java Disruptor构建高性能内存队列使用详解
码猿技术专栏 人气:0Java中有哪些队列
ArrayBlockingQueue使用ReentrantLockLinkedBlockingQueue使用ReentrantLockConcurrentLinkedQueue使用CAS
等等
我们清楚使用锁的性能比较低,尽量使用无锁设计。接下来就我们来认识下
Disruptor简单使用
github地址:github.com/LMAX-Exchan…
先简单介绍下:
- Disruptor它是一个开源的并发框架,并获得2011 Duke’s程序框架创新奖【Oracle】,能够在无锁的情况下实现网络的Queue并发操作。英国外汇交易公司LMAX开发的一个高性能队列,号称单线程能支撑每秒600万订单~
- 日志框架Log4j2 异步模式采用了Disruptor来处理
- 局限呢,他就是个内存队列,也就是说无法支撑分布式场景。
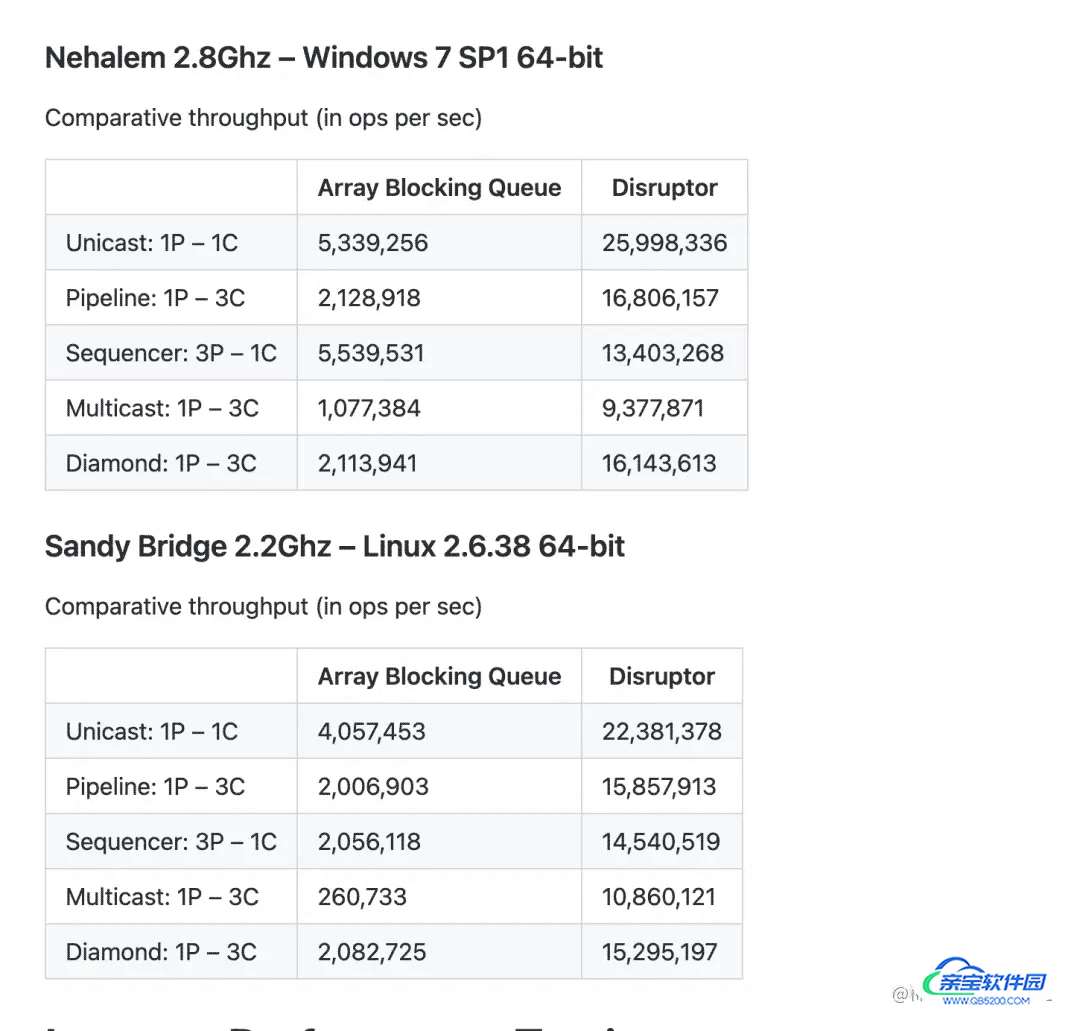
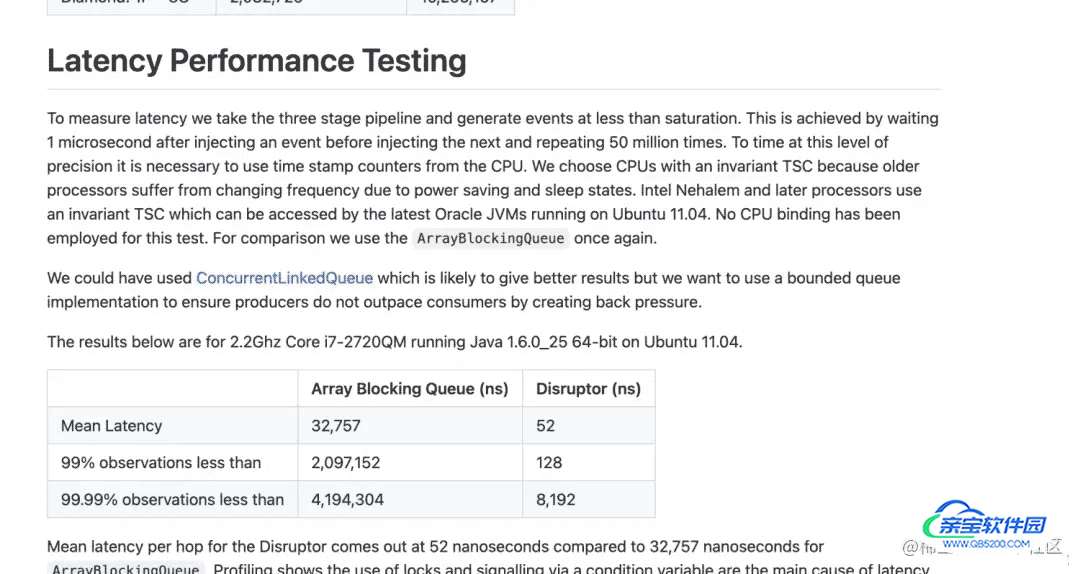
简单使用
数据传输对象
@Data
public class EventData {
private Long value;
}
消费者
public class EventConsumer implements WorkHandler<EventData> {
/**
* 消费回调
* @param eventData
* @throws Exception
*/
@Override
public void onEvent(EventData eventData) throws Exception {
Thread.sleep(5000);
System.out.println(Thread.currentThread() + ", eventData:" + eventData.getValue());
}
}
生产者
public class EventProducer {
private final RingBuffer<EventData> ringBuffer;
public EventProducer(RingBuffer<EventData> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void sendData(Long v){
