JDK基于CAS实现原子类盘点解析
JAVA旭阳 人气:0前言
JDK中提供了一系列的基于CAS实现的原子类,CAS 的全称是Compare-And-Swap,底层是lock cmpxchg指令,可以在单核和多核 CPU 下都能够保证比较交换的原子性。所以说,这些原子类都是线程安全的,而且是无锁并发,线程不会频繁上下文切换,所以在某些场景下性能是优于加锁。
本文就盘点一下JDK中的原子类,方便我们后续拿来使用。
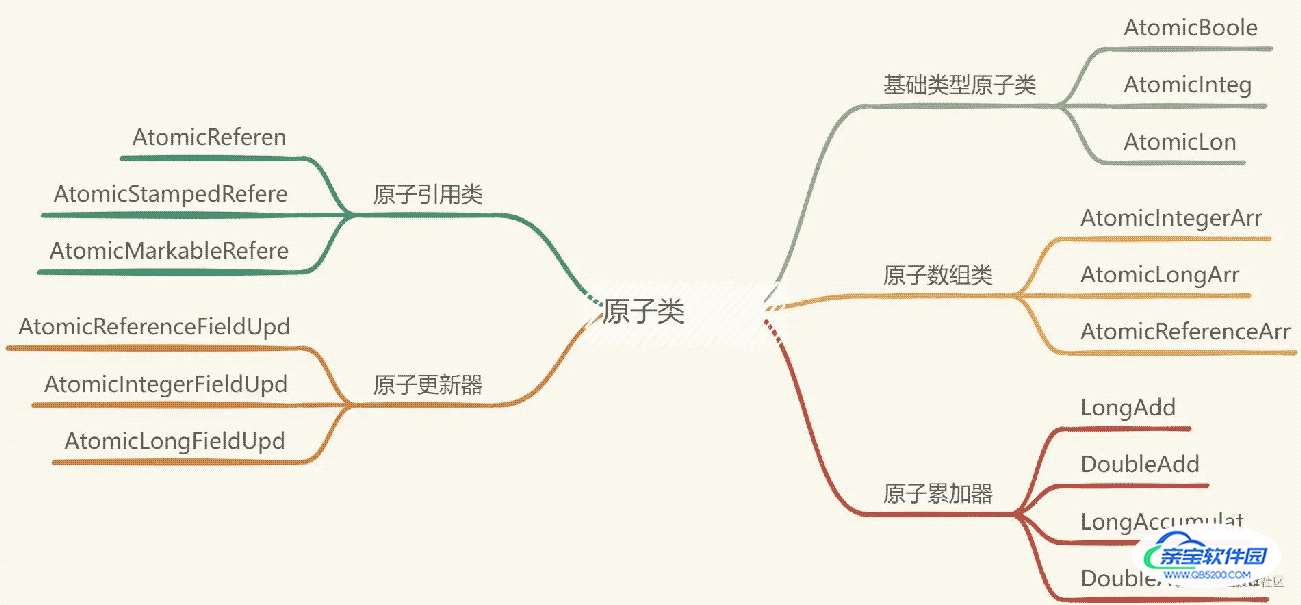
基础原子类
AtomicInteger:Integer整数类型的原子操作类AtomicBoolean:Boolean类型的原子操作类AtomicLong:Long类型的原子操作类
这边以AtomicInteger讲解下它的API和用法。
构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型Integer
常用API:
public final int get(): 获取 AtomicInteger 的值public final int getAndIncrement(): 以原子方式将当前值加 1,返回的是自增前的值public final int incrementAndGet():以原子方式将当前值加 1,返回的是自增后的值public final int getAndSet(int value):以原子方式设置为 newValue 的值,返回旧值public final int addAndGet(int data):以原子方式将输入的数值与实例中的值相加并返回
