Redis分布式锁存在的问题(推荐)
小黑说Java 人气:0在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。
有很多基于Redis实现的分布式锁方案或者库,但是有些库并没有解决分布式环境下的一些问题陷阱。
分布式锁的特点
分布式锁应该具备以下属性:
- 互斥 在同一时刻只有一个客户端可以持有锁;这是分布式锁的基本属性。
- 无死锁 每个锁请求都可以最终获得锁;即使是持有锁的客户端也会崩溃或遇到异常。 不同的实现
不同的实现
许多分布式锁实现都是基于分布式共识算法(Paxos、Raft、ZAB、Pacifica)的,比如基于Paxos的Chubby、基于ZAB的Zookeeper等,以及基于Raft的Consul。Redis的作者还提出了一种分布式锁,名为RedLock。
在接下来的章节中,我将展示如何基于Redis一步步实现分布式锁,并且在每一步中,我都试图解决分布式环境中可能发生的一个问题。
场景一:单实例Redis
为了简单起见,假设我们有两个客户端和一个Redis实例。一个简单的实现应该是:
boolean tryAcquire(String lockName, long leaseTime, OperationCallBack operationCallBack) {
// 加锁
boolean getLockSuccessfully = getLock(lockName, leaseTime);
if (getLockSuccessfully) {
try {
operationCallBack.doOperation();
} finally {
releaseLock(lockName);
}
return true;
} else {
return false;
}
}
boolean getLock(String lockName, long expirationTimeMillis) {
// 给当前线程创建一个唯一的lockValue
String lockValue = createUniqueLockValue();
try {
// 如果lockName没有加锁,则将lockName作为key保存到redis中,并指定过期时间
String response = storeLockInRedis(lockName, lockValue, expirationTimeMillis);
return response.equalsIgnoreCase("OK");
} catch (Exception exception) {
releaseLock(lockName);
throw exception;
}
}
void releaseLock(String lockName) {
String lockValue = createUniqueLockValue();
// 移除锁lockName,如果锁的值是lockValue
removeLockFromRedis(lockName, lockValue);
}这种方式有什么问题呢?
**假如客户端1请求服务端获取一个锁,并指定了锁超时时间,如果服务器响应的时间大于锁的超时时间,客户端1拿到的则是一个过期的锁,这时客户端2同时可以获取该锁进行业务操作。**这打破了分布式锁应该具备的相互排斥原则。
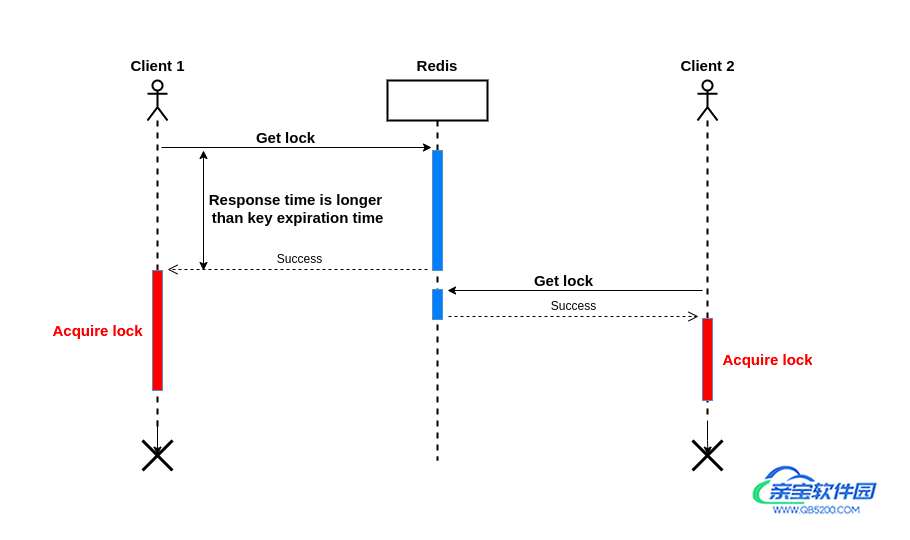
为了解决这个问题,我们应该给redis客户端设置一个请求超时时间timeout,这个时间应该小于锁的超时时间。
