Spring源码解析02:Spring IOC容器之XmlBeanFactory启动流程分析和源码解析
你好,旧时光 人气:3一. 前言
Spring容器主要分为两类BeanFactory和ApplicationContext,后者是基于前者的功能扩展,也就是一个基础容器和一个高级容器的区别。本篇就以BeanFactory基础容器接口的默认实现类XmlBeanFactory启动流程分析来入门Spring源码的学习。
二. 概念要点
1. 概念定义
BeanDefinition:Bean元数据描述,Bean在Spring IOC容器中的抽象,是Spring的一个核心概念 DefaultListableBeanFactory : Spring IOC容器的实现,可以作为一个独立使用的容器, Spring IOC容器的始祖 XmlBeanFactory:继承自DefaultListableBeanFactory,与其不同点在于XmlBeanFactory中使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取 ApplicationContext: 高级容器定义接口,基于BeanFactory添加了扩展功能,如ResourceLoader、MessageSource、ApplicationEventPublisher等
2. 糟糕!XmlBeanFactory被废弃了
对Spring有些了解的应该XmlBeanFactory已经过时了。没错,本篇要讲的XmlBeanFactory在Spring3.1这个很久远版本就开始过时了。
@deprecated as of Spring 3.1 in favor of {@link DefaultListableBeanFactory}

取而代之的写法如下
ClassPathResource resource=new ClassPathResource("spring-config.xml");
DefaultListableBeanFactory beanFactory=new DefaultListableBeanFactory();
XmlBeanDefinitionReader beanDefinitionReader=new XmlBeanDefinitionReader(beanFactory);
beanDefinitionReader.loadBeanDefinitions(resource);
概括DefaultListableBeanFactory + XmlBeanDefinitionReader 取代了 XmlBeanFactory容器的创建和初始化,可以联想到通过组合的方式灵活度是比XmlBeanFactory高的,针对不同的资源读取组合的方式只需替换不同的读取器BeanDefinitionReader就可以了,而XmlBeanFactory中的读取器XmlBeanDefinitionReader限定其只能读取XML格式的文件资源,所以至于XmlBeanFactory被废弃的原因可想而知。
3. XmlBeanFactory?!XML,你会XML解析吗?
<?xml version="1.0" encoding=" UTF-8" standalone="yes"?><root>
<code>0</code>
<message>调用成功</message>
</root>
附上DOM4J解析的代码
String xml="<?xml version=\"1.0\" encoding=\" UTF-8\" standalone=\"yes\"?><root>\n" +
"<code>0</code>\n" +
