简述 zookeeper 基于 Zab 协议实现选主及事务提交
WindWant 人气:1Zab 协议:zookeeper 基于 Paxos 协议的改进协议 zookeeper atomic broadcast 原子广播协议。
zookeeper 基于 Zab 协议实现选主及事务提交。
一、为什么需要选主?
选主是复杂分布式服务的一个特有机制,旨在保障系统数据的一致性。
分布式服务一般对于数据的存储形式是:每个节点都保存全量数据,每个节点都可以对外提供“一致”的服务,这就涉及到不同节点间的数据同步。
我们所说的可能的数据不一致主要是由数据变更过程引发,因为它涉及服务内所有节点的数据更新。对于 zookeeper, 选主便是保障服务内数据变更触发,控制及变更后服务各节点数据的一致性的一个重要环节。
二、怎么选主?
zookeeper 集群内节点通常处于以下几种状态:
1、LEADING:
也就是我们所说的领导者所处的状态,领导者负责处理接收到的数据变更请求及将变更同步到各个从节点。此处需要注意的是,即使变更数据请求发送到了从节点,从节点也会将其转发到主节点。
2、FOLLOWING:
通常情况下从节点所处的状态,从节点主要负责读请求处理及参与集群投票,选举。
3、LOOKING:
是一种选主过程中的特有状态,当前服务无主节点时,则所有节点切换为 LOOKING 状态,遵循 Zab 协议,相互通信以选举出主节点。过程完成,则转换到相应的 LEADING 或者 FOLLOWING 状态。
选主过程发生在服务初始启动及运行过程中主节点故障两种情景下。在正式介绍选主过程之前,先就几个涉及到的名词作简要概述:
1、法定数量:
设定的为了确定协议一致性结果,必须有多少参与方意见达成一致。主要用于确认服务可用或失败、确认数据更新事务成功等。
2、领导者选举通知:
选主过程中,各节点间进行通信的消息。主要包括两部分,一个是节点自身的标识sid,会随着每次重启自增;另一个是 zookeeper 事务id,简称 zxid,标识对 zookeeper 的操作指令顺序、大小(遵循 happend before 原则)。
选主过程:
1、服务内的每个节点向其它节点发出自己的投票信息(sid,zxid),如下图:
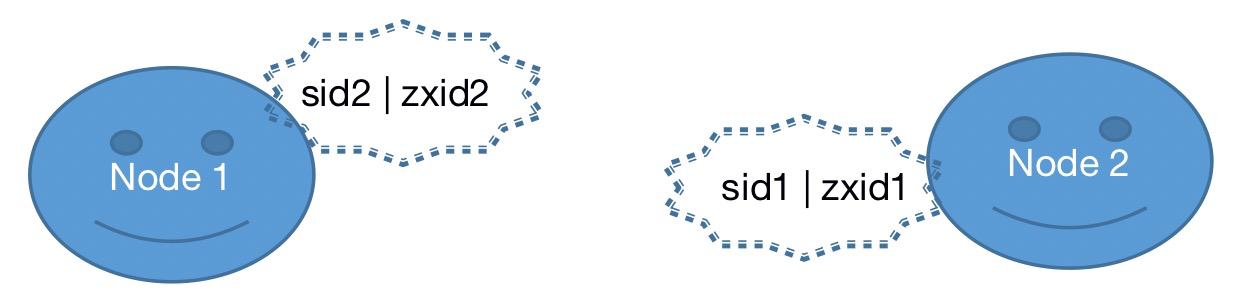
Node1 接收到 Node2 发送的选举信息,会对比自己的投票信息,当 (zxid1 > zxid2 || zxid1 == zxid2 && sid1 > sid2) 则保持自己的信息 sid 及 zxid 不变,否则的话则将自身的 sid 及 zxid 更新为 Node2 的 sid 和 zxid。
2、当服务内某个节点获得了超过法定人数的投票,则选主结束。
主节点进入 LEADING 状态,其它节点进入 FOLLOWING 状态,同时开始发起数据同步(从节点在同步数据前无法对外提供服务)。
三、关于事务提交
Zab 协议包含两种模式:恢复模式及广播模式。
前面我们提到过恢复模式下的应用,服务初始及主节点故障情况下的领导者选举,恢复模式结束于领导者被选出及超过法定数量的从节点数据达到同步。
主节点负责处理写请求及发送广播消息,且需要说明的是,广播模式下只有主节点可以发送广播消息,如果某个从节点需要发送广播信息,也需要通过主节点进行。
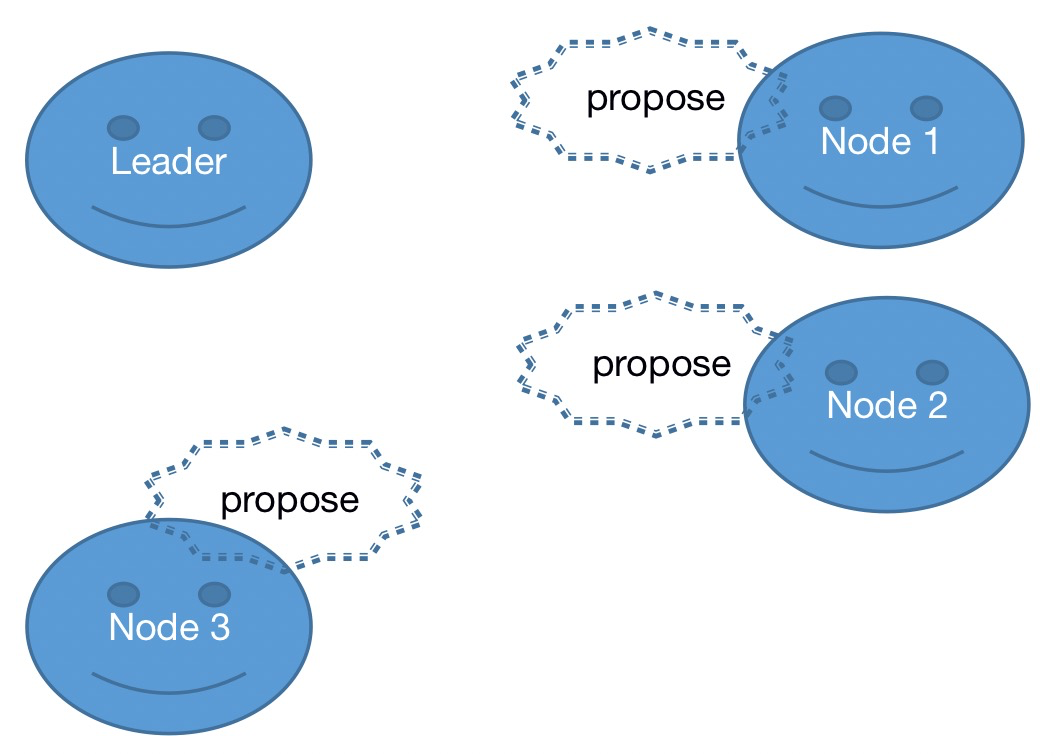
主节点基于Zab协议协商完成写变更事务提交:
1、主节点广播发送事务提交提议
2、从节点接收到提议后,回复确认信息通知主节点
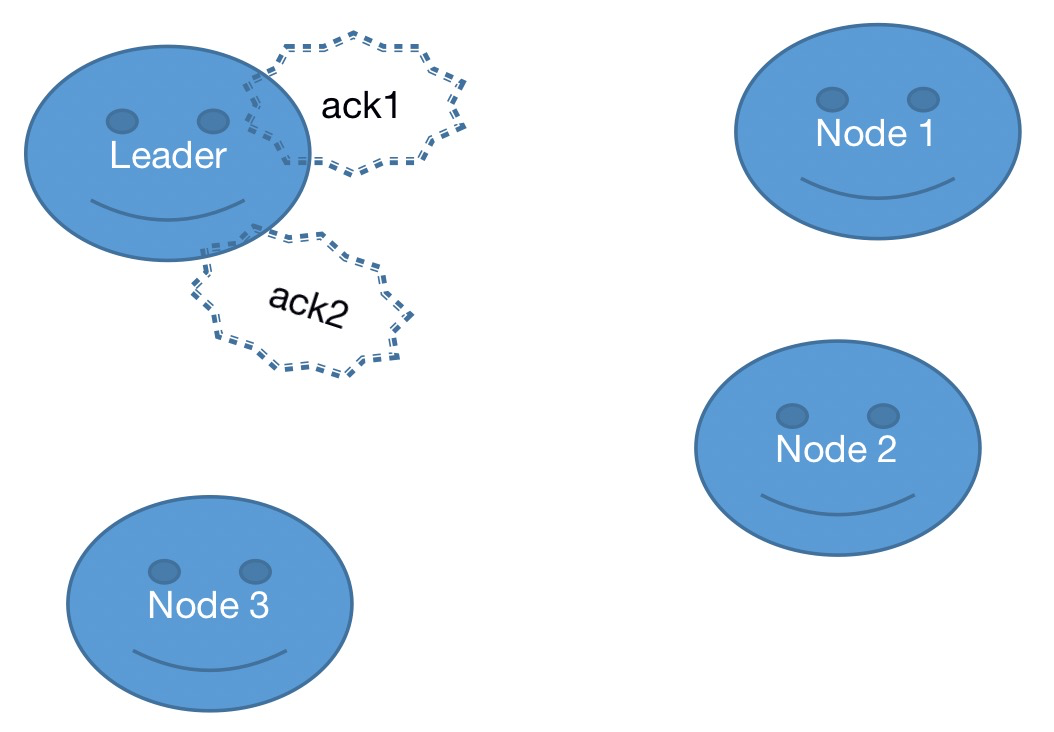
3、主节点接收到超过法定数量从节点确认信息后,广播发送事务提交命令到从节点

zookeeper 服务实现中很重要的一点:顺序性。顺序请求,顺序响应;主节点事务顺序提交,从节点按顺序响应事务等等。
加载全部内容