人工智能中小样本问题相关的系列模型演变及学习笔记(四):知识蒸馏、增量学习
FinTecher 人气:1【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】本文衔接上两个随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(一):元学习、小样本学习
【再啰嗦一下】本文衔接上两个随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
【再啰嗦一下】本文衔接上两个随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(三):迁移学习
一、知识蒸馏综述
知识蒸馏被广泛的用于模型压缩和迁移学习当中。
本文主要参考:模型压缩中知识蒸馏技术原理及其发展现状和展望
1. 基本概念
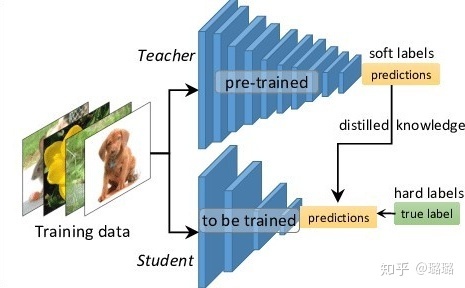
知识蒸馏可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。
- 可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能。
- 可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
2. 知识蒸馏的主要算法
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标驱动的算法、基于特征匹配的算法两个大的方向。
2.1 知识蒸馏基本框架
Hinton最早在文章“Distilling the knowledge in a neural network”中提出了知识蒸馏的概念,即knowledge distilling,对后续的许多算法都产生了影响,其框架示意图如下:
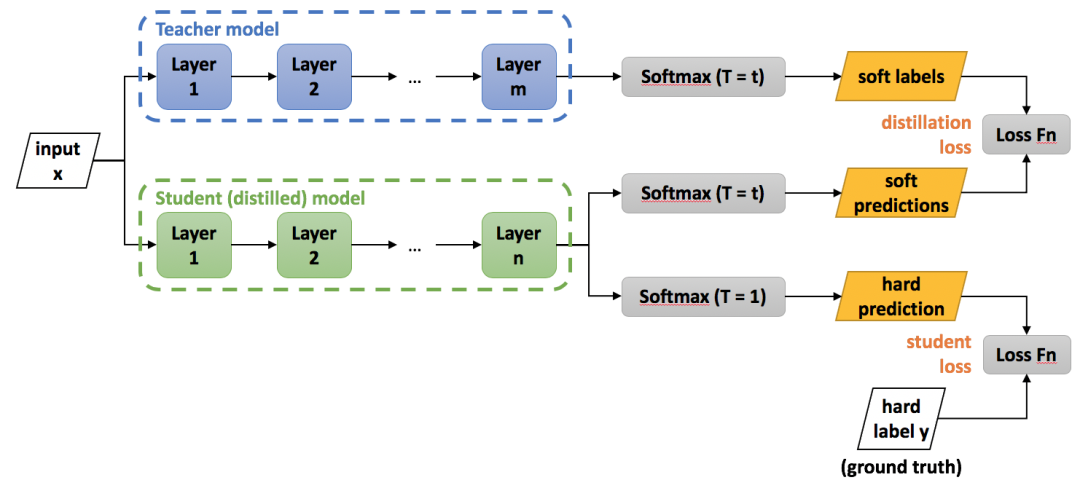