"<message>调用成功</message>\n" +
"</root>";
Document document = DocumentHelper.parseText(xml);
Element root = document.getRootElement();
String code = root.elementText("code");
String message =root.elementText("message");
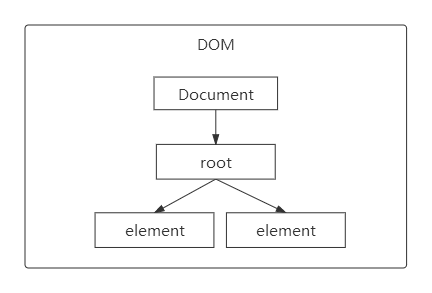
XML文档被解析成DOM树,其中Document是整个DOM的根节点,root为根元素,由根元素一层一层向下解析element元素,容器启动解析XML流程就是这样。
三. XmlBeanFactory启动流程分析
XmlBeanFactory容器启动就两行代码
ClassPathResource resource = new ClassPathResource("spring-config.xml");
XmlBeanFactory beanFactory = new XmlBeanFactory(resource);
怎么样?看似简单就证明了Java封装的强大,但背后藏了太多。 这里就送上XmlBeanFactory启动流程图,对应的就是上面的两行代码。

这是啥?!看得头晕的看官老爷们别急着给差评啊(瑟瑟发抖中)。这里精简下,想快速理解的话直接看精简版后的,想深入到细节建议看下上面的时序图。
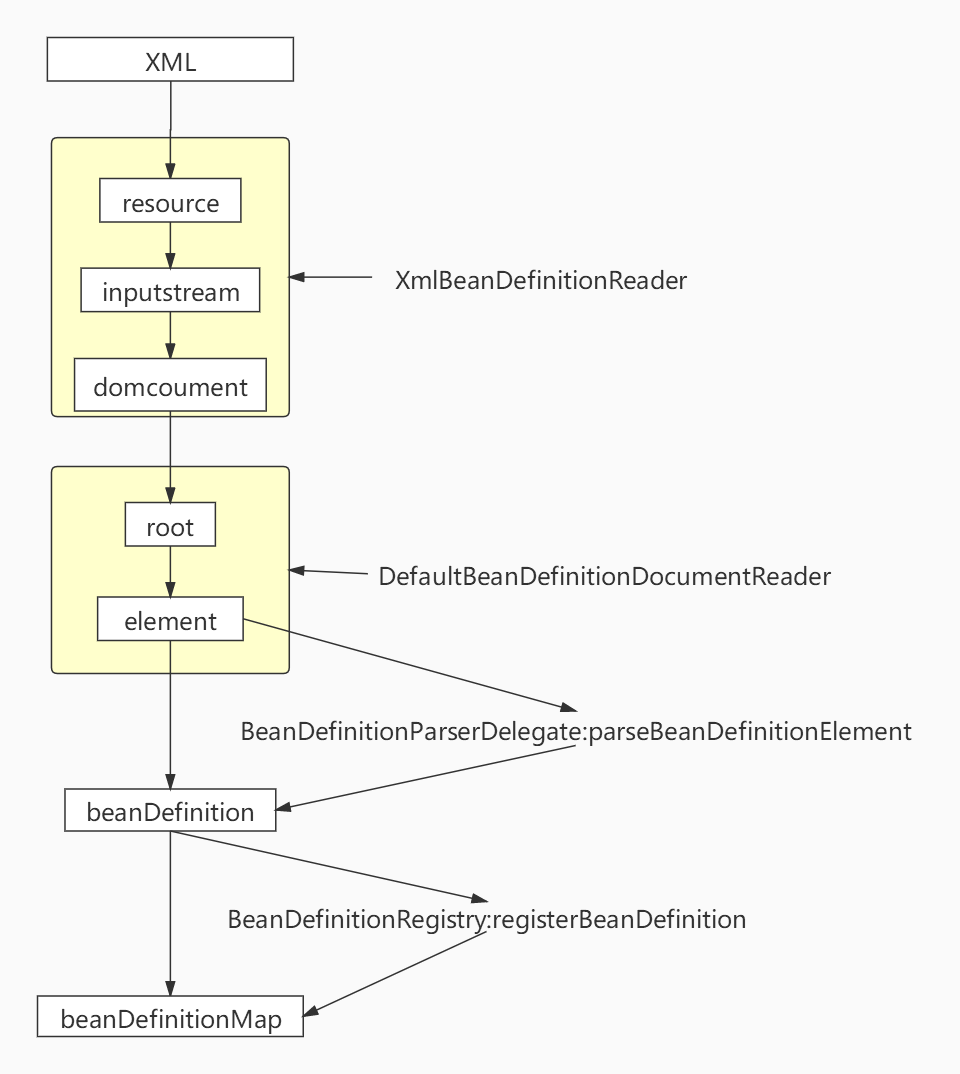 整个就是bean的加载阶段。通过解析XML中的标签元素生成beanDefinition注册到beanDefinitionMap中。
整个就是bean的加载阶段。通过解析XML中的标签元素生成beanDefinition注册到beanDefinitionMap中。
四. XmlBeanFactory启动源码解析
按照XmlBeanFactory启动流程的先后顺序整理的关键性代码索引列表,其中一级索引为类,二级索引对应其类下的方法。符号 ---▷表示接口的实现。建议可以观察方法索引的参数变化(资源转换)来分析整个流程,来加深对流程的理解。
XmlBeanFactory
XmlBeanFactory(Resource resource)
XmlBeanDefinitionReader
loadBeanDefinitions(Resource resource) doLoadBeanDefinitions(InputSource inputSource, Resource resource) registerBeanDefinitions(Document doc, Resource resource)
DefaultBeanDefinitionDocumentReader ---▷ BeanDefinitionDocumentReader
registerBeanDefinitions(Document doc, XmlReaderContext readerContext) doRegisterBeanDefinitions(Element root) parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate)
BeanDefinitionParserDelegate
parseBeanDefinitionElement(Element ele) decorateBeanDefinitionIfRequired( Element ele, BeanDefinitionHolder originalDef,...)
