深度学习中的一些组件及使用技巧
FinTecher 人气:1【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图]
【补充说明】深度学习有多火,我就不多说了。本文主要介绍深度学习项目实践过程中可能遇到的一些组件及使用技巧!
一、Optimizor优化器选择
1. 梯度下降:经典
梯度下降的通用计算公式如下:


其中,

梯度下降主要包含三种梯度下降:
(1)批量梯度下降(Batch Gradient Descent)
- 使用所有的训练样本来更新每次迭代中的模型参数
(2)随机梯度下降(Stochastic Gradient Descent)
- 在每次迭代中,仅使用单个训练样本更新参数(训练样本通常是随机选择的)
(3)小批量梯度下降(Mini-Batch Gradient Descent):这个最常用
- 训练时不是使用所有的样本,而是取一个批次的样本来更新模型参数
- 小批量梯度下降试图在随机梯度下降的稳健性和批量梯度下降的效率之间找到平衡
梯度下降的缺点:
- 选择合适的learning rate比较困难
- 对所有的参数更新均使用同样的learning rate
- 可能被困在鞍点,容易产生局部最优,不能达到全局最优
2. Momentum
Momentum是模拟物理里动量的概念,公式如下:


其中,

Momentum有如下特点:
- 下降初期时,由于下降方向和梯度方向一致,而使t时刻的动量和变化量变大,从而达到加速的目的
- 下降中后期时,在局部最小值来回震荡的时候,使得更新幅度增大,跳出陷阱
- 在梯度改变方向的时候,能够减少更新
总的来说,Momentum可以加速SGD算法的收敛速度,并且降低SGD算法收敛时的震荡。
3. Nesterov
将上一节中的公式展开可得:
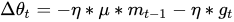
可以看出,Momentum并没有直接改变当前梯度。Nesterov的改进就是让之前的动量直接影响当前的动量。即:

其中,加上Nesterov项后,梯度在大的跳跃后,再计算当前梯度进行校正。
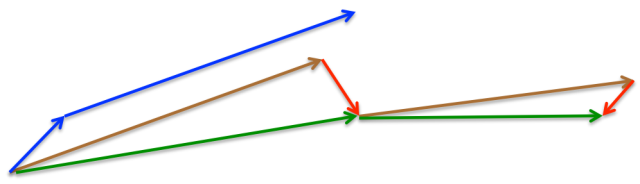
Nesterov有如下特点:
- 对于Momentum,首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量)
- 对于Nesterov,首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),然后计算梯度进行校正(绿色梯向量)
总的来说,Nesterov项在梯度更新时做了一个校正,避免前进太快,同时提高灵敏度。
4. Adagrad
Adagrad对学习率进行了一个约束。即:


其中,对

Adagrad有如下特点:
- 前期
- 后期
- 高频特征更新步长较小,低频特征更新较大,适合处理稀疏梯度
- 能够自适应学习率,避免了手动调整学习率的麻烦
Adagrad的缺点:
- 由公式可以看出,仍依赖于人工设置一个全局学习率
- 中后期,分母上梯度平方的累加将会越来越大,使
,使得训练提前结束
5. Adadelta
Adadelta是对Adagrad的扩展,它主要解决了adagrad算法单调递减学习率的问题。Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:


其中,Adadelta还是依赖于全局学习率,但是做了一定处理,经过近似牛顿迭代法之后:

其中,
Adadelta还有如下特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动
6. RMSprop
RMSprop可以算作Adadelta的一个特例,同样是用于解决adagrad算法学习率消失的问题。
当

如果再求根的话,就变成了RMS(均方根):

此时,这个RMS就可以作为学习率

RMSprop有如下特点:
- 依然依赖于全局学习率
- 是Adagrad的一种发展,也是Adadelta的变体,效果趋于二者之间
- 适合处理非平稳目标
7. Adam:常用
Adam本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:




其中,






Adam有如下特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化,适用于大数据集和高维空间
8. 其他
例如Adamax(Adam的一种变体)、Nadam(类似于带有Nesterov动量项的Adam)等,这里不展开了。
9. 经验总结
- 对于稀疏数据,使用学习率可自适应的优化方法(例如Adagrad/Adadelta/RMSprop/Adam等),且最好采用默认值
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法

二、激活函数选择
1. 常用的激活函数
发现这么写下去,篇幅太大了,所以找到一张图,概括一下吧:

常用的主要是这些吧,各种激活函数的特点看图也显而易见,其他的(例如PReLU等)就不拓展了。
2. 经验总结
- 对于输出层:二分类任务一般选用Sigmoid输出,多分类任务一般选用Softmax输出,回归任务一般选用线性输出。
- 对于中间隐层:优先选择Relu激活函数(Relu可以有效解决Sigmoid和tanh出现的梯度弥散问题,且能更快收敛)。
三、防止过拟合
1. 数据集扩充
即增大训练集的规模,实在难以获得新数据也可以使用数据集增强的方法。
例如可以对图像数据集采用水平/垂直旋转/翻转、随机改变亮度和颜色、随机模糊图像、随机裁剪等方法进行数据集增强。

2. L1/L2正则化
正则化,就是在原来的loss function的基础上,加上了一些正则化项或者称为模型复杂度惩罚项。
以线性回归为例,优化目标:
min 
加上L1正则项(lasso回归):
min 
加上L2正则项(岭回归):
min 
其中,L1范数更容易得到稀疏解(解向量中0比较多);L2范数能让解比较小(靠近0),但是比较平滑(不等于0)。
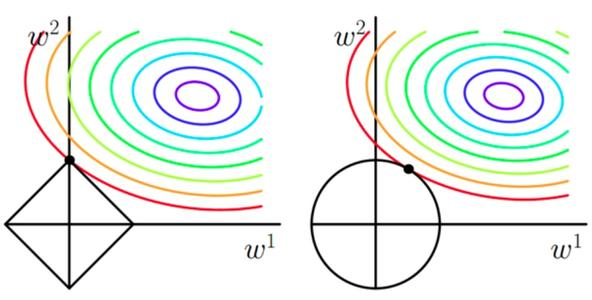
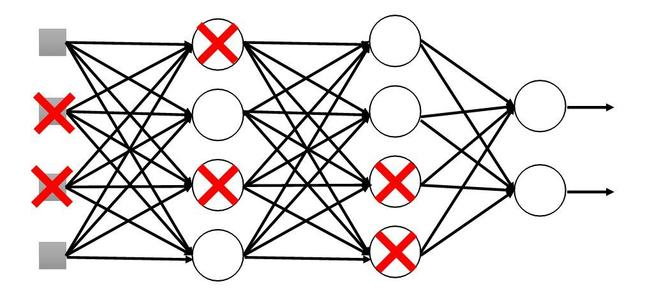
3. Dropout
Dropout提供了一个简单的方法来提升性能。其实相当于做简单的Ensemble,但训练速度会慢一些。
4. 提前终止Early stopping