// cas展位
long next = ringBuffer.next();
try {
EventData eventData = ringBuffer.get(next);
eventData.setValue(v);
} finally {
// 通知等待的消费者
System.out.println("EventProducer send success, sequence:"+next);
ringBuffer.publish(next);
}
}
}
测试类
public class DisruptorTest {
public static void main(String[] args) {
// 2的n次方
int bufferSize = 8;
Disruptor<EventData> disruptor = new Disruptor<EventData>(
() -> new EventData(), // 事件工厂
bufferSize, // 环形数组大小
Executors.defaultThreadFactory(), // 线程池工厂
ProducerType.MULTI, // 支持多事件发布者
new BlockingWaitStrategy()); // 等待策略
// 设置消费者
disruptor.handleEventsWithWorkerPool(
new EventConsumer(),
new EventConsumer(),
new EventConsumer(),
new EventConsumer());
disruptor.start();
RingBuffer<EventData> ringBuffer = disruptor.getRingBuffer();
EventProducer eventProducer = new EventProducer(ringBuffer);
long i = 0;
for(;;){
i++;
eventProducer.sendData(i);
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
核心组件
基于上面简单例子来看确实很简单,Disruptor帮我们封装好了生产消费模型的实现,接下来我们来看下他是基于哪些核心组件来支撑起一个高性能无锁队列呢?
