redis分布式锁与zk分布式锁的对比分析
进步的每一天 人气:0在分布式环境下,传统的jvm级别的锁会失效,那么分布式锁就是非常有必要的一个技术,一般我们可以通过redis,zk等技术来实现我们的分布式锁
redis实现分布式锁
原理
我们都知道redis的处理读写请求是单线程的,这种情况就不会发生并发的问题,其实实现起来很简单,就是使用redis的 setnx 命令实现,该命令如果redis中存在当前key,就会返回0,否者插入成功。
那么就可以获取锁的时候添加一个k-v值(任意的一个值)到redis,释放锁的时候就删除,这样就使用redis实现了一个分布式锁,相当于分布式中所谓的锁概念其实就相当一个redis或者zk中的一个值,有这个值就加锁成功
能实现的锁类型
1、普通的锁
2、读写锁:大致就是给当前的key设置一个特定的值标识当前锁是读锁还是写锁,读与读之间不互斥,相当与就是没有锁,读与写,写于写之间进行互斥,这个锁的目的是为了解决缓存一致性的问题,这个问题下面来分析
3、红锁:底层原理涉及到redis半数写入机制,针对主从架构中主节点挂了但是数据还未同步到从节点的问题,实现的方式就是当一半以上的节点都写入成功了才返回给客户端成功的提示,而不是主节点写入成功就返回,但是这种情况下的效率比较慢
注意事项
1、死锁的情况:出现死锁的情况有以下几种情
(1)应用程序没有正常的释放锁:比如程序抛出异常之类导致释放锁代码没有执行;
解决方案:需要把释放锁的代码写在finally模块里面。
(2)锁还没有释放redis宕机:这个时候本来应该删除的key因为redis服务停掉了导致删除不成功,出现死锁的问题
解决方案:给每一个key设置一个超时时间,超时了自动清除。
2、锁永久失效的情况:出现原因是因为当前线程A还没有运行完然后锁因为过期时间的原因自动删除了,这个时候其他线程B又能拿到这个锁在redis中创建一个对应的k-v值,然后线程A执行到释放锁的时候会删除掉对应key的值,这个时候删除的值是线程B对应的锁,而不是线程A的,这样在高并发的情况下就有可能导致锁压根不生效
解决方案:在进行设值的时候,value值设置成能标识当前线程的一个值,比如在当前线程中创建一个uuid,然后在释放锁的时候也要比较value值,相同的情况就表示是当前线程对应的锁,允许释放,否则不允许释放。
3、会存在锁提前释放的问题:当然这个问题也是引起上面第2个问题的根本原因,但是解决方案是不一样的
解决方案:在获得锁之后,处理业务逻辑的过程中,新建一个timer来定时的去重置锁的生命周期,当然前提是当前业务逻辑还在执行,这个定时的频率一般设置为锁生命周期的1/3,redisson中的 **看门狗 **其实内部就是这样实现。
4、主从结构中锁丢失:上面 红锁 已经说明了情况
zk实现分布式锁
原理
zk实现分布式锁的原理其实和redis很像,都是往里面插入对应的值,通过zk的create命令来实现,zk中的值是通过树形结构,类似与文件夹的层级目录一样,如果当前节点存在那么create命令就会执行失败,这种情况就代表其他的线程已经获取到了锁,当前线程通过get -w /xxx的命令对当前锁进行监听,如果当前锁被其他线程释放,那么当前线程会重新参与竞争锁
能实现的锁类型
1、非公平锁:就是通过create创建节点,谁创建成功谁就获得了锁,其他锁对这个节点进行监听,当释放锁的时候,所有线程又来竞争这个锁,但是这种情况会引发羊群效应,就是当一个节点被释放的时候所有的线程都会来竞争,浪费性能