当时这还不能完全解决这个问题,假设Redis服务器因为掉电重启,则会有其他的问题,我们接下来看第二个场景。
场景二:单实例Redis的单点故障
如果你对Redis的数据持久化方案有所了解,那一定知道Redis有两种方式做数据持久化。
RDB(Redis Database):按指定的时间间隔将Redis的数据快照保存到磁盘。
AOF(Append-Only File):将服务器接收到的写操作指令记录下来,这些操作指令在服务重启时可以重新执行来恢复原始数据。
默认情况下,只会开启RDB模式,会按照如下方式配置:
save 900 1 save 300 10 save 60 10000
例如,第一行表示在900秒(15min)内如果有一次写操作,就将数据同步到数据文件。
所以在最坏的情况下,将一个加锁数据保存需要15分钟,如果在加锁成功时Redis服务掉电重启,则无法恢复内存中的加锁数据,其它客户端同样可以获取到相同的锁:
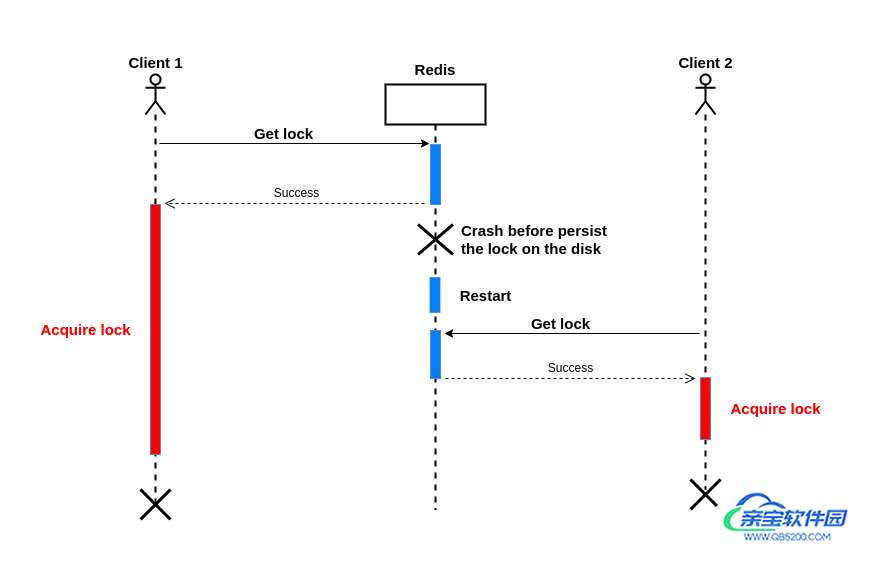
为了解决这个问题,我们必须使用fsync=always选项来启用AOF,然后在Redis中设置键。
注意,启用这个选项对Redis的性能有一定的影响,但我们需要这个选项以保持强一致性。
场景三:主从复制
在这个配置中,我们有一个或多个实例(通常称为从实例或副本),它们是主实例的精确副本。
默认情况下,Redis中的复制是异步的;这意味着主服务器不会等待命令被副本处理完毕再返回给客户端。
问题是在复制发生之前,主服务器可能出现故障,并发生故障转移;在此之后,如果另一个客户端请求获得锁,它将成功!或者假设存在一个临时的网络问题,因此其中一个副本没有接收到命令,网络变得稳定,故障转移很快发生;没有接收到命令的节点成为主节点。
最终,该锁将从所有实例中删除!下图说明了这种情况:
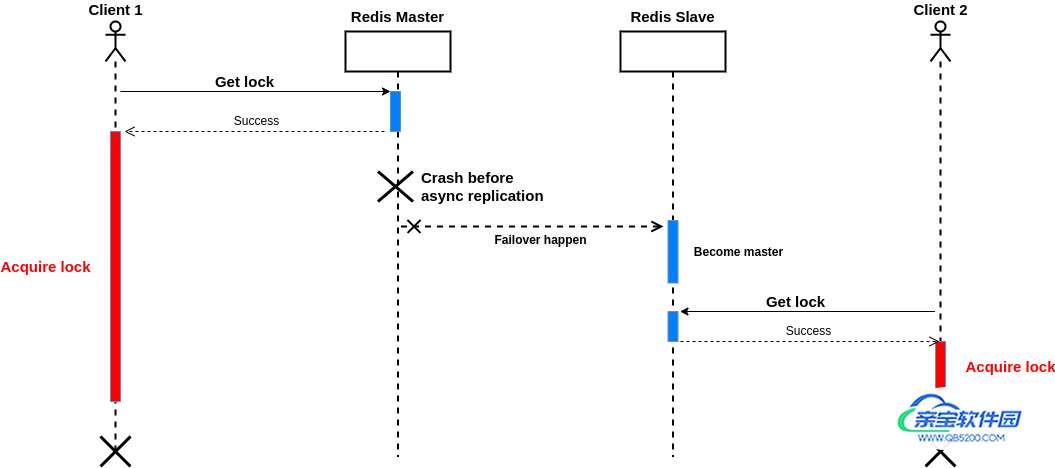
作为解决方案,有一个等待命令,等待指定数量的确认副本并返回副本的数量,承认之前的写命令发送等待命令,两个的情况下达到指定数量的副本或者超时。
例如,如果我们有两个副本,下面的命令最多等待1秒(1000毫秒)来从两个副本获得确认并返回:
WAIT 2 1000
到目前为止,一切顺利,但还有另一个问题;副本可能会丢失写入(由于错误的环境)。例如,一个副本在保存操作完成之前失败,同时主节点也失败,故障转移操作选择重新启动的副本作为新的主节点。在与新主服务器同步后,所有副本和新主服务器都没有旧主服务器中的密钥!
为了使所有的从服务器和主服务器完全一致,我们应该在获得锁之前为所有Redis实例启用fsync=always的AOF。
注意:在这种方法中,我们为了强一致性而破坏了可用性,AOF会有一定的性能损耗。
场景四:自动刷新的锁
在这个场景中,只要客户端是活的并且连接是正常的,就可以持有获取的锁。
我们需要一种机制来在锁到期之前刷新锁。我们还应该考虑不能刷新锁的情况;在这种情况下,必须立即退出。
此外,当锁的持有者释放锁时,其他客户端应该能够等待获得锁并进入临界区:

小结
我这里通过四个小场景,引出了四个问题,并给出相应的解决办法,但有一些重要的问题还没有解决我想在这里指出来,希望在以后使用分布式锁时作为参考。
不同节点之间的时钟漂移问题;获取锁之后客户端出现长线程的暂停或者进程暂停;一个客户端可能要等待很长时间才能获得锁,而与此同时,另一个客户端会立即获得锁;非公平锁。
许多三方库使用Redis提供分布式锁的服务,我们应该去了解它们是如何工作的以及可能发生的问题,在它们的正确性和性能之间做出权衡。
加载全部内容