RingBuffer: 环形数组,底层使用数组entries,在初始化时填充数组,避免不断新建对象带来的开销。后续只会对entries做更新操作
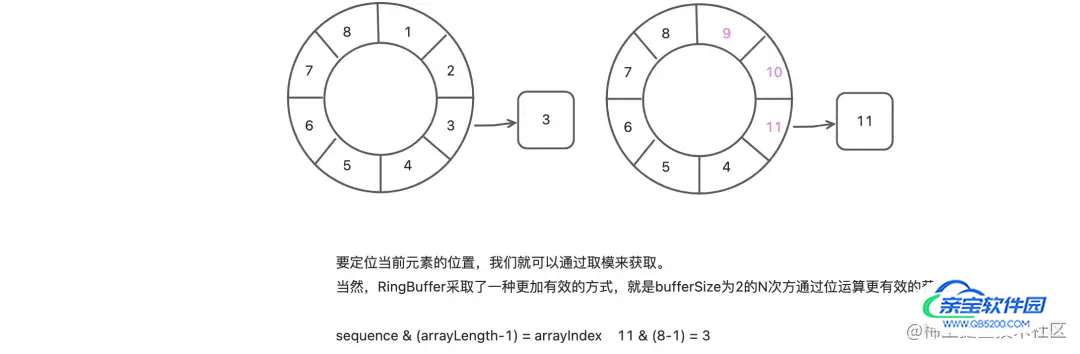

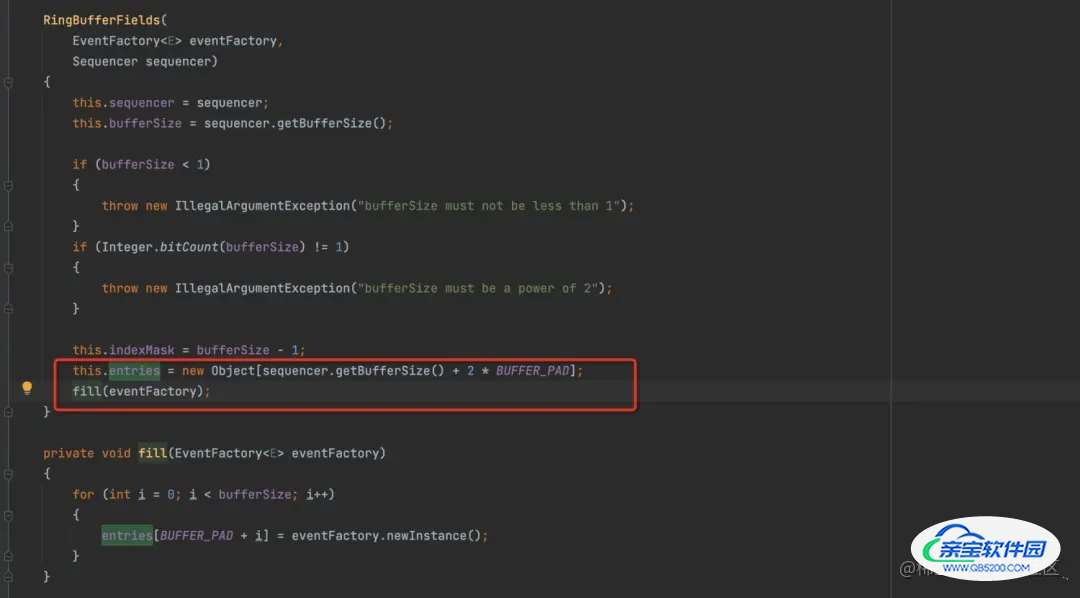
Sequencer: 核心管家
- 定义生产同步的实现:
SingleProducerSequencer单生产、MultiProducerSequencer多生产 - 当前写的进度Sequence cursor
- 所有消费者进度的数组
Sequence[] gatingSequences MultiProducerSequencer可用区availableBuffer【利用空间换取查询效率】
Sequence: 本身就是一个序号器用来标识处理进度,也可以当做是一个atomicInteger; 还有另外一个特点,为了解决伪共享问题而引入的:缓存行填充。这个在后面介绍。
workProcessor: 处理Event的循环,在循环中获取Disruptor的事件,然后把事件分配给各个handler
EventHandler: 负责业务逻辑的handler,自己实现。
WaitStrategy: 消费者 如何等待 事件的策略,定义了如下策略
leepingWaitStrategy:自旋 + yield + sleep
BlockingWaitStrategy:加锁,适合CPU资源紧张(不需要切换线程),系统吞吐量无要求的
YieldingWaitStrategy:自旋 + yield + 自旋
BusySpinWaitStrategy:自旋,减少线程之前切换
PhasedBackoffWaitStrategy:自旋 + yield + 自定义策略
带着问题来解析代码?
