MySQL 开窗函数
人气:0结合order by关键词和limit关键词是可以解决很多的topN问题,比如从二手房数据集中查询出某个地区的最贵的10套房,从电商交易数据集中查询出实付金额最高的5笔交易,从学员信息表中查询出年龄最小的3个学员等。但是,如果需求变成从二手房数据集中查询出各个地区最贵的10套房,从电商数据集中查询出每月实付金额最高的5笔交易,从学员信息表中查询出各个科系下年龄最小的3个学员,该如何解决呢?
其实这类问题的核心就是,筛选出组内的topN,而不是从全部数据集中挑选出topN。遇到这种既需要分组也需要排序的问题,直接上开窗函数就能解决了。
(1)开窗函数的定义
开窗函数也叫OLAP函数(Online Analytical Processing,联机分析处理),主要用来实时分析处理数据。MySQL之前的版本是不支持开窗函数的,从8.0版本之后开始支持开窗函数。
# 开窗函数语法 func_name(<parameter>) OVER([PARTITION BY <part_by_condition>] [ORDER BY <order_by_list> ASC|DESC])
开窗函数语句解析:
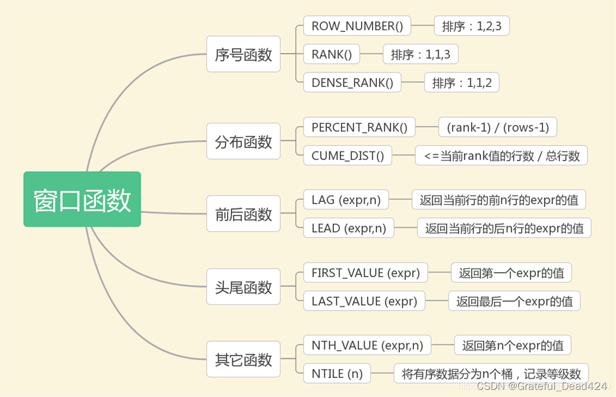
函数分为两部分,一部分是函数名称,开窗函数的数量比较少,总共才11个开窗函数+聚合函数(所有的聚合函数都可以用作开窗函数)。根据函数的性质,有的需要写参数,有的不需要写参数。
另一部分为over语句,over()是必须要写的,里面的参数都是非必须参数,可以根据需求有选择地使用:
- 第一个参数是partition by + 字段,含义是根据此字段将数据集分为多份
- 第二个参数是order by + 字段,每个窗口的数据依据此字段进行升序或降序排列
开窗函数与分组聚合函数比较相似,都是通过指定字段将数据分成多份,区别在于:
- SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数。
- 聚合函数每组只返回一个值,开窗函数每组可返回多个值。
在这11个开窗函数中,实际工作中用的最多的当属ROW_NUMBER()、RANK()、DENSE_RANK()这三个排序函数了。下面我们通过一个简单的数据集学习一下这三个开窗函数。
# 首先创建虚拟的业务员销售数据
CREATE TABLE Sales
(
idate date,
iname char(2),
sales int
);
# 向表中插入数据
INSERT INTO Sales VALUES
('2021/1/1', '丁一', 200),
('2021/2/1', '丁一', 180),
('2021/2/1', '李四', 100),
('2021/3/1', '李四', 150),
('2021/2/1', '刘猛', 180),
('2021/3/1', '刘猛', 150),
('2021/1/1', '王二', 200),
('2021/2/1', '王二', 180),
('2021/3/1', '王二', 300),
('2021/1/1', '张三', 300),
('2021/2/1', '张三', 280),
('2021/3/1', '张三', 280);
# 数据查询
SELECT * FROM Sales;
# 查询各月中销售业绩最差的业务员
SELECT month(idate),iname,sales,
ROW_NUMBER()
OVER(PARTITION BY month(idate)
ORDER BY sales) as sales_order
FROM Sales;
SELECT * FROM
(SELECT month(idate),iname,sales,
ROW_NUMBER()
OVER(PARTITION BY month(idate)
ORDER BY sales) as sales_order FROM Sales) as t
WHERE sales_order=1;

# ROW_NUMBER()、RANK()、DENSE_RANK()的区别 SELECT * FROM (SELECT month(idate) as imonth,iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as row_order, RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as rank_order, DENSE_RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as dense_order FROM Sales) as t;
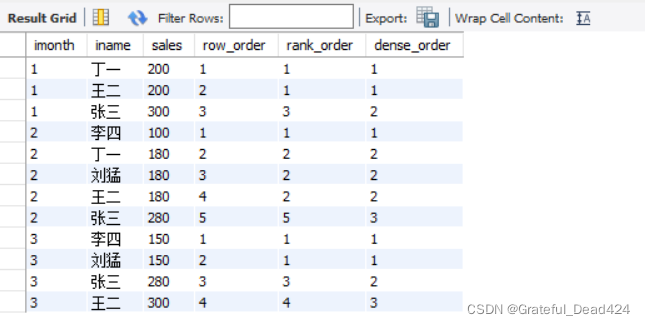
ROW_NUMBER():顺序排序——1、2、3
RANK():并列排序,跳过重复序号——1、1、3
DENSE_RANK():并列排序,不跳过重复序号——1、1、2
(2)开窗函数的实际应用场景
在实际工作或者面试中,可能会遇到求用户连续登录天数、连续签到天数等问题。下面就提供一个用开窗函数解决此类问题的思路。
# 首先创建虚拟的用户登录表,并插入数据 create table user_login ( user_id varchar(100), login_time datetime ); insert into user_login values (1,'2020-11-25 13:21:12'), (1,'2020-11-24 13:15:22'), (1,'2020-11-24 10:30:15'), (1,'2020-11-24 09:18:27'), (1,'2020-11-23 07:43:54'), (1,'2020-11-10 09:48:36'), (1,'2020-11-09 03:30:22'), (1,'2020-11-01 15:28:29'), (1,'2020-10-31 09:37:45'), (2,'2020-11-25 13:54:40'), (2,'2020-11-24 13:22:32'), (2,'2020-11-23 10:55:52'), (2,'2020-11-22 06:30:09'), (2,'2020-11-21 08:33:15'), (2,'2020-11-20 05:38:18'), (2,'2020-11-19 09:21:42'), (2,'2020-11-02 00:19:38'), (2,'2020-11-01 09:03:11'), (2,'2020-10-31 07:44:55'), (2,'2020-10-30 08:56:33'), (2,'2020-10-29 09:30:28'); # 查看数据 SELECT * FROM user_login;
计算连续登录天数通常会有以下三种情况:
- 查看每位用户连续登录的情况
- 查看每位用户最大连续登录的天数
- 查看在某个时间段里连续登录天数超过N天的用户
针对第一种情况:查看每位用户连续登录的情况
根据实际经验,我们知道在一段时间内,用户可能出现多次连续登录,这些信息我们都要输出,所以最后结果输出的字段可以是用户ID、首次登录日期、结束登录日期、连续登录天数这四个。
# 数据预处理:由于统计的窗口期是天数,所以可以对登录时间字段进行格式转换,将其变成日期格式然后再去重(去掉用户同一天内多次登录的情况)
# 为方便后续代码查看,将处理结果放置新表中,一步一步操作
create table user_login_date(
select distinct user_id, date(login_time) login_date from user_login);
# 处理后的数据如下:
select * from user_login_date;
# 第一种情况:查看每位用户连续登陆的情况
# 对用户登录数据进行排序
create table user_login_date_1(
select *,
rank() over(partition by user_id order by login_date) irank
from user_login_date);
#查看结果
select * from user_login_date_1;
# 增加辅助列,帮助判断用户是否连续登录
create table user_login_date_2(
select *,
date_sub(login_date, interval irank DAY) idate #data_sub从指定的日期减去指定的时间间隔
from user_login_date_1);
# 查看结果
select * from user_login_date_2;
# 计算每位用户连续登录天数
select user_id,
min(login_date) as start_date,
max(login_date) as end_date,
count(login_date) as days
from user_login_date_2
group by user_id,idate;
# ===============【整合代码,解决用户连续登录问题】===================
select user_id,
min(login_date) start_date,
max(login_date) end_date,
count(login_date) days
from (select *,date_sub(login_date, interval irank day) idate
from (select *,rank() over(partition by user_id order by login_date) irank
from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c
group by user_id,idate;
针对第二种情况:查看每位用户最大连续登录的天数
# 计算每个用户最大连续登录天数 select user_id,max(days) from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate) as d group by user_id;
针对第三种情况:查看在某个时间段里连续登录天数超过N天的用户
假如说,我们的需求是查看10/29-11/25在这段时间内连续登录天数≥5天的用户。这个需求也可以用第一种情况查询的结果进行筛选。
# 查看在这段时间内连续登录天数≥5天的用户 select distinct user_id from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate having days>=5 ) as d;
这种写法是可以得出结果,但是针对这个问题来说有点麻烦了,下面介绍一个简单的方法:引用一个新的静态窗口函数lead()
select *, lead(login_date,4) over(partition by user_id order by login_date) as idate5 from user_login_date;
lead函数有三个参数,第一个参数是指定的列(这里用登陆日期),第二个参数是当前行向后几行的值,这里用的是4,也就是第五次登录的日期,第三个参数是如果返回的空值可以用指定值替代,这里没有使用第三个参数。 over语句里面是针对user_id分窗,每个窗口针对登录日期升序。
用第五次登录日期 - login_date+1,如果等于5,说明是连续登录五天的,如果得到空值或者大于5,说明没有连续登录五天,代码和结果如下:
# 计算第5次登录日期与当天的差值 select *,datediff(idate5,login_date)+1 days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_login_date) as a; # 找出相差天数为5的记录 select distinct user_id from (select *,datediff(idate5,login_date)+1 as days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_logrin_date) as a)as b where days = 5;
【练习】美团外卖平台数据分析面试题——SQL
现有交易数据表user_goods_table如下:

现在老板想知道每个用户购买的外卖品类偏好分布,并找出每个用户购买最多的外卖品类是哪个。
# 分析题目:要求输出字段为用户名user_name,该用户购买最多的外卖品类goods_kind # 解题思路:这是一个分组排序的问题,可以考虑窗口函数 # 第一步:使用窗口函数row_number(),对每个用户购买的外卖品类进行分组统计与排名 select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind; # 第二步:筛选出每个用户排名第一的外卖品类 select user_id,goods_kind from (select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind) as a where irank=1
加载全部内容