从上图中可以看出,包括一个teacher model和一个student model,teacher model需要预先训练好,使用的就是标准分类softmax损失,但是它的输出使用带温度参数T的softmax函数进行映射,如下:
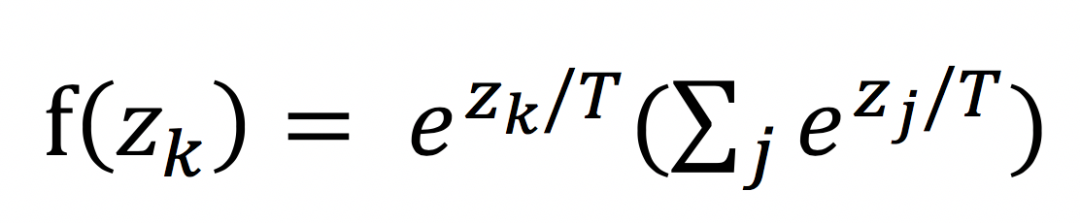
当T=1时,就是softmax本身。当T>1,称之为soft softmax,T越大,因为输入 zk 产生的概率 f(zk) 差异就会越小。之所以要这么做,其背后的思想是:当训练好一个模型之后,模型为所有的误标签都分配了很小的概率。然而实际上对于不同的错误标签,其被分配的概率仍然可能存在数个量级的悬殊差距。这个差距,在softmax中直接就被忽略了,但这其实是一部分有用的信息。
训练的时候小模型有两个损失:一个是与真实标签的softmax损失,一个是与teacher model的蒸馏损失,定义为KL散度。
当teacher model和student model各自的预测概率为pi,qi时,其蒸馏损失部分梯度传播如下:

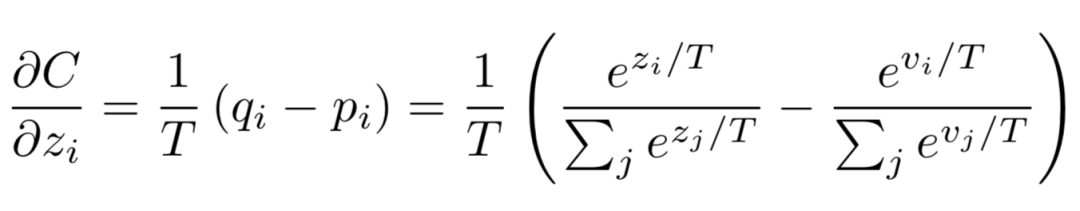
可以看出形式非常的简单,梯度为两者预测概率之差,这就是最简单的知识蒸馏框架。
2.2 优化目标驱动的知识蒸馏框架
Hinton等人提出的框架是在模型最后的预测端,让student模型学习到与teacher模型的知识,这可以称之为直接使用优化目标进行驱动的框架,类似的还有ProjectionNet。
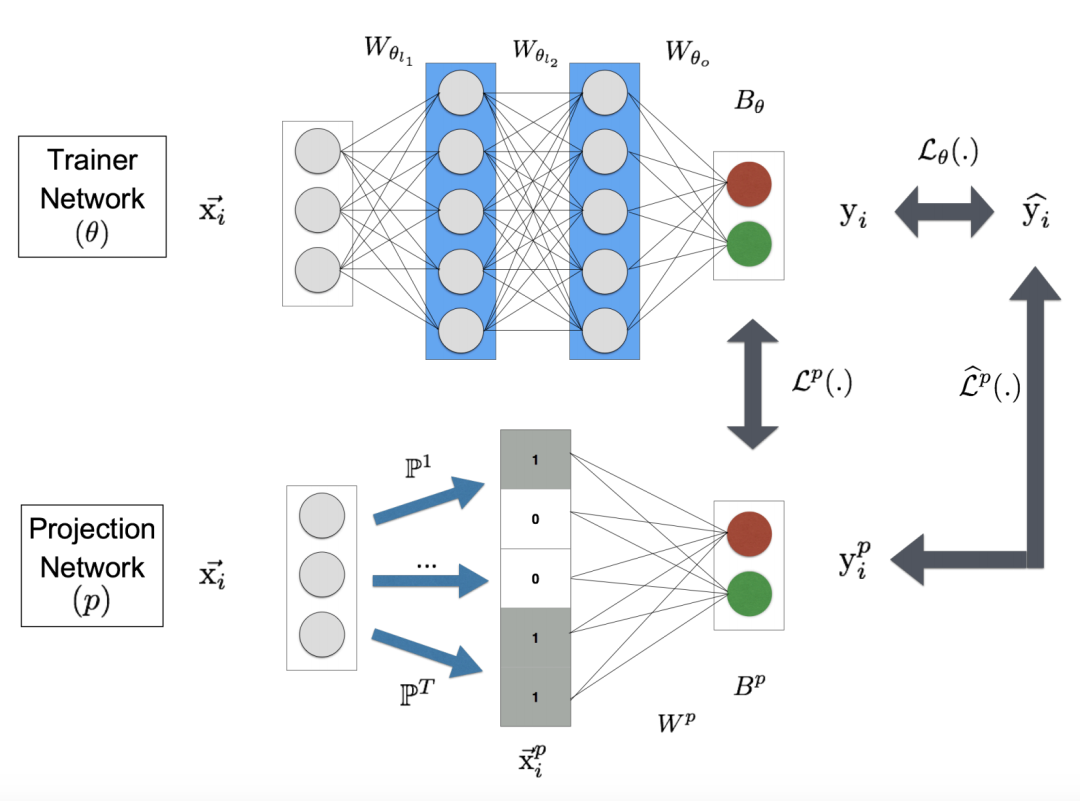
PrjojectNet同时训练一个大模型和一个小模型,两者的输入都是样本,其中大模型就是普通的CNN网络,而小模型会对输入首先进行特征投影。每一个投影矩阵P都对应了一个映射,由一个d-bit长的向量表示,其中每一个bit为0或者1,这是一个更加稀疏的表达。特征用这种方法简化后自然就可以使用更加轻量的网络的结构进行训练。那么怎么完成这个过程呢?文中使用的是locality sensitive hashing(LSH)算法,这是一种聚类任务中常用的降维的算法。