使用:
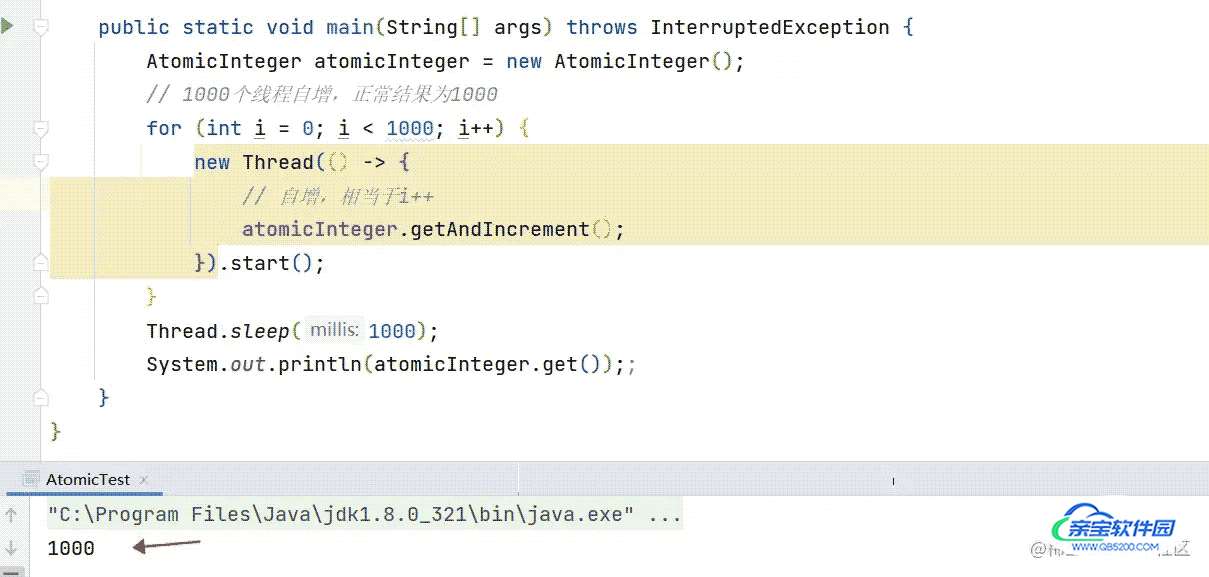
- 结果1000,大致说明并发情况下保证了线程安全
原理分析:
整体实现思路: 自旋(循环) + CAS算法
- 当旧的预期值 A == 内存值 V 此时可以修改,将 V 改为 B
- 当旧的预期值 A != 内存值 V 此时不能修改,并重新获取现在的最新值,重新获取的动作就是自旋
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
valueOffset:偏移量表示该变量值相对于当前对象地址的偏移,Unsafe 就是根据内存偏移地址获取数据
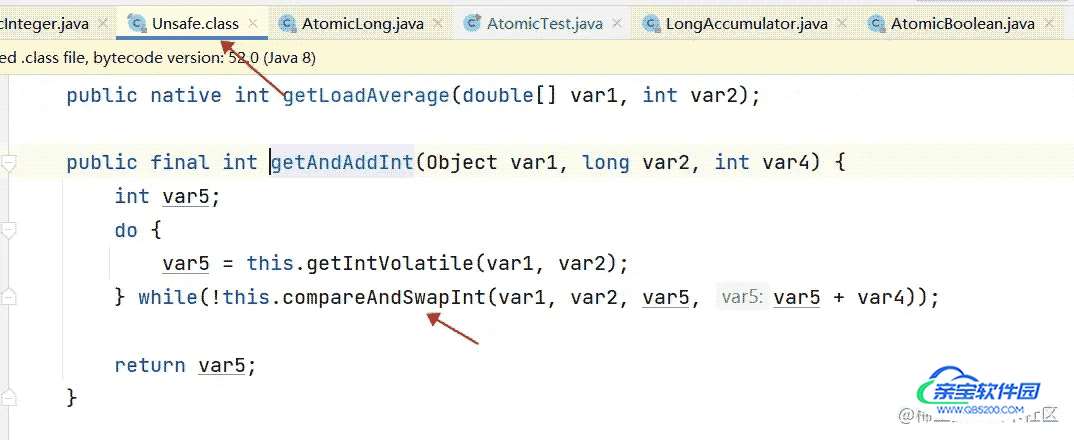
- 从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到本地内存),然后执行
compareAndSwapInt()再和主内存的值进行比较,假设方法返回 false,那么就一直执行 while 方法,直到期望的值和真实值一样,修改数据。

- 原子类
AtomicInteger的value属性是volatile类型,保证了多线程之间的内存可见性,避免线程从工作缓存中获取失效的变量。
原子引用
原子引用主要是对对象的原子操作,原子引用类分为AtomicReference、AtomicStampedReference、AtomicMarkableReference。它们之间有什么区别呢?