2、公平锁:通过zk的临时有序节点来实现,当前线程创建一个临时顺序节点,然后判断当前节点是不是最小的节点,如果时就获得锁,如果不是那么就监听他的上一个节点,等到释放锁的时候会通知后一个节点,然后重复以上判断,这个就是公平锁的实现方案,这样就可以避免羊群效应,减轻服务器的压力,但是这种情况可能会发生幽灵节点的产生导致死锁
幽灵节点:就是客户端发送创建命令之后,zk已经成功创建,但是在响应的时候发生了宕机,这个时候客户端以为没有成功,但是服务器端实际上已经有了,但是这个客户端不知道,就不会去释放,就造成了幽灵节点,通过 Protection模式能够避免这个问题,这个的本质就是在节点前面加上一个唯一的标识,如uuid,人客户端再次请求的时候会比较这个uuid,如果有就认为创建成功了,使用curator的protection模式原理就是这样的,一下附一张公平锁实现原理图:

3、读写锁:实现原理和公平锁差不多,只是在创建每一个节点的时候标识当前节点时读锁(加read标识)还是写锁(加write标识)
两种锁的对比
分布式系统中通常要考虑CAP的,一致性,可用性和分区容错性,很多场景下是很难同时保证CAP的,这个时候就得做出取舍,分布式锁也是这样的。
redis分布式锁:
- 优点:性能高,能保证AP,保证其高可用,
- 缺点:但是不能保证其一致性,原因就是在redis集群+主从的结构中,数据是通过分片存储的,但是这个时候当一个master节点挂了之后,slave节点还未同步到master节点的数据,导致数据丢失,万一丢失的数据刚好是你的锁,那么就有可能造成并发问题,所以不能保证强一致性,这种情况下可以通过redisson的红锁来解决,解决的原理其实就是redis的半数写入机制,但是这样完全降低了redis的性能,所以一般情况下是不采用的,zk其实能保证其一致性的原因就是其半数写入机制加上其 leader选举的逻辑实现
zk分布式锁:
- 优点:能够保证其一致性,每个节点的创建都会同时写入leader和follwer节点,半数以上写入成功才返回,如果leader节点挂了之后选举的流程会优先选举zxid(事务Id)最大的节点,就是选数据最全的,又因为半数写入的机制这样就不会导致丢数据(ZAB协议)
- 缺点:性能没有redis高
以上已经说明了两种分布式锁实现的方式及其原理,怎么选择以实际业务为准
缓存一致性:数据库于缓存的结果不一样
双写一致性问题(图网上找的,懒得画了)

读写一致性问题
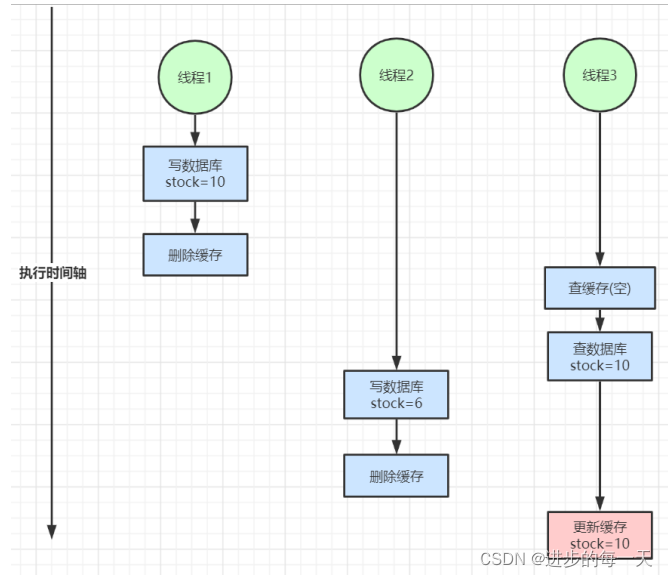
解决方案:
(1)对于我们的用户自己的订单数据,或者用户信息数据,或者说高并发场景下能容忍短时间的数据不一致,这些都可以采用添加过期时间(本来进入到缓存的数据就不要求强一致性,这种方式能解决大多数的情况,这种方式比较推荐也最常用)
(2)延迟双删:就是在更新了数据库之后等一小段时间再删除缓存(这种的缺点就是对于非高并发的请求,出现缓存一致性的问题概率本来就不大,但是却人为的降低了代码的性能)
(3)采用我们redis提供的分布式读写锁,读读之间不阻塞,一旦有数据更新那么读的操作就阻塞,等待更新+删除缓存的操作结束之后再进行读,这个情况虽然能真正的保证数据的一致性,但是加锁了之后会进行阻塞,高并发情况下的性能就降低了
(4)使用阿里巴巴的cannal组件,类似于一个mysql的slave节点,监听着mysql的binlog日志文件,有变化就会主动的通知我们(推荐)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容