1、多生产者如何保证消息生产不会相互覆盖。【如何达到互斥效果】
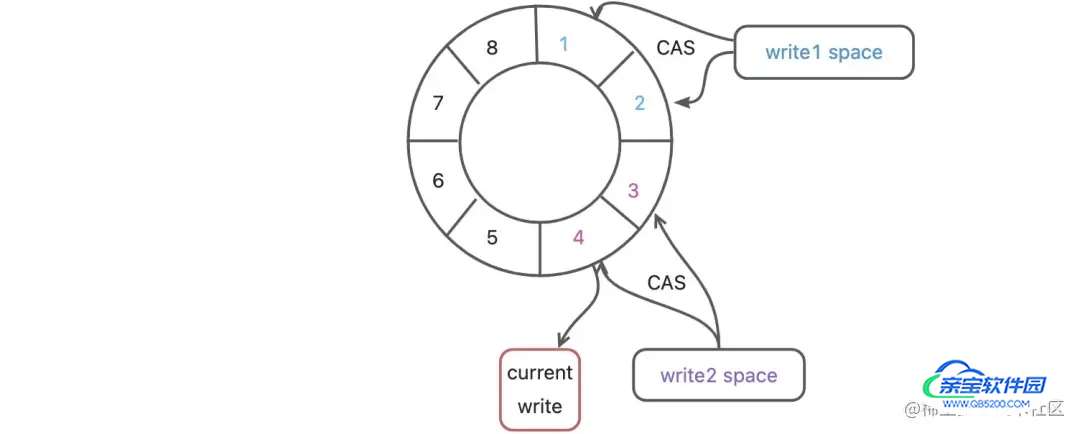
每个线程获取不同的一段数组空间,然后通过CAS判断这段空间是否已经分配出去。
接下来我们看下多生产类MultiProducerSequencer中next方法【获取生产序号】
// 消费者上一次消费的最小序号 // 后续第二点会讲到
private final Sequence gatingSequenceCache = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 当前进度的序号
protected final Sequence cursor = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 所有消费者的序号 //后续第二点会讲到
protected volatile Sequence[] gatingSequences = new Sequence[0];
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
// 当前进度的序号,Sequence的value具有可见性,保证多线程间线程之间能感知到可申请的最新值
current = cursor.get();
// 要申请的序号空间:最大序列号
next = current + n;
long wrapPoint = next - bufferSize;
// 消费者最小序列号
long cachedGatingSequence = gatingSequenceCache.get();
// 大于一圈 || 最小消费序列号>当前进度
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
// 说明大于1圈,并没有多余空间可以申请
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
// 更新最小值到Sequence的value中
gatingSequenceCache.set(gatingSequence);
}
// CAS成功后更新当前Sequence的value
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}
2、生产者向序号器申请写的序号,如序号正在被消费,Sequencer是如何知道哪些序号是可以被写入的呢?【未消费则被覆盖如何处理】
从gatingSequences中取得最小的序号,生产者最多能写到这个序号的后一位。通俗来讲就是申请的序号不能大于最小消费者序号一圈【申请到最大序列号-buffersize 要小于/等于 最小消费的序列号】的时候, 才能申请到当前写的序号
public final EventHandlerGroup<T> handleEventsWithWorkerPool(final WorkHandler<T>... workHandlers)
{
return createWorkerPool(new Sequence[0], workHandlers);
}
EventHandlerGroup<T> createWorkerPool(
final Sequence[] barrierSequences, final WorkHandler<? super T>[] workHandlers)
{
final SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(barrierSequences);
final WorkerPool<T> workerPool = new WorkerPool<>(ringBuffer, sequenceBarrier, exceptionHandler, workHandlers);
consumerRepository.add(workerPool, sequenceBarrier);
final Sequence[] workerSequences = workerPool.getWorkerSequences();
updateGatingSequencesForNextInChain(barrierSequences, workerSequences);
return new EventHandlerGroup<>(this, consumerRepository, workerSequences);
}
private void updateGatingSequencesForNextInChain(final Sequence[] barrierSequences, final Sequence[] processorSequences)
{
if (processorSequences.length > 0)
{
// 消费者启动后就会将所有消费者存放入AbstractSequencer中gatingSequences
ringBuffer.addGatingSequences(processorSequences);
for (final Sequence barrierSequence : barrierSequences)
{
ringBuffer.removeGatingSequence(barrierSequence);
}
consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences);