- AtomicReference类
普通的原子类对象
public class AtomicReferenceDemo {
public static void main(String[] args) {
User user1 = new User("旭阳");
// 创建原子引用包装类
AtomicReference<User> atomicReference = new AtomicReference<>(user1);
while (true) {
User user2 = new User("alvin");
// 比较并交换
if (atomicReference.compareAndSet(user1, user2)) {
break;
}
}
System.out.println(atomicReference.get());
}
}
@Data
@AllArgsConstructor
@ToString
class User {
private String name;
}
- 调用
compareAndSet()方法进行比较替换对象
ABA问题
但是如果使用AtomicReference类,会有一个ABA问题。什么意思呢?就是一个线程将共享变量从A改成B, 后面又改回A, 这是,另外一个线程就无法感知这个变化过程,就傻傻的比较,就以为没有变化,还是一开始的A,就替换了。 实际的确存在这样只要共享变量发生过变化,就要CAS失败,有什么办法呢?
- AtomicStampedReference类
带版本号的原子类对象
@Slf4j(topic = "a.AtomicStampedReferenceTest")
public class AtomicStampedReferenceTest {
// 构造AtomicStampedReference
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
Thread.sleep(1000);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() throws InterruptedException {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
Thread.sleep(500);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
}
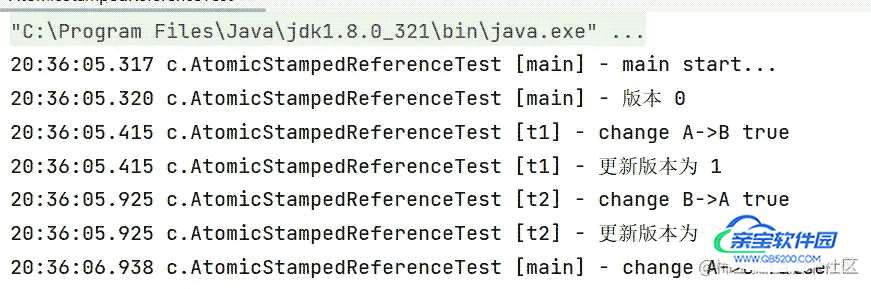
- 虽然对象的值变回了A,但是由于版本变了,所以主线程CAS失败
- AtomicMarkableReference 类
其实有时候并不关心共享变量修改了几次,而是只要标记下是否发生过更改,是否加个标记即可,所以就有了AtomicMarkableReference类。
@Slf4j(topic = "c.AtomicMarkableReferenceTest")
public class AtomicMarkableReferenceTest {
// 构造 AtomicMarkableReference, 初始标记为false
static AtomicMarkableReference<String> ref = new AtomicMarkableReference<>("A", false);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
other();
Thread.sleep(1000);
// 看看是否发生了变化
log.debug("change {}", ref.isMarked());
}
private static void other() throws InterruptedException {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
false, true));
}, "t1").start();
Thread.sleep(500);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
true, true));
}, "t2").start();
}
}

- 通过调用
isMarked()方法查看是否发生变化。
原子数组
AtomicIntegerArray: Integer类型的原子数组AtomicLongArray:Long类型的原子数组AtomicReferenceArray:引用类型的原子数组
直接上例子
public class AtomicIntegerArrayTest {
public static void main(String[] args) throws Exception{
AtomicIntegerArray array = new AtomicIntegerArray(10);
Thread t1 = new Thread(()->{
int index;
for(int i=1; i<100000; i++) {
index = i%10; //范围0~9
array.incrementAndGet(index);
}
});
Thread t2 = new Thread(()->{
int index;
for(int i=1; i<100000; i++) {