DefaultListableBeanFactory ---▷ BeanDefinitionRegistry
registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
好了,当你心里对这个流程有个大概的样子之后,这里就可以继续走下去。建议还是很模糊的同学自重,避免走火入魔想对我人身攻击的。下面就每个方法重要的点一一解析,严格按照方法的执行先后顺序来说明。
1.1 XmlBeanFactory(Resource resource)
功能概述: XmlBeanFactory的构造方法,整个容器启动的入口,完成bean工厂的实例化和BeanDefinition加载(解析和注册)。
/**
* XmlBeanFactory
**/
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
// 加载(解析注册)BeanDefinition
this.reader.loadBeanDefinitions(resource);
}
知识点:
Resource:Resource接口是Spring资源访问策略的抽象,,而具体的资源访问方式由其实现类完成,如类路径资源(ClassPathResource)、文件(FileSystemResource)、URL资源(UrlResource)、InputStream资源(InputStreamResource)、Byte数组(ByteArrayResource),根据不同的类型的资源使用对应的访问策略,明明白白的策略模式。
2.1 loadBeanDefinitions(Resource resource)
功能概述: 上面根据ClassPathResource资源访问策略拿到了资源Resource,这里将Resource进行特定的编码处理,然后将编码后的Resource转换成SAX解析XML文件所需要的输入源InputSource。
/**
* XmlBeanDefinitionReader
**/
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 把从XML文件读取的Resource资源进行编码处理
return loadBeanDefinitions(new EncodedResource(resource));
}
/**
* XmlBeanDefinitionReader
**/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
...
// 完成resource->inputStream->inputSource转换,使用SAX方式接收输入源InputSource解析XML
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 执行加载BeanDefinition
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
...
}
知识点:
XML解析两种方式:SAX(Simple API for XML)和DOM(Document Object Model),区别在于SAX按照顺序逐行读取,查找到符合条件即停止,只能读不能修改,适合解析大型XML;DOM则是一次性读取到内存建立树状结构,占用内存,不仅能读还能修改XML。Spring采用的SAX方式来解析XML。
2.2 doLoadBeanDefinitions(InputSource inputSource, Resource resource)
功能概述: 获取DOM Document对象,XmlBeanDefinitionReader本身没有对文档读取的能力,而是委托给DocumentLoader的实现类DefaultDocumentLoader去读取输入源InputResource从而得到Document对象。获得Document对象后,接下来就是BeanDefinition的解析和注册。
/**
* XmlBeanDefinitionReader
**/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
...
try {
// inputSource->DOM Document
Document doc = doLoadDocument(inputSource, resource);
int count = registerBeanDefinitions(doc, resource);
return count;
}
...
}
知识点:
Document是DOM的根节点,提供对文档数据访问的入口。
2.3 registerBeanDefinitions(Document doc, Resource resource)
功能概述: 解析DOM Document成容器的内部数据接口BeanDefinition并注册到容器内部。
/**
* XmlBeanDefinitionReader
**/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 已注册的BeanDefinition的数量
int countBefore = getRegistry().getBeanDefinitionCount();
// DOM Document->BeanDefinition,注册BeanDefinition至容器
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 返回此次注册新增的BeanDefinition数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
知识点:
BeanDefinitionDocumentReader是接口,实际完成对DOM Document解析的是其默认实现类DefaultBeanDefinitionDoucumentReade。 createReaderContext(resource)创建XmlReaderContext上下文,包含了XmlBeanDefinitionReader读取器和NamespaceHandlerResolver 命名空间解析器。
3.1 registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
功能概述: 在此之前一直 是XML加载解析的准备阶段,在获取到Document对象之后就开始真正的解析了。
/**
* DefaultBeanDefinitionDocumentReader
**/
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
doRegisterBeanDefinitions(doc.getDocumentElement());
}
3.2 doRegisterBeanDefinitions(Element root)
功能概述: 解析Element,DefaultBeanDefinitionDoucumentReader同样不具有解析Element的能力,委托给BeanDefinitionParserDelegate执行。
/**
* DefaultBeanDefinitionDocumentReader
**/
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
...
// 解析前处理,留给子类实现
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
// 解析后处理,留给子类实现
postProcessXml(root);
this.delegate = parent;
}
知识点:
preProcessXml和postProcessXml里代码是空的,这两个方法是面向子类设计的,设计模式中的模板方法,也可以说是Spring的一个扩展点,后面有机会可以深入下细节。
3.3 parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate)
功能概述: 判别XML中Bean的声明标签是默认的还是自定义的,执行不同的解析逻辑。对于根节点或者子节点是默认命名空间采用parseDefaultElement,否则使用parseCustomElement对自定义命名空间解析。
/**
* DefaultBeanDefinitionDocumentReader
**/
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate){
// 对beans的处理
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
// 对默认的Bean标签解析
parseDefaultElement(ele, delegate);
}
else {
// 对自定义的Bean标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
知识点:
Spring中XML有两大类Bean的声明标签
默认声明标签:
<bean id="userService" class="com.fly4j.service.impl.UserServiceImpl"/>自定义声明标签: ·
<tx: annotation-driven />
怎么区分是默认命名空间还是自定义命名空间?
