云服务器(Linux)安装部署Kafka的详细过程
shadc 人气:0云服务器(Linux)安装部署Kafka
前期准备
kafka的安装需要依赖于jdk,需要在服务器上提前安装好该环境,这里使用用jdk1.8。
下载安装包
官网地址:
较新的版本已自带Zookeeper,无需额外下载。这里使用3.2.0做演示。
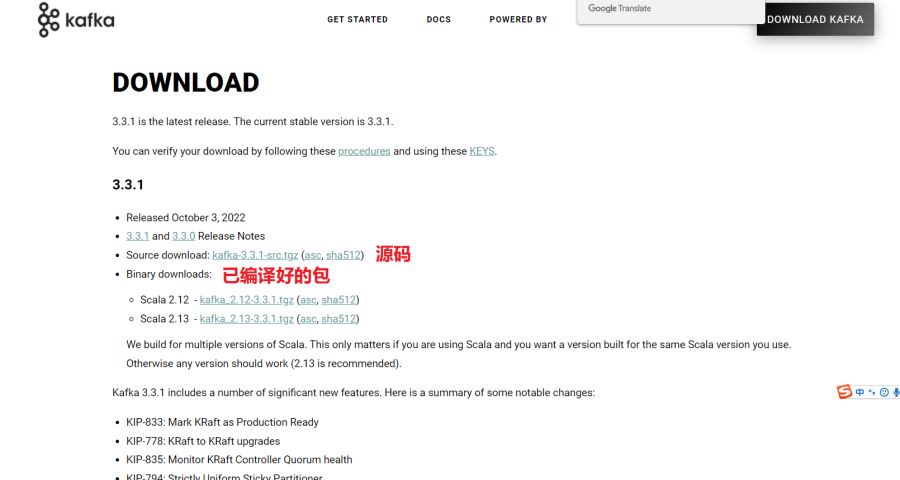
注意要下载Binary downloads标签下的tgz包,Source download标签下的包为源码。无法直接运行,需要编译。
上载安装包到云服务器
使用ssh连接工具将kafka_2.12-3.2.0.tgz这个包上传到云服务器上的一个目录。
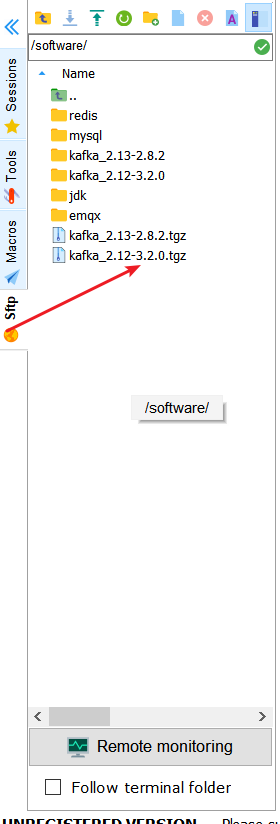
打开命令行,进入到放有压缩包的目录,执行
tar -zxvf kafka_2.12-3.2.0.tgz
配置kafka
然后使用cd命令进入到/kafka_2.12-3.2.0/config/下,使用
vi server.properties
编辑配置文件。

删除listeners和advertised前方的#号,改成如下配置:
listeners=PLAINTEXT://云服务器内网ip:9092(本地访问用本地ip) # 如果要提供外网访问则必须配置此项 advertised.listeners=PLAINTEXT://云服务器公网ip:9092(若要远程访问需配置此项为云服务器的公网ip) # zookeeper连接地址,集群配置格式为ip:port,ip:port,ip:port zookeeper.connect=云服务器公网ip:2181
开放云服务器端口
在云服务器控制台内进入安全组页面,添加两条新的入站规则,tcp/9092和tcp/2181
开放linux防火墙端口
先查看使用的防火墙类型iptables/firewalld
iptables操作命令
1.打开/关闭/重启防火墙 开启防火墙(重启后永久生效):chkconfig iptables on 关闭防火墙(重启后永久生效):chkconfig iptables off 开启防火墙(即时生效,重启后失效):service iptables start 关闭防火墙(即时生效,重启后失效):service iptables stop 重启防火墙:service iptables restartd 2.查看打开的端口 /etc/init.d/iptables status 3.开启端口 iptables -A INPUT -p tcp --dport 8080 -j ACCEPT 4.保存并重启防火墙 /etc/rc.d/init.d/iptables save /etc/init.d/iptables restart
Centos7默认安装了firewalld,如果没有安装的话,可以使用 yum install firewalld firewalld-config进行安装。
操作指令如下:
1.启动防火墙 systemctl start firewalld 2.禁用防火墙 systemctl stop firewalld 3.设置开机启动 systemctl enable firewalld 4.停止并禁用开机启动 sytemctl disable firewalld 5.重启防火墙 firewall-cmd --reload 6.查看状态 systemctl status firewalld或者 firewall-cmd --state 7.在指定区域打开端口(记得重启防火墙) firewall-cmd --zone=public --add-port=80/tcp(永久生效再加上 --permanent)
打开tcp/9092和tcp/2181这两个端口后,重启防火墙,并查看开放的端口确实生效。
启动kafka服务
cd命令进入kafka_2.12-3.2.0目录下,执行
bin/zookeeper-server-start.sh config/zookeeper.properties
启动zookeeper,不加-daemon方便排除启动错误,新建一个shell窗口,进入该目录再执行
bin/kafka-server-start.sh config/server.properties
启动kafka,若打印日志未报错,若未出现error日志,说明启动成功。
测试单机连通性
查询kafka下所有的topic bin/kafka-topics.sh --list --zookeeper ip:port 因为kafka使用zookeeper作为配置中心,一些topic信息需要查询该kafka对应的zookeeper 创建topic bin/kafka-topics.sh --create --zookeeper ip:port --replication-factor 1 --partitions 1 --topic test 开启生产者 bin/kafka-console-producer.sh --broker-list cos100:9092 --topic test 开启消费者 bin/kafka-console-consumer.sh --bootstrap-server cos100:9092 --topic test
Springboot连接kafak
在pom.xml文件中引入kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>在application.yml配置文件中配置kafka
server:
port: 8080
spring:
kafka:
bootstrap-servers: 云服务器外网ip地址:9092
producer: # 生产者
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate生产者
@RestController
public class KafkaController {
private final static String TOPIC_NAME = "test-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public String send(@RequestParam("msg") String msg) {
kafkaTemplate.send(TOPIC_NAME, "key", msg);
return String.format("消息 %s 发送成功!", msg);
}
}消费者
@Component
public class DemoConsumer {
/**
* @param record record
* @KafkaListener(groupId = "testGroup", topicPartitions = {
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* //concurrency就是同组下的消费者个数,就是并发消费数,必须小于等于分区总数
*/
@KafkaListener(topics = "test-topic", groupId = "testGroup1")
public void listentestGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println("testGroup1 message: " + value);
System.out.println("testGroup1 record: " + record);
//手动提交offset,一般是提交一个banch,幂等性防止重复消息
// === 每条消费完确认性能不好!