index = i%10; //范围0~9
array.decrementAndGet(index);
}
});
t1.start();
t2.start();
Thread.sleep(5 * 1000);
System.out.println(array.toString());
}
}
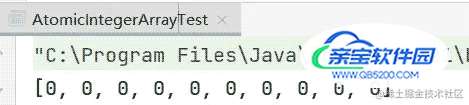
- 两个线程同时对数组对象进行加和减的操作,最终结果都是0,说明线程安全。
原子字段更新器
AtomicReferenceFieldUpdater
AtomicIntegerFieldUpdater
AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常。
@Data
public class AtomicReferenceFieldUpdaterTest {
private volatile int age = 10;
private int age2;
public static void main(String[] args) {
AtomicIntegerFieldUpdater integerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(AtomicReferenceFieldUpdaterTest.class, "age");
AtomicReferenceFieldUpdaterTest ref = new AtomicReferenceFieldUpdaterTest();
// 对volatile 的age字段+1
integerFieldUpdater.getAndIncrement(ref);
System.out.println(ref.getAge());
// 修改 非volatile的age2
integerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(AtomicReferenceFieldUpdaterTest.class, "age2");
integerFieldUpdater.getAndIncrement(ref);
}
}

- 原子字段更新器只能更新
volatile字段,它可以保证可见性,但是无法保证原子性。
原子累加器
原子累加器主要是用来做累加的,相关的类有LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator。
LongAdder是jdk1.8中引入的,它的性能要比AtomicLong方式好。
LongAddr 类是 LongAccumulator 类的一个特例,只是 LongAccumulator 提供了更强大的功能,可以自定义累加规则,当accumulatorFunction 为 null 时就等价于 LongAddr。
这边做个性能的对比例子。
public class LongAdderTest {
public static void main(String[] args) {
System.out.println("LongAdder ...........");
for (int i = 0; i < 5; i++) {
addFunc(() -> new LongAdder(), adder -> adder.increment());
}
System.out.println("AtomicLong ...........");
for (int i = 0; i < 5; i++) {
addFunc(() -> new AtomicLong(), adder -> adder.getAndIncrement());
}
}
private static <T> void addFunc(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
long start = System.nanoTime();
List<Thread> ts = new ArrayList<>();
// 40个线程,每人累加 50 万
for (int i = 0; i < 40; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
ts.forEach(t -> t.start());
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start)/1000_000);
}
}
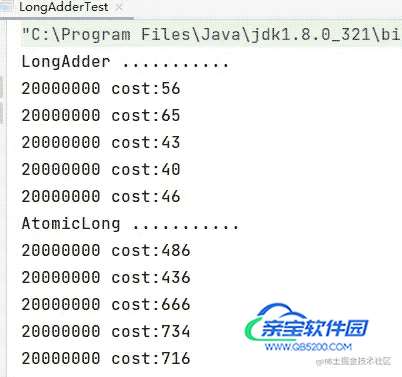
主要是由于LongAdder会设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]... 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
总结
本文总结了JDK中提供的各种原子类,包括基础原子类、原子引用类、原子数组类、原子字段更新器和原子累加器等。有时候,使用这些原子类的性能是比加锁要高的,特别是在读多写少的场景下。但是,不知道大家发现没有,所有的原子类操作对于一个共享变量执行操作是原子的,如果对于多个共享变量操作时,循环 CAS 就无法保证操作的原子性,还是老老实实加锁吧,更多关于JDK CAS原子类的资料请关注其它相关文章!
加载全部内容