tensorflow实现残差网络方式(mnist数据集)
Tom Hardy 人气:1介绍
残差网络是何凯明大神的神作,效果非常好,深度可以达到1000层。但是,其实现起来并没有那末难,在这里以tensorflow作为框架,实现基于mnist数据集上的残差网络,当然只是比较浅层的。
如下图所示:
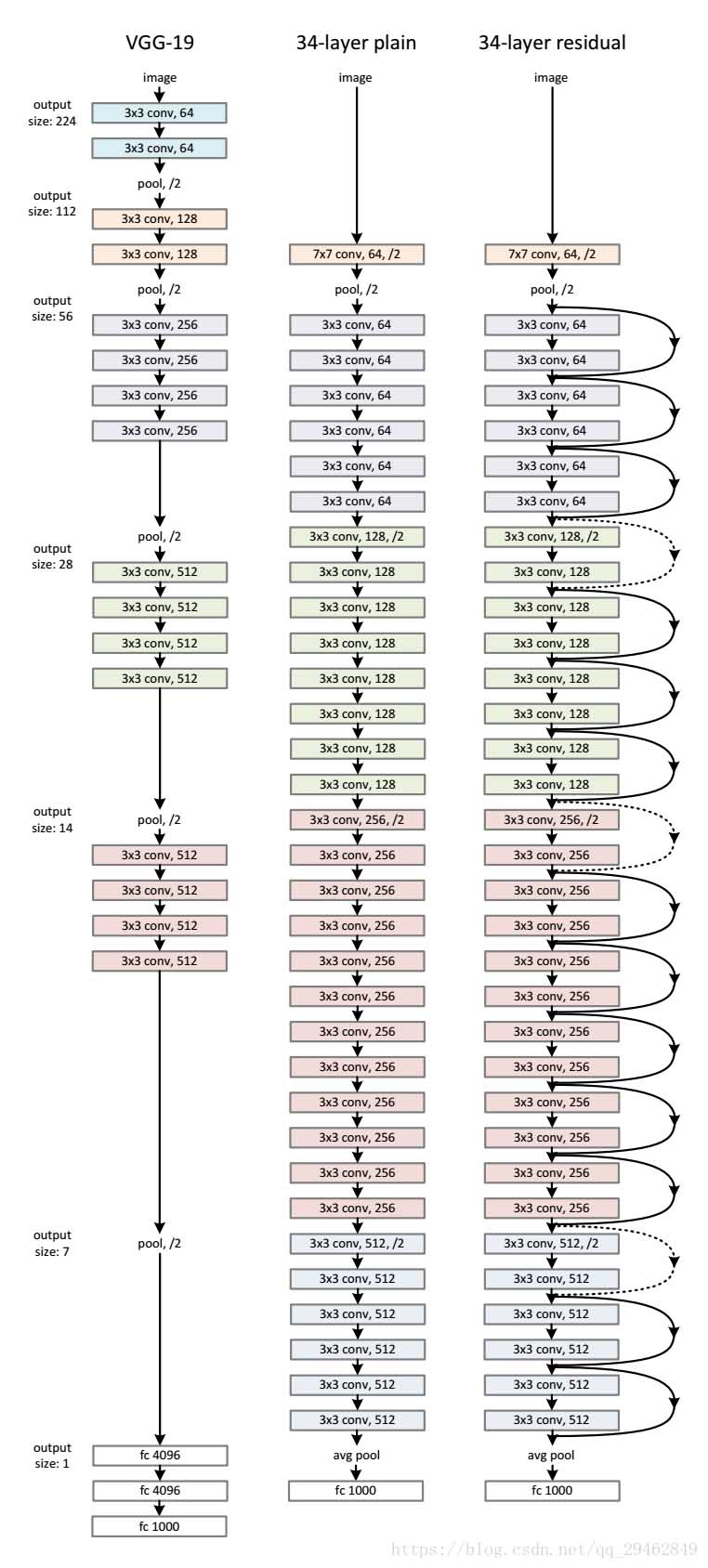
实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采用计算方式为H(x)=F(x)+x
虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x128的特征图,通道不同,采用的计算方式为H(x)=F(x)+Wx,其中W是卷积操作,用来调整x维度的。
根据输入和输出尺寸是否相同,又分为identity_block和conv_block,每种block有上图两种模式,三卷积和二卷积,三卷积速度更快些,因此在这里选择该种方式。
具体实现见如下代码:
#tensorflow基于mnist数据集上的VGG11网络,可以直接运行
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
#tensorflow基于mnist实现VGG11
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
#x=mnist.train.images
#y=mnist.train.labels
#X=mnist.test.images
#Y=mnist.test.labels
x = tf.placeholder(tf.float32, [None,784])
y = tf.placeholder(tf.float32, [None, 10])
sess = tf.InteractiveSession()
def weight_variable(shape):
#这里是构建初始变量
initial = tf.truncated_normal(shape, mean=0,stddev=0.1)
#创建变量
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#在这里定义残差网络的id_block块,此时输入和输出维度相同
def identity_block(X_input, kernel_size, in_filter, out_filters, stage, block):
"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
kernel_size -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
training -- train or test
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
block_name = 'res' + str(stage) + block
f1, f2, f3 = out_filters
with tf.variable_scope(block_name):
X_shortcut = X_input
#first
W_conv1 = weight_variable([1, 1, in_filter, f1])
X = tf.nn.conv2d(X_input, W_conv1, strides=[1, 1, 1, 1], padding='SAME')
b_conv1 = bias_variable([f1])
X = tf.nn.relu(X+ b_conv1)
#second
W_conv2 = weight_variable([kernel_size, kernel_size, f1, f2])
X = tf.nn.conv2d(X, W_conv2, strides=[1, 1, 1, 1], padding='SAME')
b_conv2 = bias_variable([f2])
X = tf.nn.relu(X+ b_conv2)
#third
W_conv3 = weight_variable([1, 1, f2, f3])
X = tf.nn.conv2d(X, W_conv3, strides=[1, 1, 1, 1], padding='SAME')
b_conv3 = bias_variable([f3])
X = tf.nn.relu(X+ b_conv3)
#final step
add = tf.add(X, X_shortcut)
b_conv_fin = bias_variable([f3])
add_result = tf.nn.relu(add+b_conv_fin)
return add_result
#这里定义conv_block模块,由于该模块定义时输入和输出尺度不同,故需要进行卷积操作来改变尺度,从而得以相加
def convolutional_block( X_input, kernel_size, in_filter,
out_filters, stage, block, stride=2):
"""
Implementation of the convolutional block as defined in Figure 4
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