ack.acknowledge();
}
//配置多个消费组
@KafkaListener(topics = "test--topic", groupId = "testGroup2")
public void listentestGroup2(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println("testGroup2 message: " + value);
System.out.println("testGroup2 record: " + record);
//手动提交offset
ack.acknowledge();
}
}使用swagger测试发送消息
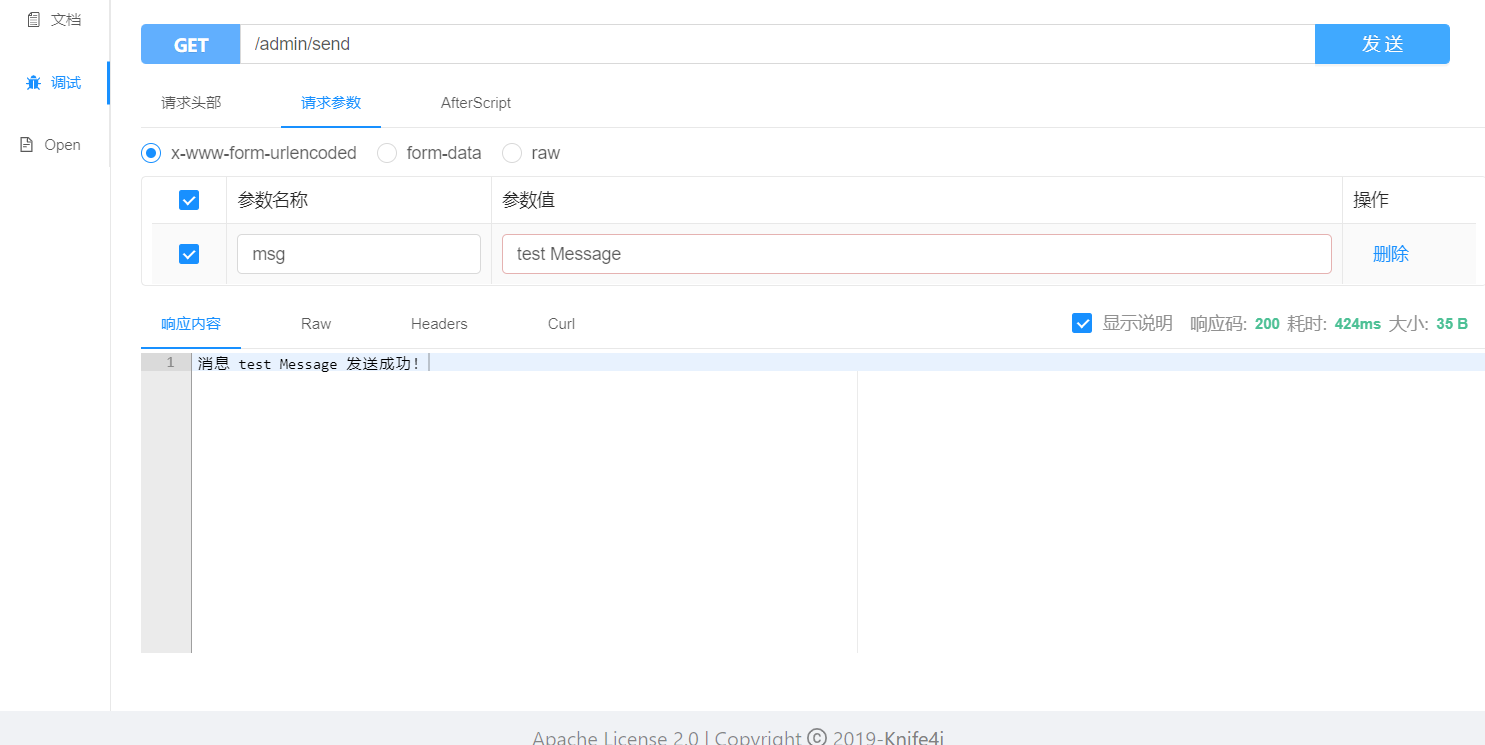
控制台打印消息

加载全部内容