5. 交叉验证
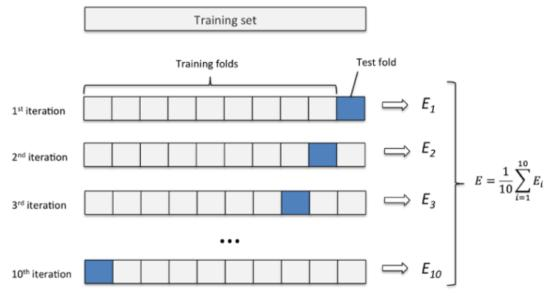
剩下就是选择合适的模型和网络结构了,甚至可以采用多模型融合等思路。
四、防止梯度消失/爆炸
1. 使用合适的激活函数:ReLU等
解决Sigmoid函数存在的梯度消失/爆炸问题。
2. 预训练加微调:DBN等
Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”。在预训练完成后,再对整个网络进行“微调”。
3. 梯度剪切、正则
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。另外一种解决梯度爆炸的手段是采用权重正则化,比较常见的是L1正则和L2正则,以上已经提到了。
4. Batch Normalization
对每一层的输出做scale和shift的方法,通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到接近均值为0方差为1的标准正太分布,即严重偏离的分布强制拉回比较标准的分布。这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生。而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
5. 残差结构 Resnet
如果你希望训练一个更深更复杂的网络,那么残差块绝对是一个重要的组件,它可以让你的网络训练的更深。
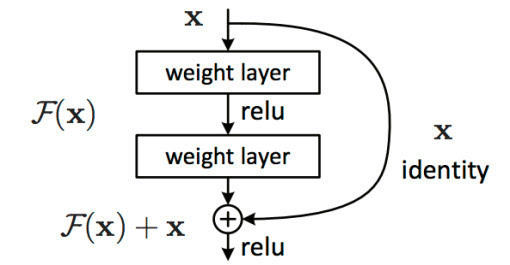
6. 采用LSTM等模型
我在序列模型专题有介绍到LSTM,这里不再赘述。
五、权值初始化
1. 随机初始化
有一些常用的初始化方法:
- 直接用0.02*randn(num_params)来初始化,当然别的值也可以。
- 依次初始化每一个weight矩阵,用init_scale / sqrt(layer_width) * randn,init_scale可以被设置为0.1或者1。
初始化很重要,知乎大佬们的惨痛教训:
- 用normal初始化CNN的参数,最后acc只能到70%多,仅仅改成xavier,acc可以到98%。
- 初始化word embedding,使用了默认的initializer,速度慢且效果不好。改为uniform,训练速度和结果也飙升。
2. 迁移学习
可以采用迁移学习预训练的方式。说到这里,我之后想写一个迁移学习的专题。
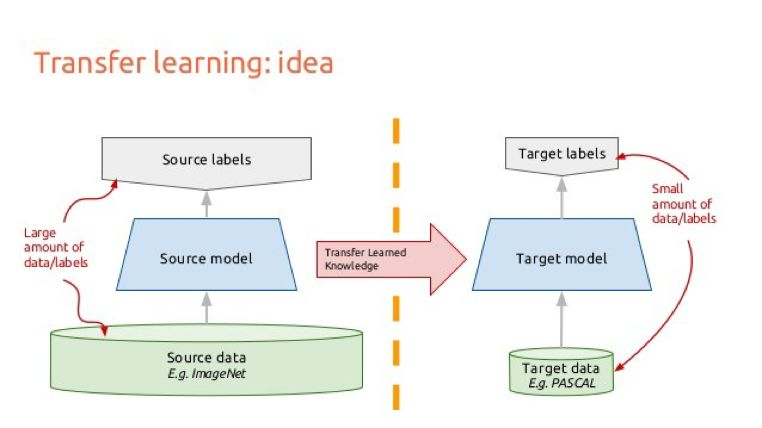
六、数据预处理
1. 标准化/归一化处理
就是0均值和1方差化。主要是为了公平对待每个特征、使优化过程变得平稳、消除量纲影响等。
2. Shuffle处理
在训练的过程中,如果数据很整齐,那每次学习到的特征都是与某一个特征相关,会让学习效果有所偏差。
因此,一般在训练的过程中,建议要将数据打乱,这样才能够更好的实现泛化能力。
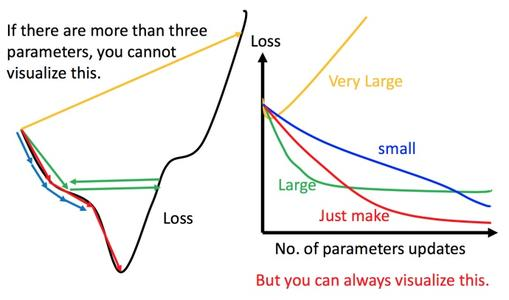
七、学习率 learning rate
一般建议从一个正常大小的学习率开始,朝着终点不断缩小。
八、批次大小 batch_size
batch_size会影响优化过程,建议值取64和128等,太小训练速度慢,太大容易过拟合。
九、损失函数 Loss
1. 多分类问题选用Softmax+交叉熵
当Sigmoid函数和MSE一起使用时会出现梯度消失。原因如下:
MSE对参数的偏导:
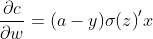

corss-entropy对参数的偏导:
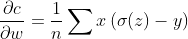

以上,相对于Sigmoid求损失函数,在梯度计算层面上,交叉熵对参数的偏导不含对Sigmoid函数的求导,而均方误差MSE等则含有Sigmoid函数的偏导项。同时,Sigmoid的值很小或者很大时梯度几乎为零,这会使得梯度下降算法无法取得有效进展,交叉熵则避免了这一问题。
为了弥补Sigmoid 型函数的导数形式易发生饱和的缺陷,可以引入Softmax作为预测结果,再计算交叉熵损失。由于交叉熵涉及到计算每个类别的概率,所以在神经网络中,交叉熵与Softmax函数紧密相关。
十、其他
例如训练时可以先用一小部分数据集跑,看看损失的变化趋势,有助于更快找到错误并调整网络结构等技巧。
另外,看到一张不同参数对于网络训练的影响程度图,分享一下:

最后,虽然有很多组件和技巧可以方便使用(框架中一般都封装好了),但是还是需要注意各组件、技巧之间的灵活组合,才能取得最佳结果。
如果您对数据挖掘感兴趣,欢迎浏览我的另几篇博客:数据挖掘比赛/项目全流程介绍
如果你对智能推荐感兴趣,欢迎先浏览我的另几篇随笔:智能推荐算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
加载全部内容