优化目标包含了3部分,分别是大模型的损失,投影损失,以及大模型和小模型的预测损失,全部使用交叉熵,各自定义如下:

基于优化目标驱动的方法其思想是非常直观,就是结果导向型,中间怎么实现的不关心,对它进行改进的一个有趣方向是GAN的运用。
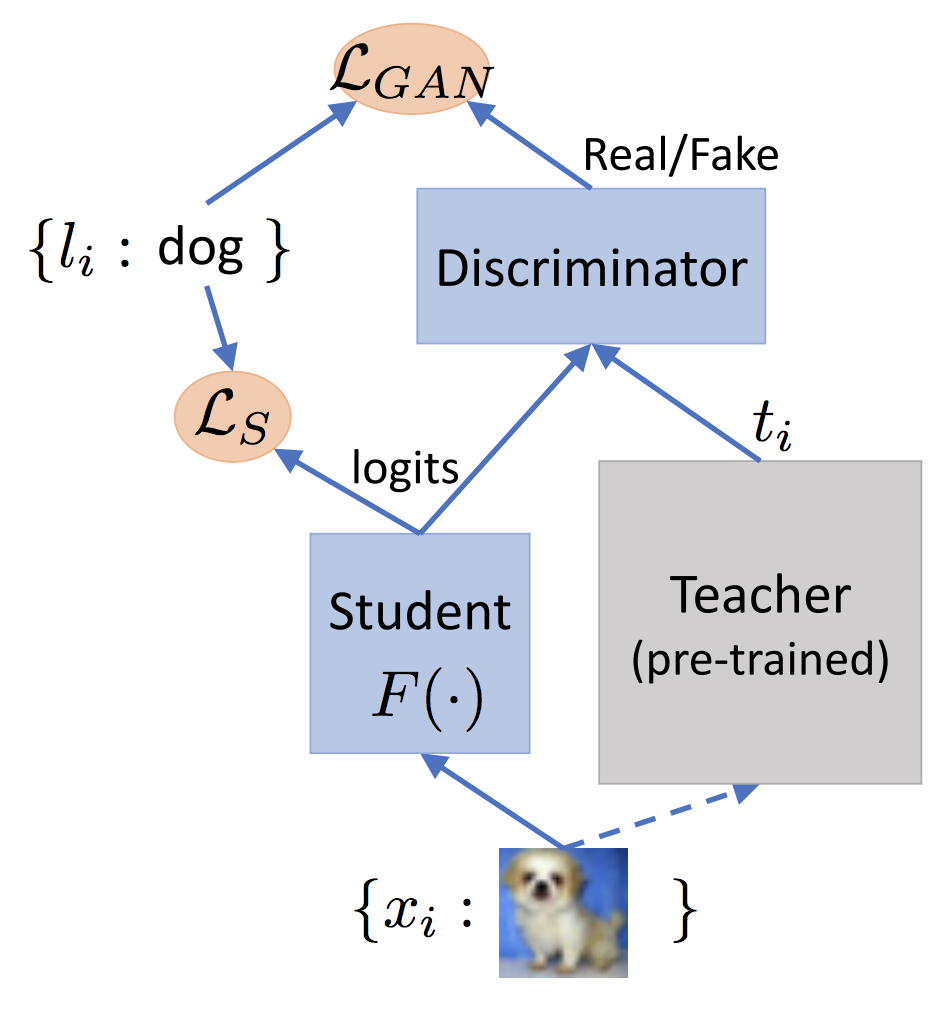
2.3 特征匹配的知识蒸馏框架
结果导向型的知识蒸馏框架的具体细节是难以控制的,会让训练变得不稳定且缓慢。一种更直观的方式是将teacher模型和student模型的特征进行约束,从而保证student模型确实继承了teacher模型的知识,其中一个典型代表就是FitNets,FitNets将比较浅而宽的Teacher模型的知识迁移到更窄更深的Student模型上,框架如下:

FitNets背后的思想是,用网络的中间层的特征进行匹配,不仅仅是在输出端。它的训练包含了两个阶段:
(1)第一阶段就是根据Teacher模型的损失来指导预训练Student模型。记Teacher网络的某一中间层的权值Wt为Whint,意为指导的意思。Student网络的某一中间层的权值Ws为Wguided,即被指导的意思,在训练之初Student网络进行随机初始化。需要学习一个映射函数Wr使得Wguided的维度匹配Whint,得到Ws',并最小化两者网络输出的MSE差异作为损失,如下:
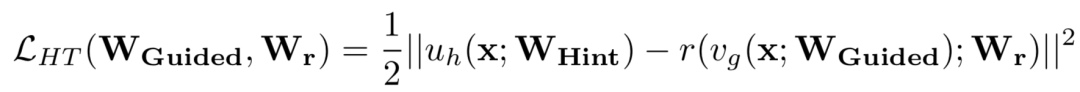
(2)第二个训练阶段,就是对整个网络进行知识蒸馏训练,与上述Hinton等人提出的策略一致。不过FitNet直接将特征值进行了匹配,先验约束太强,有的框架对激活值进行了归一化。
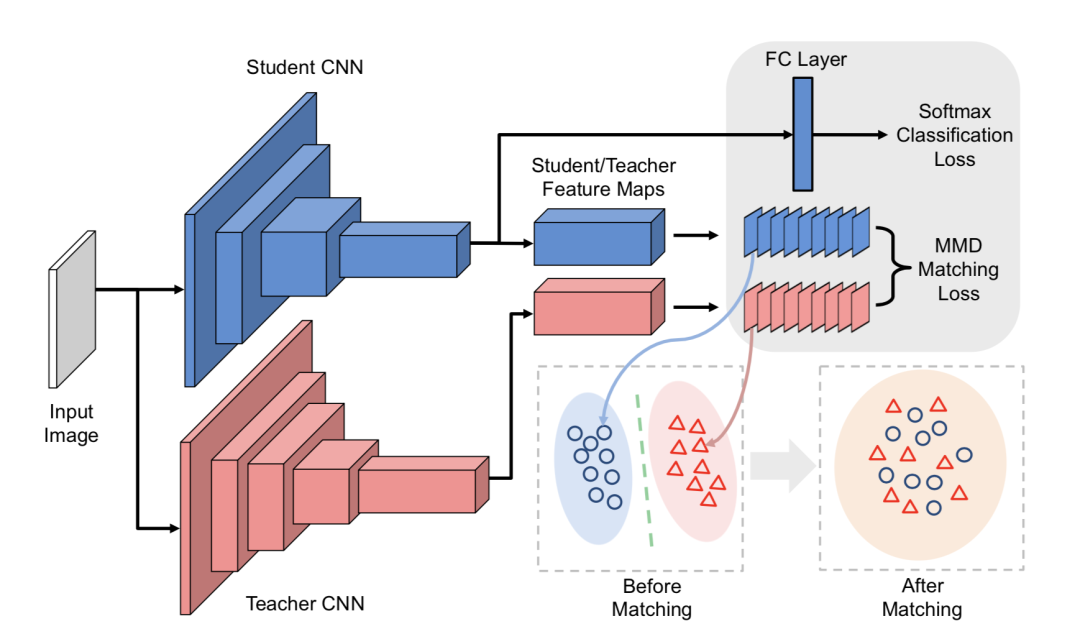