通过node.getNamespaceURI()获取命名空间并和Spring中固定的命名空间http://www.springframework.org/schema/beans进行比对,如果一致则默认,否则自定义。
3.4 parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate)
功能概述: 上面说到Spring标签包括默认标签和自定义标签两种。解析这两种方式分别不同。以下就默认标签进行说明BeanDefinitionParseDelegate对Bean标签元素的解析过程。
/**
* DefaultBeanDefinitionDocumentReader
**/
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
// import标签
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
// alias标签
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
// bean标签
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// beans标签
doRegisterBeanDefinitions(ele);
}
}
知识点:
Spring的4种默认标签举例:
import
<import resource="spring-config.xml"/>alias
<bean id="userService" class="com.fly4j.service.impl.UserServiceImpl"></bean>
<alias name="userService" alias="user" />bean
<beans>
<bean id="userService" class="com.fly4j.service.impl.UserServiceImpl"></bean>
</beans>beans
<beans>
<bean id="userService" class="com.fly4j.service.impl.UserServiceImpl"></bean>
</beans>
3.5 processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate)
功能概述: 在4中默认标签当中,其中核心的是对bean标签的解析。以下就对bean标签的解析来看解析过程。
/**
* DefaultBeanDefinitionDocumentReader
**/
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate){
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); // 参考4.1源码
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder); // 参考4.2源码
try {
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); // 参考5.1源码
}
...
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
流程解读:
DefaultBeanDefinitionDocumentReader委托BeanDefinitionParseDelegate的parseBeanDefinitionElement方法进行标签元素的解析。解析后返回BeanDefinitionHolder实例bdHolder,bdHolder实例包含了配置文件中的id、name、alias之类的属性。 返回的bdHolder不为空时,标签元素如果有自定义属性和自定义子节点,还需要再次对以上两个标签解析。具体逻辑参考4.2小节源码。 解析完成后,对bdHolder进行注册,使用BeanDefinitionReaderUtils.registerBeanDefinition()方法。具体逻辑参考5.1小节源码。 发出响应事件,通知相关监听器,bean已经解析完成。
4.1 registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
功能概述: 通过BeanDefinitionParseDelegate对Bean标签的解析,解析得到id和name这些信息封装到BeanDefinitionHolder并返回。
/**
* BeanDefinitionParseDelegate
**/
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
/**
* BeanDefinitionParseDelegate
**/
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 解析id属性
String id = ele.getAttribute(ID_ATTRIBUTE);
// 解析name属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
...
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
}
4.2 decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd)
功能概述: 4.1是对默认标签的属性解析,那如果标签有自定义属性和自定义子节点,这时就要通过decorateBeanDefinitionIfRequired解析这些自定义属性和自定义子节点。
/**
* BeanDefinitionParseDelegate
**/
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
Element ele, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {
BeanDefinitionHolder finalDefinition = originalDef;
// Decorate based on custom attributes first.
// 首先对自定义属性解析和装饰
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
// Decorate based on custom nested elements.
// 装饰标签下的自定义子节点
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
5.1 registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
功能概述: 通过beanName注册BeanDefinition至BeanDefinitionMap中去,至此完成Bean标签的解析,转换成Bean在容器中的数据结构BeanDefinition.
/**
* BeanDefinitionReaderUtils
**/
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
// 使用beanName注册BeanDefinition
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
// 使用别名注册BeanDefiniion
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
/**
* BeanDefinitionParseDelegate
**/
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
...
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
...
this.beanDefinitionMap.put(beanName, beanDefinition);
}else{
if (hasBeanCreationStarted()) {
// beanDefinitionMap是全局变量,会存在并发访问问题
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
...
}
五. 结语
总结Spring IOC基础容器XmlBeanFactory的启动流程概括如下:
执行XmlFactoryBean构造方法,执行加载BeanDefinition方法。 使用XmlBeanDefinitionReader读取器将资源Resource解析成DOM Document对象。 使用DefaultBeanDefinitionDocumentReader读取器从Document对象解析出 Element。 通过BeanDefinitionParserDelegate将Element转换成对应的BeanDefinition。 实现BeanDefinitionRegistry注册器将解析好的BeanDefinition注册到容器中的BeanDefitionMap里去
本篇就XmlBeanFactory容器启动流程分析和源码解析两个角度来对Spring IOC容器有个基础的认识。有了这篇基础,下篇就开始对Spring的扩展容器ApplicationContext进行分析。最后希望大家看完都有所收获,可以的话给个关注,感谢啦。
六. 附录
附上我编译好的Spring源码,版本是当前最新版本5.3.0,欢迎star
spring-framework-5.3.0编译源码
加载全部内容