之一),而 C 是一个事先确定好的常量,C值大时对误分类的惩罚增加(C趋于很大时,意味着分类严格不能有错误),C值小时对误分类的惩罚减小(C趋于很小时,意味着可以有更大的错误容忍)。完整的写出来是这个样子:
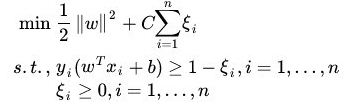
所以上式包含两层含义,使 ||w||2/2 尽量小即间隔尽量大,同时使误分类点的个数尽量小,C是调和两者的系数,有了上式,就可以和线性可分支持向量机一样考虑线性可分支持向量机一样考虑线性支持向量机的学习过程,此时,线性不可分支持向量机的学习问题可以变为之前的凸二次规划问题的求解。
用之前的方法将限制或约束条件加入到目标函数中,得到新的拉格朗日函数,如下所示:
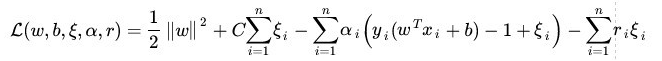
约束如下:
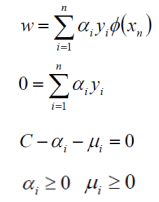
分析方法和前面一样,转换为另一个问题之后,解法类似,我们先让 L 针对 w, b 和 ξ 最小化:

将 w 带回 L 并化简,得到和原来一样的目标函数:

不过由于我们得到 C - αi - ri = 0 而 又有 ri >= 0 (作为 Lagrange multiplier 的条件),因此有 αi <= C,所以整个 dual 问题现在写作:

把前后的结果对比一下:

可以看到唯一的区别就是现在 dual varibale α 多了一个上限 C。而 Kernel 化的非线性形式也是一样的,只要把 <xi, xj> 换成 k(xi, xj)即可。这样一来,一个完整的可以处理线性和非线性并能容忍噪音和 outliers 的支持向量机就介绍完毕了。
所以可以做一个总结,不准确的说:SVM它本质上是一个分类方法,用 WT+b 定义分类函数,于是求 w,b为寻最大间隔,引出 1 / 2 || w || ^2,继而引入拉格朗日因子,化为对拉格朗日乘子a 的求解(求解过程中会设计一系列的最优化或凸二次规划等问题),如此,求 w.b 与 求 a 等价,而 a 的求解可以用一种快速学习算法 SMO,至于核函数,是为了处理非线性问题,若直接映射到高维计算恐维度爆炸,故在低维计算,等效高维表现。
10,支持向量机(SVM)的优缺点
支持向量机(SVM)是一组用于分类,回归和异常值检测的监督学习方法。
10.1 支持向量机(SVM)的优点:
- 在高维空间有效
- 在维度数量大于样本数量的情况下仍然有效
- 在决策功能(称为支持向量)中使用训练点的子集,因此他也是内存有效的
- 多功能:可以为决策功能指定不同的内核函数。提供通过内核,也可以指定自定义内核
10.2 支持向量机(SVM)的缺点:
- 如果特征数量远远大于样本数量,则该方法可能会导致交叉的性能
- 支持向量机不直接提供概率估计,这些是使用昂贵的五折交叉验证计算的
知识储备1:什么叫凸优化?
我们可以看到,上面线性可分支持向量机模型的最优化问题如下:

上面的基本型目标函数是二次的,约束条件是线性的,这是一个凸二次规划问题。可以直接用现成的优化计算包求解。但若利用“对偶问题”来求解,会更高效。
- 啥是凸?什么是凸优化?
凸优化说的是这样一回事情:

凸优化可以想象成给我一个凸函数,我们需要找最低点。
- 为啥叫二次规划问题呢?
据了解。目标函数和约束条件都为变量的线性函数,叫做——线性规划问题。目标函数为变量的二次函数和约束条件为变量的线性函数,叫做二次规划问题。
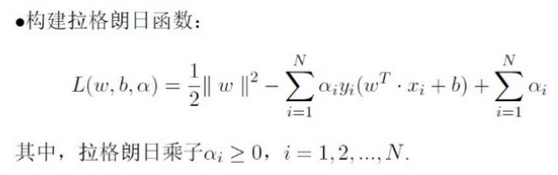
拉格朗日对偶性,即通过给每一个约束条件加上一个拉格朗日乘子。然后定义出拉格朗日函数,通过拉格朗日函数将约束条件融合进目标函数中。目的是,只需要通过一个目标函数包含约束条件,便可以解释清楚问题。
知识储备2:有约束最优化问题的数学模型
SVM 问题是一个不等式约束条件下的优化问题。绝大多数模式识别教程在讨论这个问题时都会加上优化算法的简介。
2.1 有约束优化问题的几何意向
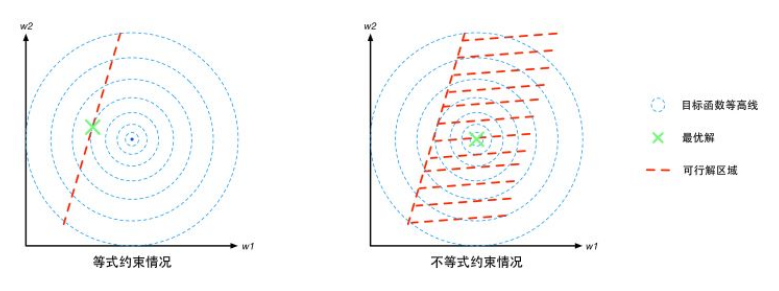
约束条件一般分为等式约束和不等式约束,前者表示为 g(x) = 0 ;后者表示为 g(x) <= 0、
假设 x 属于 Rd(就是这个向量一共有 d 个标量组成),则 g(x) = 0 则是由 d-1 维的超平面。那么有约束优化问题就要求在这个 d-1 维的曲面或者超平面上找到能使得目标函数最小的点,这个 d-1 维的曲面就是“可行解区域”。
对于不等式约束条件, g(x) <= 0 ,则可行解区域 d-1 维曲面扩展成 d 维空间的一个子集。我们可以从 d=2 的二维空间进行比对理解。等式约束对应的可行解空间就是一条线;不等式约束对应的则是这条线以及线的某一侧对应的区域,就像下面的这幅图(图中的模板函数等高线其实就是等值线,在同一条等值线上的点对应的目标函数值相等)。
2.2 拉格朗日乘子法
尽管上面我们已经想象出有约束优化问题的几何意向。可是如何利用代数方法找到这个被约束了的最优解呢?这就需要用到拉格朗日乘子法。
首先定义原始目标函数 f(x),拉格朗日乘子法的基本思想是把约束条件转换为新的目标函数 L(x, λ) 的一部分,从而使有约束优化问题变成我们习惯的无约束优化问题,那么该如何去改造原来的目标函数 f(x),使得新的目标函数 L(x, λ) 的最优解恰好在可行解区域中呢?这就需要我们去分析可行解区域的最优解的特点。
知识储备3:KKT条件
KKT条件是一个线性规划问题能有最优解的充分和必要条件。
对于不等式约束条件 g(x) <= 0 的情况,如下图所示,最优解所在的位置 x* 有两种可能,或者在边界曲线 g(x)=0 上或者在可行解区域内部满足不等式 g(x) < 0 的地方。
第一种情况:最优解在边界上,就相当于约束条件就是 g(x) = 0.参考下图,注意此时的目标函数 f(x) 的最优解是在可行解区域外面,所以函数 f(x) 在最优解 x* 附加的变化趋势是“在可行解区域内侧较大而在区域外侧较小”,与之对应的是函数 g(x) 在可行解区域内小于 0 ,在区域外大于零,所以在最优解 x* 附加的变换趋势是内部较小而外部较大。这意味着目标函数 f(x) 的梯度方向与约束条件函数 g(x) 的梯度方向相反。因此根据下式,可以推断出参数 λ > 0。
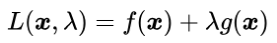

一般的,一个最优化数学模型可以表示成如下形式:
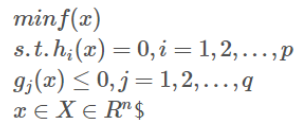
h(x) 是等式约束,g(x)是不等式约束,p, q表示约束的数量。
而这个最优化数学模型的最优解 x* 需满足的条件(即KTT条件)为:
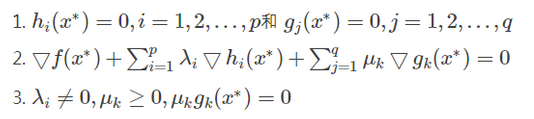
参考文献:
https://zhuanlan.zhihu.com/p/31652569
https://zhuanlan.zhihu.com/p/57648645
http://www.360doc.com/content/18/0727/00/7669533_773495537.shtml
https://blog.csdn.net/qq_35992440/articlehttps://img.qb5200.com/download-x/details/80987664
https://zhuanlan.zhihu.com/p/24638007
https://blog.csdn.net/weixin_40170902/articlehttps://img.qb5200.com/download-x/details/80113128
加载全部内容