kernel_size -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
training -- train or test
stride -- Integer, specifying the stride to be used
Returns:
X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
block_name = 'res' + str(stage) + block
with tf.variable_scope(block_name):
f1, f2, f3 = out_filters
x_shortcut = X_input
#first
W_conv1 = weight_variable([1, 1, in_filter, f1])
X = tf.nn.conv2d(X_input, W_conv1,strides=[1, stride, stride, 1],padding='SAME')
b_conv1 = bias_variable([f1])
X = tf.nn.relu(X + b_conv1)
#second
W_conv2 =weight_variable([kernel_size, kernel_size, f1, f2])
X = tf.nn.conv2d(X, W_conv2, strides=[1,1,1,1], padding='SAME')
b_conv2 = bias_variable([f2])
X = tf.nn.relu(X+b_conv2)
#third
W_conv3 = weight_variable([1,1, f2,f3])
X = tf.nn.conv2d(X, W_conv3, strides=[1, 1, 1,1], padding='SAME')
b_conv3 = bias_variable([f3])
X = tf.nn.relu(X+b_conv3)
#shortcut path
W_shortcut =weight_variable([1, 1, in_filter, f3])
x_shortcut = tf.nn.conv2d(x_shortcut, W_shortcut, strides=[1, stride, stride, 1], padding='VALID')
#final
add = tf.add(x_shortcut, X)
#建立最后融合的权重
b_conv_fin = bias_variable([f3])
add_result = tf.nn.relu(add+ b_conv_fin)
return add_result
x = tf.reshape(x, [-1,28,28,1])
w_conv1 = weight_variable([2, 2, 1, 64])
x = tf.nn.conv2d(x, w_conv1, strides=[1, 2, 2, 1], padding='SAME')
b_conv1 = bias_variable([64])
x = tf.nn.relu(x+b_conv1)
#这里操作后变成14x14x64
x = tf.nn.max_pool(x, ksize=[1, 3, 3, 1],
strides=[1, 1, 1, 1], padding='SAME')
#stage 2
x = convolutional_block(X_input=x, kernel_size=3, in_filter=64, out_filters=[64, 64, 256], stage=2, block='a', stride=1)
#上述conv_block操作后,尺寸变为14x14x256
x = identity_block(x, 3, 256, [64, 64, 256], stage=2, block='b' )
x = identity_block(x, 3, 256, [64, 64, 256], stage=2, block='c')
#上述操作后张量尺寸变成14x14x256
x = tf.nn.max_pool(x, [1, 2, 2, 1], strides=[1,2,2,1], padding='SAME')
#变成7x7x256
flat = tf.reshape(x, [-1,7*7*256])
w_fc1 = weight_variable([7 * 7 *256, 1024])
b_fc1 = bias_variable([1024])
h_fc1 = tf.nn.relu(tf.matmul(flat, w_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, w_fc2) + b_fc2
#建立损失函数,在这里采用交叉熵函数
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#初始化变量
sess.run(tf.global_variables_initializer())
print("cuiwei")
for i in range(2000):
batch = mnist.train.next_batch(10)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y: batch[1], keep_prob: 0.5})
以上这篇tensorflow实现残差网络方式(mnist数据集)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容