基于特征空间进行匹配的方法其实是知识蒸馏的主流,类似的方法非常多,包括注意力机制的使用、类似于风格迁移算法的特征匹配等。
3. 知识蒸馏算法的展望
知识蒸馏还有非常多有意思的研究方向,这里我们介绍其中几个。
3.1 不压缩模型
机器学习模型要解决的问题如下,其中y是预测值,x是输入,L是优化目标,θ1是优化参数。

因为深度学习模型没有解析解,往往无法得到最优解,我们经常会通过添加一些正则项来促使模型达到更好的性能。
Born Again Neural Networks框架思想是通过增加同样的模型架构,并且重新进行优化,以增加一个模型为例,要解决的问题如下:
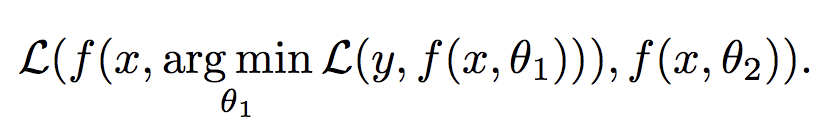
具体的流程就是:
(1)训练一个教师模型使其收敛到较好的局部值。
(2)对与教师模型结构相同的学生模型进行初始化,其优化目标包含两部分,一部分是要匹配教师模型的输出分布,比如采用KL散度。另一部分就是与教师模型训练时同样的目标,即数据集的预测真值。
然后通过下面这样的流程,一步一步往下传,所以被形象地命名为“born again”。
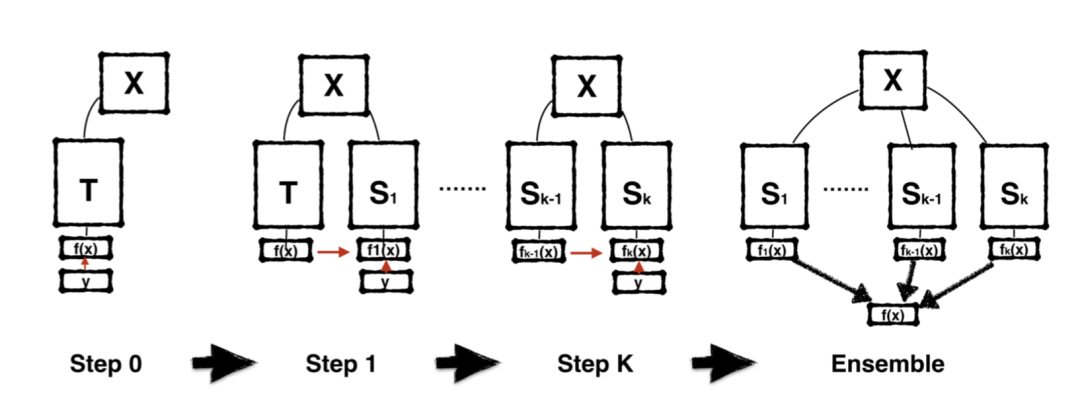
类似的框架还有Net2Net,network morphism等。
3.2 去掉 teacher 模型
一般知识蒸馏框架都需要包括一个Teacher模型和一个Student模型,而Deep mutual learning则没有Teacher模型,它通过多个小模型进行协同训练,框架示意图如下。

Deep mutual learning在训练的过程中让两个学生网络相互学习,每一个网络都有两个损失。一个是任务本身的损失,另外一个就是KL散度。由于KL散度是非对称的,所以两个网络的散度会不同。
相比单独训练,每一个模型可以取得更高的精度。值得注意的是,就算是两个结构完全一样的模型,也会学习到不同的特征表达。
3.3 与其他框架的结合