}
}
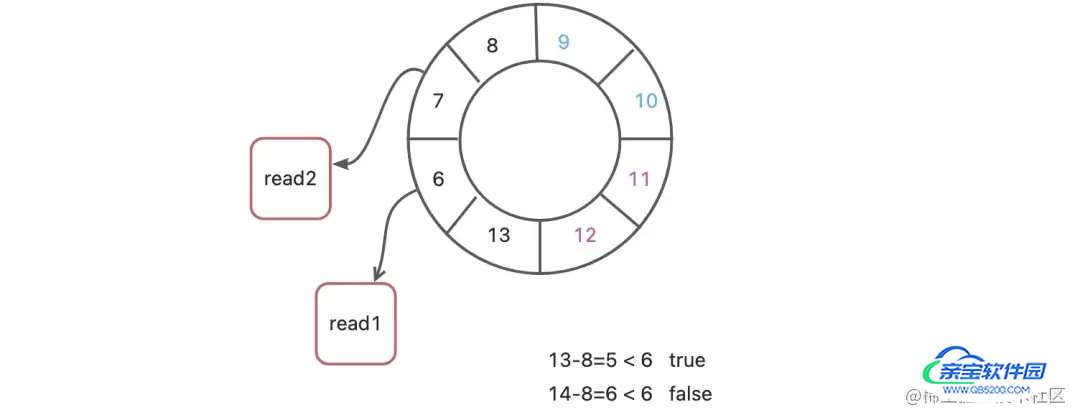
3、在多生产者情况下,生产者是申请到一段可写入的序号,然后再写入这些序号中,那么消费者是如何感知哪些序号是可以被消费的呢?【借问提1图说明】
这个前提是多生产者情况下,第一点我们说过每个线程获取不同的一段数组空间,那么现在单单通过序号已经不够用了,MultiProducerSequencer使用了int 数组 【availableBuffer】来标识当前序号是否可用。当生产者成功生产事件后会将availableBuffer中当前序列号置为1标识可以读取。
如此消费者可以读取的的最大序号就是我们availableBuffer中第一个不可用序号-1。

初始化availableBuffer流程
public MultiProducerSequencer(int bufferSize, final WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
// 初始化可用数组
availableBuffer = new int[bufferSize];
indexMask = bufferSize - 1;
indexShift = Util.log2(bufferSize);
initialiseAvailableBuffer();
}
// 初始化默认availableBuffer为-1
private void initialiseAvailableBuffer()
{
for (int i = availableBuffer.length - 1; i != 0; i--)
{
setAvailableBufferValue(i, -1);
}
setAvailableBufferValue(0, -1);
}
// 生产者成功生产事件将可用区数组置为1
public void publish(final long sequence)
{
setAvailable(sequence);
waitStrategy.signalAllWhenBlocking();
}
private void setAvailableBufferValue(int index, int flag)
{
long bufferAddress = (index * SCALE) + BASE;
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
}
消费者消费流程
WorkProcessor类中消费run方法
public void run()
{
boolean processedSequence = true;
long cachedAvailableSequence = Long.MIN_VALUE;
long nextSequence = sequence.get();
T event = null;
while (true)
{
try
{
// 先通过cas获取消费事件的占有权
if (processedSequence)
{
processedSequence = false;
do
{
nextSequence = workSequence.get() + 1L;
sequence.set(nextSequence - 1L);
}
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));
}
// 数据就绪,可以消费
if (cachedAvailableSequence >= nextSequence)
{
event = ringBuffer.get(nextSequence);
// 触发回调函数
workHandler.onEvent(event);
processedSequence = true;
}
else
{
// 获取可以被读取的下标
cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
// ....省略
}
notifyShutdown();
running.set(false);
}
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
// 这个值获取的current write 下标,可以认为全局消费下标。此处与每一段的write1和write2下标区分开
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
// 通过availableBuffer筛选出第一个不可用序号 -1
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
public long getHighestPublishedSequence(long lowerBound, long availableSequence)
{
// 从current read下标开始, 循环至 current write,如果碰到availableBuffer 为-1 直接返回
for (long sequence = lowerBound; sequence <= availableSequence; sequence++)
{
if (!isAvailable(sequence))
{
return sequence - 1;
}
}
return availableSequence;
}
解决伪共享问题
什么是伪共享问题呢?
