文本处理三剑客与正则表达式详解
JF Zhu 人气:2我们知道在 Linux 中,“一切皆文件”,作为系统管理员或者程序员我们每天都需要和大量的文本文件打交道。Linux 系统为我们提供了三个文本处理工具:grep, sed, 和 awk,它们也被称为 Linux 文本处理的三剑客被大家广泛使用。今天先和大家介绍一下 grep 的以及正则表达式的用法,因为 grep 只有和正则表达式结合在一起才会发挥出它强大的威力。
Grep 的用法
grep 是一个强大的文本搜索工具,可以用于在文本文件中搜索指定格式(正则表达式)的字符串,并将匹配的行输出。它的用法如下:
#grep [选项] 查找条件 目标文件
比如我们有一个文本文件,littlestar.txt,它的内容如下:
TWINKLE, twinkle, little star,
How I wonder what you are!
Up above the world so high,
Like a diamond in the sky.
(1) 查找一个字符串
比如要查找“twinkle”
#grep "twinkle" littlestar.txt

匹配上的字符串用红色突出显示出来了。
(2) “-i”忽略大小写
#grep -i "twinkle" littlestar.txt
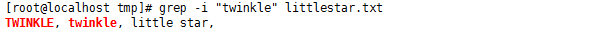
结果可以看到TWINKLE 和 twinkle 都匹配上了
(3) “-n”显示行号
#grep -n "twinkle" littlestar.txt

发现在结果的最左侧显示行号
(4) “-c”仅显示匹配到的行号
#grep -c "twinkle" littlestar.txt

结果仅显示 1,表示第 1 行匹配到了查找的字符串
(5) “-o” 仅显示匹配到的字符串,不显示同行的其他内容
#grep -o "twinkle" littlestar.txt

结果仅显示 twinkle
(6) “-w”精确匹配单词
#grep -w "twinkle" littlestar.txt 查找twinkle
#grep -w "twink" littlestar.txt 查找twink

结果显示完整的单词 twinkle 可以匹配到,如果只查找 twink 则没有匹配上
(7) “-v“ 反转查找,显示不包含关键字的行
#grep -v "twink" littlestar.txt

结果除了第一行,其他都匹配成功了
正则表达式
正则表达式(Regular Expression)是一种描述字符串匹配模式的方式,它的应用非常广泛,几乎所有的主流编程语音里都有正则表达式的实现,比如 Java,C#,Python等等,当然 Linux 的 Shell 对它也有很好的支持。我们很多时候想要做的是模糊查找,比如以133开头的手机号,这个时候 grep 就需要用到正则表达式了。
正则表达式有两个版本,基本正则表达式(BRE)和它的升级版--扩展正则表达式(ERE)。我们主要了解一下扩展版,grep 命令需要加上 -E 选项,或者使用 egrep 命令。
正则表达式中用来匹配字符串模式的字符被称作元字符,学习正则表达式主要就是学会元字符的组合运用。元字符主要有下面几种:
-
用于位置锚定:"^" 和 "$"
-
用于字符匹配:".","[ ]"
-
用于匹配次数:"*","+","?","{ }"
-
用于分组:"( )"
可能看到这里已经有很多人一头雾水了,正则表达式到底长什么样呢?下面我们就看一下具体的例子吧。
(1) 位置锚定元字符:
^ 表示以某个字符串开头,$ 表示以某个字符串结尾
比如查找以 “TWINK” 开头的行
#grep -E "^TWINK" littlestar.txt

查找以 “star,” 结尾的行
#grep "star,$" littlestar.txt

(2) 字符匹配元字符:
“.”表示匹配任意单个字符,“[ ]”用来匹配指定范围内的单个字符
比如 "s..r" 可以匹配以s开头,r结尾的单词
#grep "s..r" littlestar.txt

"[ ]" 当中可以放具体的字符,比如 "[Tt]"表示匹配大写或者小写的 t
#grep "^[Tt]" littlestar.txt

"[ ]" 也可以用来表示一个范围,比如 [0-9]表示单个数字,[a-z]表示单个小写字母,[A-Z]表示一个大写字母。[a-zA-Z]表示一个字母,包括大小写。比如 "[A-Z][a-z][a-z][a-z]" 表示首字母大写,四个字母的一个单词:
#grep -E "[A-Z][a-z][a-z][a-z]" littlestar.txt
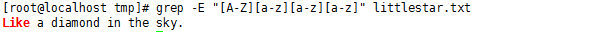
"^"用来表示不在指定范围内的其他字符,比如[^a-zA-Z]表示所有非字母的字符
#grep -E "[^a-zA-Z]" littlestar.txt

(3)匹配次数元字符
"?" 表示匹配到 0 次或 1 次,比如 "w?in" 表示 w 被匹配到 0 次或 1 次,所以 "win" 或者 "in" 都可以被匹配到
#grep -E "w?in" littlestar.txt

"+" 表示匹配到至少 1 次,比如 "w+in" 就表示至少得有一个字母 w,可以是 "win" 或者 "wwin",但是 "in" 就不能匹配上了
#grep -E "w+in" littlestar.txt

"*" 表示匹配到任意次,可以是 0 次,可以是 1 次,也可以是多次,比如 "w*in" 可以匹配到 "in",也可以匹配到 "win" 或者 "wwin"
#grep -E "w*in" littlestar.txt

"*" 经常与 "." 搭配使用,".*" 表示匹配任意数量的任意字符,比如 "T.*E" 可以匹配到任何以 T 开头,以 E 结尾的单词
#grep -E "T.*E" littlestar.txt

"{ }" 可以用于表示明确的匹配次数,比如 "lit{2}le",就表示 "little",中间要匹配 2 个字母 t
#grep -E "lit{2}le" littlestar.txt

"{ }" 也可以指定一个匹配次数的范围,比如 "{2,3}" 表示匹配 2 次到 3 次,"{2, }" 表示匹配至少 2 次,最多则不限
#grep -E "lit{2,}le" littlestar.txt

(4) 分组元字符
"( )" 可以将几个字符组合在一起作为一个整体处理,比如我们想对 "twinkle," 这个字符串做为一个整体,匹配它是否出现过两次,可以写成 "(twinkle){2}"
#grep -E -i "(twinkle,){2}" littlestar.txt
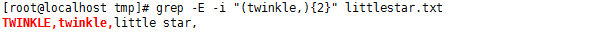
最后
文本处理往往是需要命令行工具和正则表达式结合使用。正则表达式相对来说比较抽象,但实际上正则表达式的使用就是对元字符的组合运用,所以掌握每个元字符对学好正则表达式至关重要。
推荐阅读:
《Linux的运行等级与目标》
《软链接 vs. 硬链接》
《Linux 目录详解》
《虚拟机安装 Linux 最完整攻略》
《Xshell 与 Xftp 的安装与使用》
《Linux,Unix,GNU 到底有什么样的渊源?》

- The End -
加载全部内容