在进行知识蒸馏时,我们通常假设teacher模型有更好的性能,而student模型是一个压缩版的模型,这不就是模型压缩吗?与模型剪枝,量化前后的模型对比是一样的。所以知识蒸馏也被用于与相关技术进行结合,apprentice框架是一个代表。
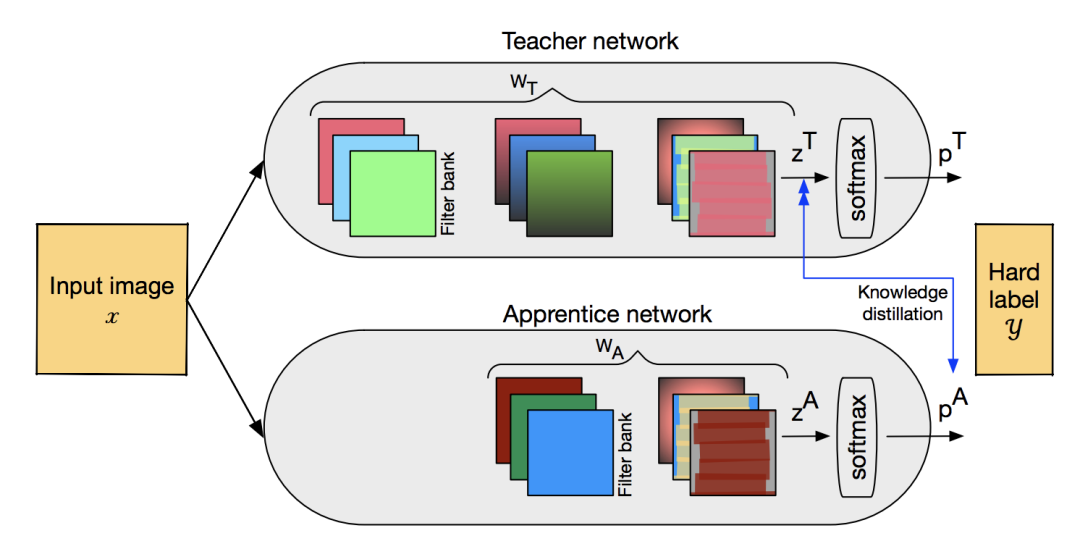
网络结构如上图所示,Teacher模型是一个全精度模型,Apprentice模型是一个低精度模型。
4. 知识蒸馏在智能推荐中的应用
如果您对智能推荐感兴趣,欢迎浏览我的另一篇博客:智能推荐算法演变及学习笔记 、CTR预估模型演变及学习笔记
本文主要参考:知识蒸馏在推荐系统中的应用
1. 基本概念
深度学习模型正在变得越来越复杂,网络深度越来越深,模型参数量也在变得越来越多。而这会带来一个现实应用的问题:将这种复杂模型推上线,模型响应速度太慢,当流量大的时候撑不住。
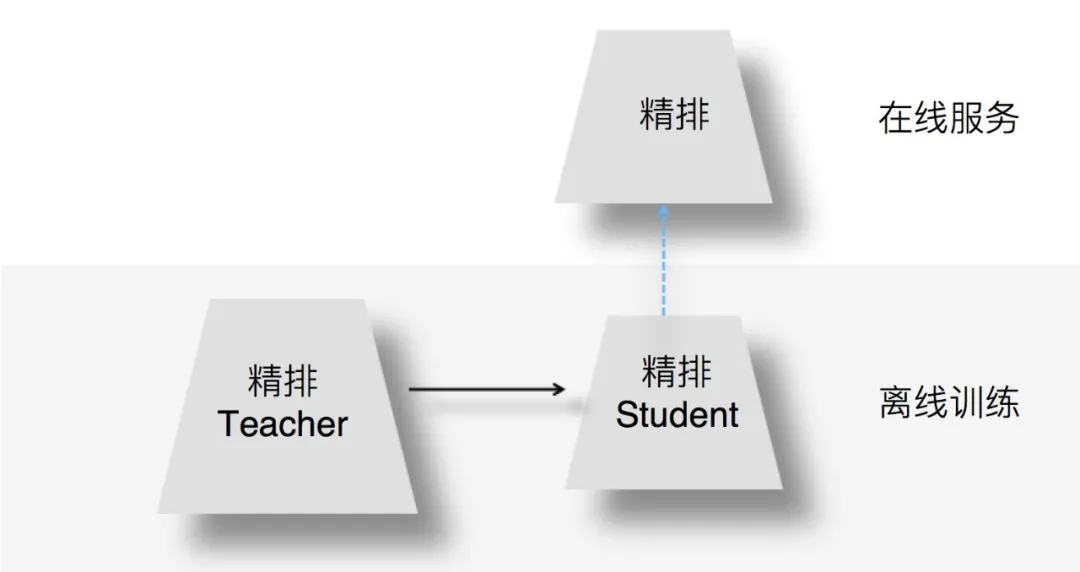
知识蒸馏就是目前一种比较流行的解决此类问题的技术方向。复杂笨重但是效果好的 Teacher 模型不上线,就单纯是个导师角色,真正上战场挡抢撑流量的是灵活轻巧的 Student 小模型。
在智能推荐中已经提到,一般有三个级联的过程:召回、粗排和精排。
- 召回环节从海量物品库里快速筛选部分用户可能感兴趣的物品,传给粗排模块。
- 粗排环节通常采取使用少量特征的简单排序模型,对召回物料进行初步排序,并做截断,进一步将物品集合缩小到合理数量,向后传递给精排模块。
- 精排环节采用利用较多特征的复杂模型,对少量物品进行精准排序。
以上环节都可以采用知识蒸馏技术来优化性能和效果,这里的性能指的线上服务响应速度快,效果指的推荐质量好。
2. 精排环节采用知识蒸馏
精排环节注重精准排序,所以采用尽量多特征复杂模型,以期待获得优质的个性化推荐结果。这也意味着复杂模型的在线服务响应变慢。
(1)在离线训练的时候,可以训练一个复杂精排模型作为 Teacher,一个结构较简单的 DNN 排序模型作为 Student。