为了提高CPU的速度,Cpu有高速缓存Cache,该缓存最小单位为缓存行CacheLine,他是从主内存复制的Cache的最小单位,通常是64字节。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。
伪共享问题是指,当多个线程共享某份数据时,线程1可能拉到线程2的数据在其cache line中,此时线程1修改数据,线程2取其数据时就要重新从内存中拉取,两个线程互相影响,导致数据虽然在cache line中,每次却要去内存中拉取。
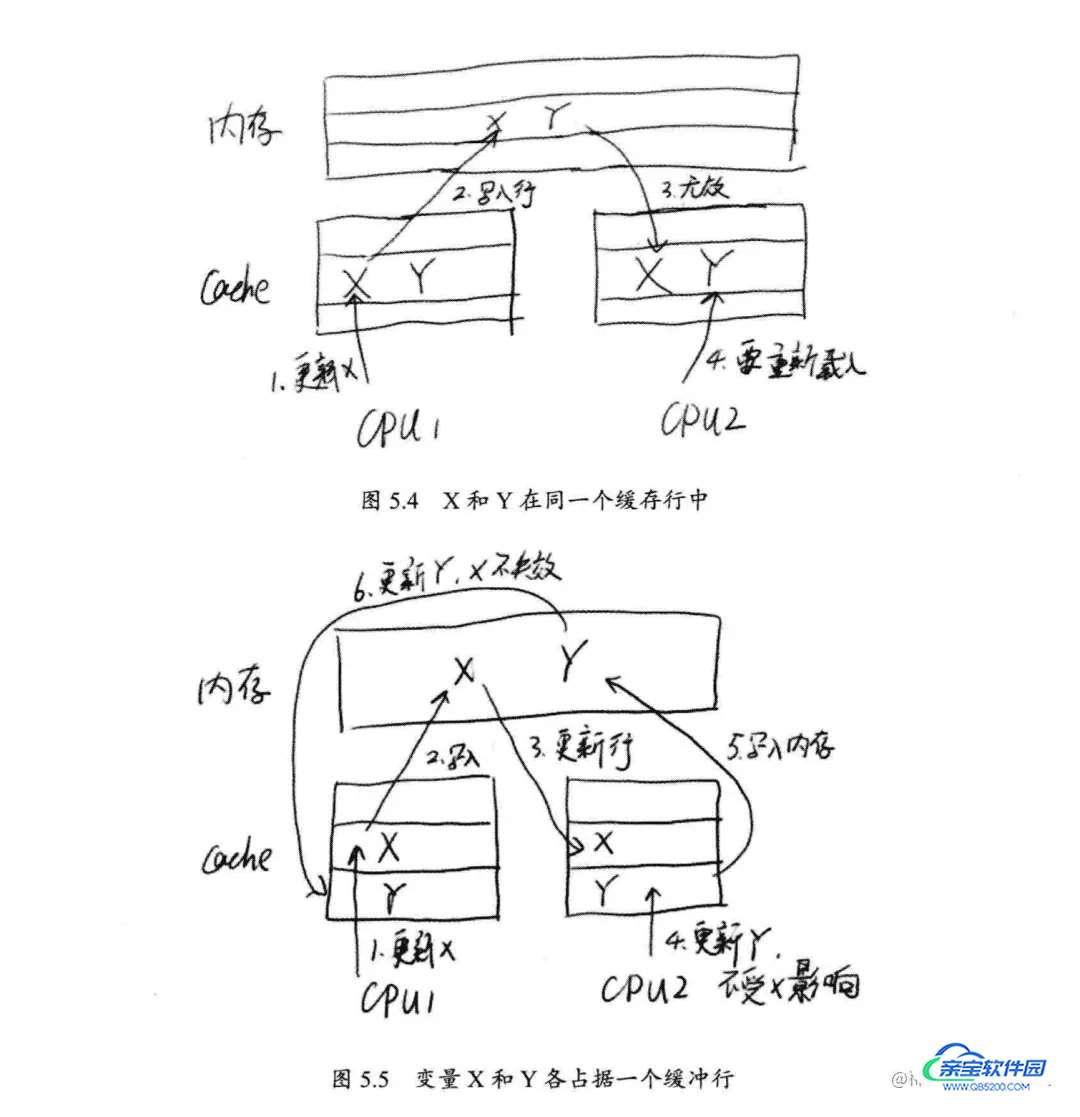
Disruptor是如何解决的呢?