- 因为 Student 结构简单,所以模型表达能力弱,于是,我们可以在 Student 训练的时候,除了采用常规的 Ground Truth 训练数据外,Teacher 也辅助 Student 的训练,将 Teacher 复杂模型学到的一些知识迁移给 Student,增强其模型表达能力,以此加强其推荐效果。
(2)在模型上线服务的时候,并不用那个大 Teacher,而是使用小的 Student 作为线上服务精排模型,进行在线推理。
- 因为 Student 结构较为简单,所以在线推理速度会大大快于复杂模型。
3. 精排环节蒸馏方法
(1)阿里妈妈在论文 "Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net" 提出。
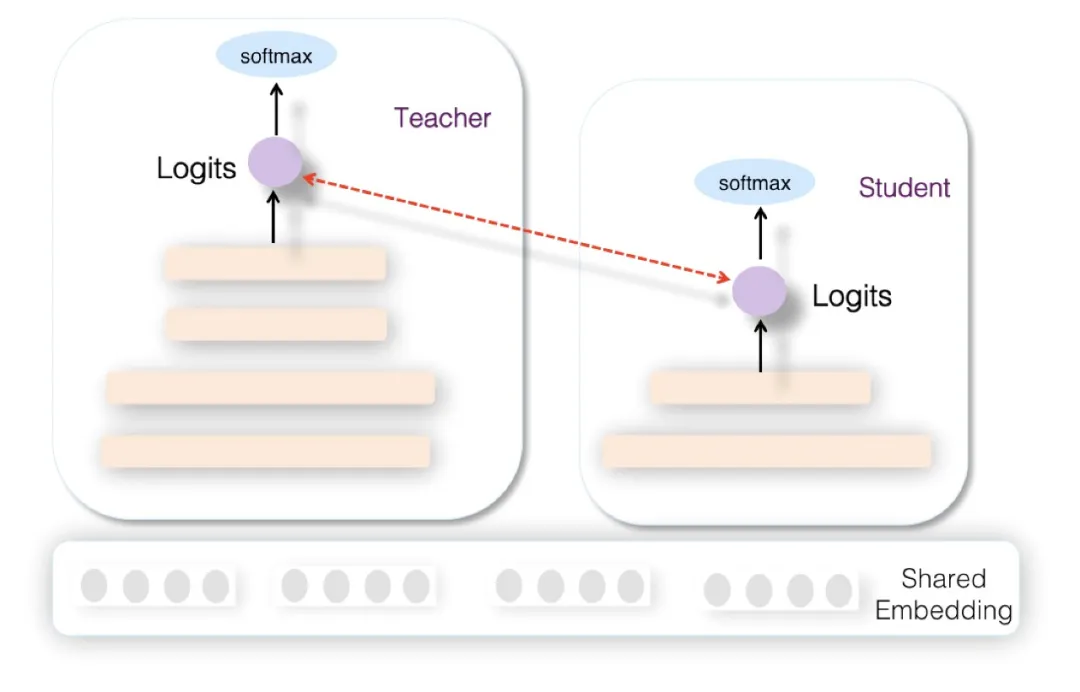
在精排环节采用知识蒸馏,主要采用 Teacher 和 Student 联合训练 ( Joint Learning ) 的方法。所谓联合训练,指的是在离线训练 Student 模型的时候,增加复杂 Teacher 模型来辅助 Student,两者同时进行训练,是一种训练过程中的辅导。
从网络结构来说,Teacher 和 Student 模型共享底层特征 Embedding 层,Teacher 网络具有层深更深、神经元更多的 MLP 隐层,而 Student 则由较少层深及神经元个数的 MLP 隐层构成,两者的 MLP 部分参数各自私有。
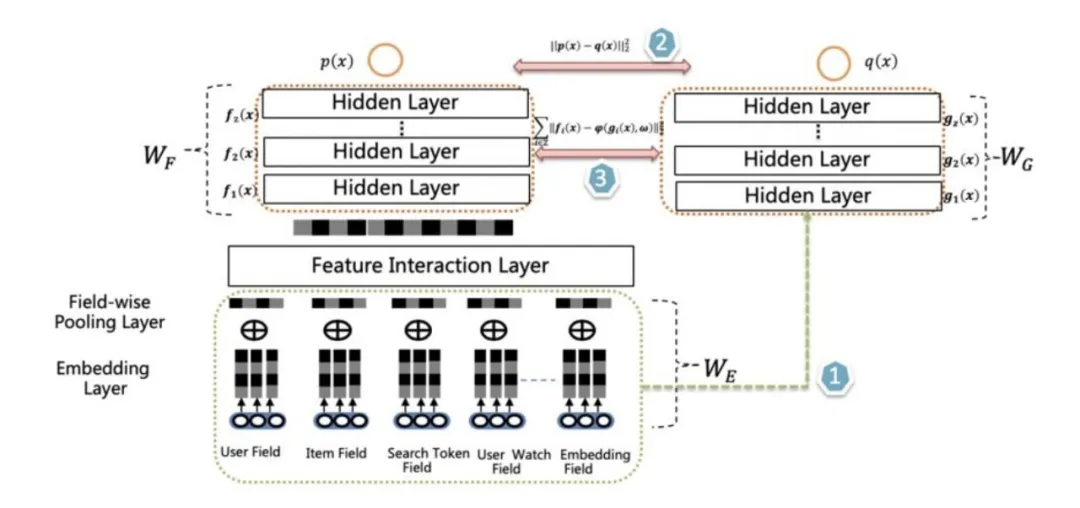
(2)爱奇艺在排序阶段提出了双 DNN 排序模型,可以看作是在阿里的 rocket launching 模型基础上的进一步改进。
为了进一步增强 student 的泛化能力,要求 student 的隐层 MLP 的激活也要学习 Teacher 对应隐层的响应,这点同样可以通过在 student 的损失函数中加子项来实现。但是这会带来一个问题,就是在 MLP 隐层复杂度方面,Student 和 Teacher 是相当的。那么,Teacher 相比 student,模型复杂在哪里呢?
这引出了第二点不同:双 DNN 排序模型的 Teacher 在特征 Embedding 层和 MLP 层之间,可以比较灵活加入各种不同方法的特征组合功能。通过这种方式,体现 Teacher 模型的较强的模型表达和泛化能力。
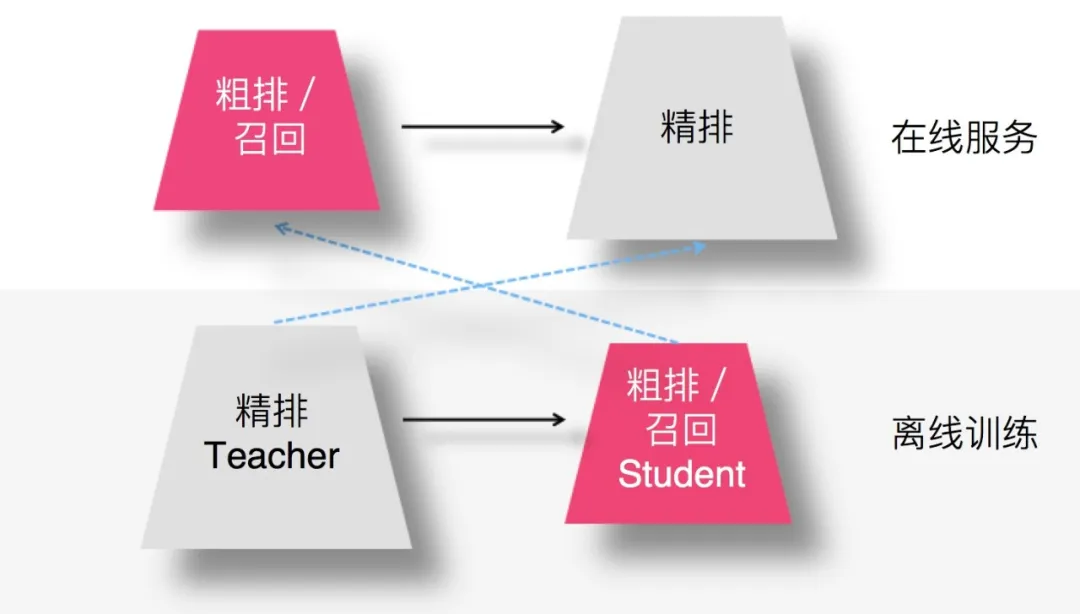
4. 召回 / 粗排环节采用知识蒸馏
召回或者粗排环节,作为精排的前置环节,需要在准确性和速度方面找到一个平衡点,在保证一定推荐精准性的前提下,对物品进行粗筛,减小精排环节压力。这两个环节并不追求最高的推荐精度。毕竟在这两个环节,如果准确性不足可以靠返回物品数量多来弥补。而模型小,速度快则是模型召回及粗排的重要目标之一。
- 用复杂的精排模型作为 Teacher,召回或粗排模型作为小的 Student,比如 FM 或者双塔 DNN 模型等。
- 通过 Student 模型模拟精排模型的排序结果,可以使得前置两个环节的优化目标和推荐任务的最终优化目标保持一致。
5. 召回/粗排环节蒸馏方法
作者给出了一些可能的处理方式,目前业内还没定论。
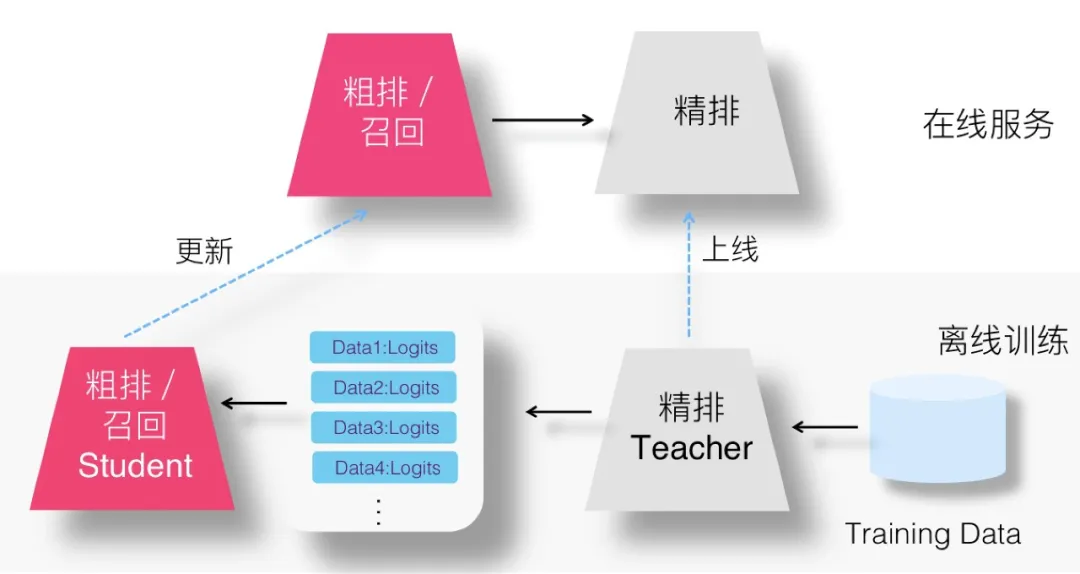
(1)设想一:召回蒸馏的两阶段方法
(2)设想二:logits方法
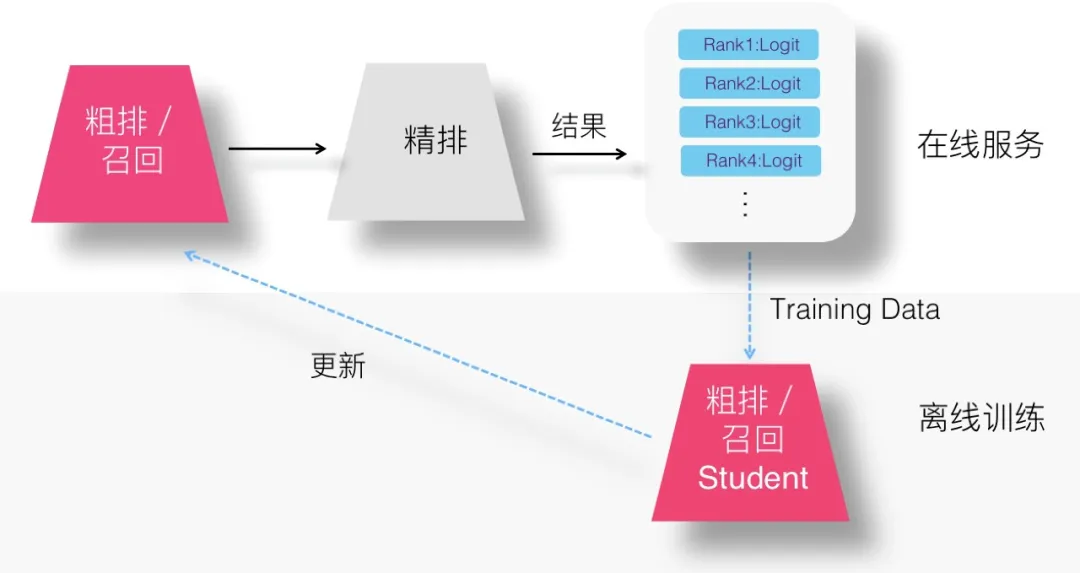
(3)设想三:Without-Logits 方案
(4)设想四:Point Wise 蒸馏:Point Wise Loss 将学习问题简化为单 Item 打分问题。

(5)设想五:Pair Wise 蒸馏:Pair Wise Loss 对能够保持序关系的训练数据对建模。
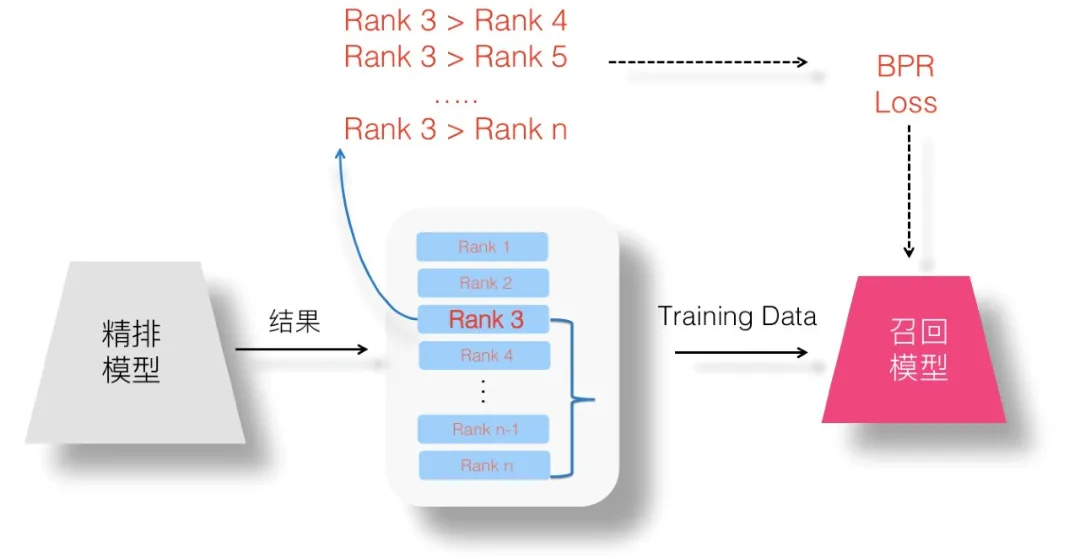