在value前后统一都加入7个Long类型进行填充,线程拉取时,不论如何都会占满整个缓存
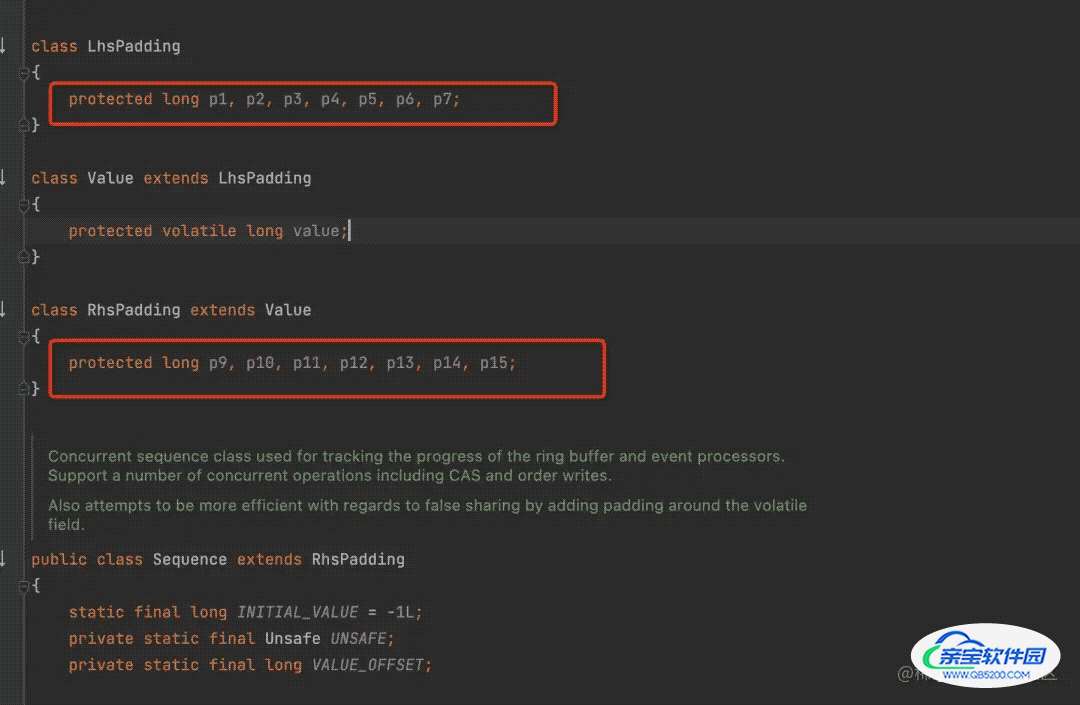
回顾总结:Disuptor为何能称之为高性能的无锁队列框架呢?
- 缓存行填充,避免缓存频繁失效。【java8中也引入
@sun.misc.Contended注解来避免伪共享】 - 无锁竞争:通过CAS 【二阶段提交】
- 环形数组:数据都是覆盖,避免GC
- 底层更多的使用位运算来提升效率
加载全部内容