(6)设想六:List Wise 蒸馏:List Wise Loss 则对整个排序列表顺序关系建模。
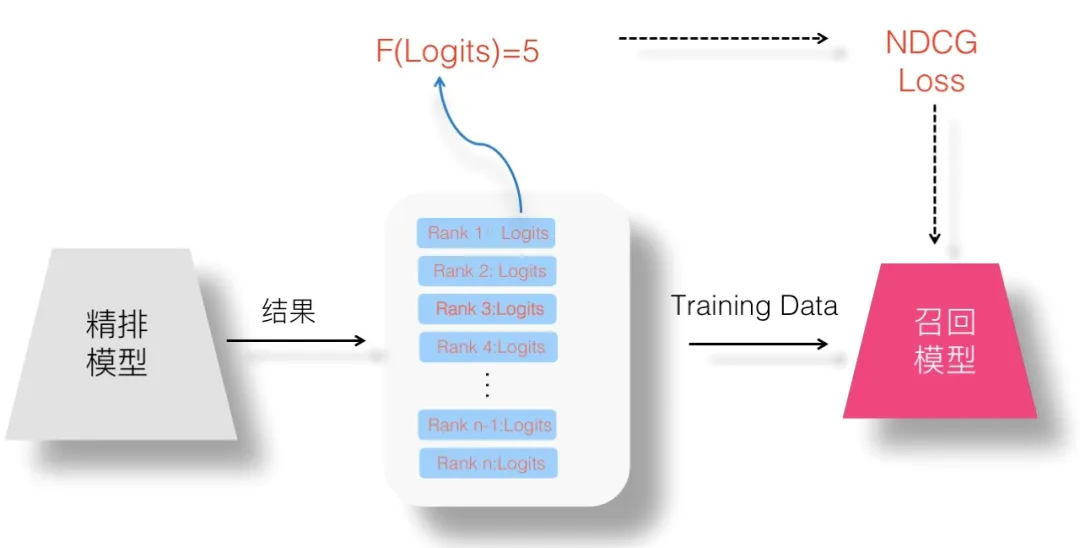
(7)设想七:联合训练召回、粗排及精排模型的设想
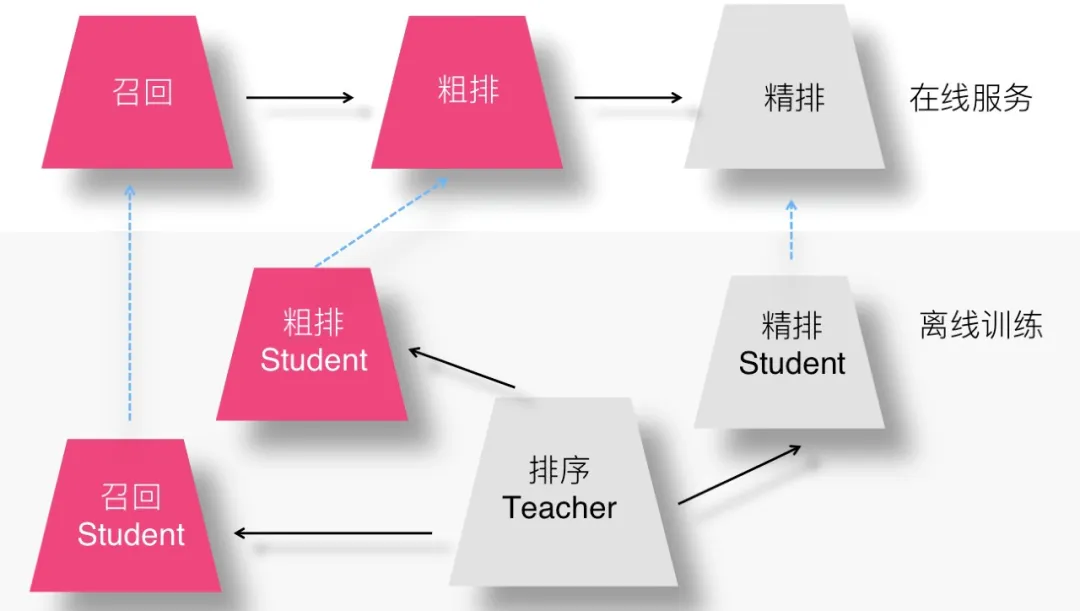
二、增量学习:补充介绍
主要关注的是灾难性遗忘,平衡新知识与旧知识之间的关系。即如何在学习新知识的情况下不忘记旧知识。
引用Robipolikar对增量学习算法的定义,即一个增量学习算法应同时具有以下特点:
- 可以从新数据中学习新知识
- 以前已经处理过的数据不需要重复处理
- 每次只有一个训练观测样本被看到和学习
- 学习新知识的同时能保持以前学习到的大部分知识
- 一旦学习完成后训练观测样本被丢弃
- 学习系统没有关于整个训练样本的先验知识
在概念上,增量学习与迁移学习最大的区别就是对待旧知识的处理:
- 增量学习在学习新知识的同时需要尽可能保持旧知识,不管它们类别相关还是不相关的。
- 迁移学习只是借助旧知识来学习新知识,学习完成后只关注在新知识上的性能,不再考虑在旧知识上的性能。
关于这部分内容,未来有看到好的资料,再来分享。
如果您对异常检测感兴趣,欢迎浏览我的另一篇博客:异常检测算法演变及学习笔记
如果您对智能推荐感兴趣,欢迎浏览我的另一篇博客:智能推荐算法演变及学习笔记 、CTR预估模型演变及学习笔记
如果您对知识图谱感兴趣,欢迎浏览我的另一篇博客:行业知识图谱的构建及应用、基于图模型的智能推荐算法学习笔记
如果您对时间序列分析感兴趣,欢迎浏览我的另一篇博客:时间序列分析中预测类问题下的建模方案 、深度学习中的序列模型演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍 、机器学习中的聚类算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
加载全部内容